Einführung
1
Frames in MPEG
- Intra-Frames
- Selbstständige Bilder
- I-Frame
- D-Frame
- Selbstständige Bilder
- Inter-Frames
- P-Frame
- B-Frame
2
auto
Wie in den Lerneinheiten Bewegungsschätzung und -kompensation und MPEG Videokodierungsprinzip beschrieben, werden bei MPEG Video nicht alle Bilder einer Videosequenz als Einzelbilder kodiert, sondern es werden mit Hilfe des Blockmatchingverfahrens (siehe Bewegungsschätzung und -kompensation) nur die bildinhaltlichen Änderungen bezogen auf ein Referenzbild kodiert. Als Referenzbilder können vorhergehende, aber auch nachfolgende Bilder in der Videosequenz gewählt werden. Im MPEG Standard sind nun verschiedene Typen von Frames definiert.
Frames in MPEG
MPEG unterscheidet Intra-Frames und Interframes .
Intra-Frames
Selbständige Bilder. Zur Anzeige eines Intra-Frame benötigt man kein Referenzbild. Eine spezielle Form eines I-Frames ist das D-Frame.
Inter-Frames
Inter-Frames sind ohne Kenntnis des Referenzbildes nicht anzeigbar, da in ihnen nur Differenzwerte zu einem Referenzbild angegeben sind. Je nachdem, ob sich das Interframe auf ein vorhergehendes oder auf ein nachfolgendes Bild in der Videosequenz bezieht, unterscheidet MPEG zwischen zwei Typen von Interframes
- P-Frames – prediction Frame. Referenzbild befindet sich in der Videosequenz vor dem Bild
- B-Frames – bidirectional Frame. Ein B-Frame bezieht sich sowohl auf ein vorhergehendes wie auch auf ein nachfolgendes Bild in der GOP.
I-Frames und P-Frames
1
I-Frame
- I steht für Intra-Frame
- Sind selbstständige Bilder
- Kompressionsverhalten
- 10:1 bis 20:1
- Wichtig für
- random access
- fast forward und rewind
- Editierbarkeit
P-Frame
- P steht für Prediction
- Keine selbstständiges Bild, beinhaltet nur Informationen über Änderungen gegenüber vorhergehendem Referenzbild
- Referenzbilder können I oder P-Frames sein
- Für jeden Makroblock enthält P-Frame
- Bewegungsvektor
- Prädiktionsfehler
- Kompressionsverhalten
- 20:1 bis 30:1
2
I-Frames
I-Frames in einer Videosequenz sind selbstständige Bilder. In ihnen ist die gesamte Bildinformation enthalten
Kodiert werden sie ähnlich wie JPEG. Sie weisen nur mäßige Kompression auf. Dadurch, dass sie die gesamte Information eines Bildes beinhalten, sind sie der einzige Bildtyp, auf den ohne Umwege zugegriffen werden kann. Dies ist für Features wie random access, fast forward, fast rewind, reverse playback und die Editierbarkeit des komprimierten Datenstroms notwendig.
- Kompressionsverhalten
- 10:1 bis 20:1 reyn2004
P-Frames
Das P steht für das englische Wort „Prediction“.
Bei einem Prediction-Frame handelt es sich nicht um ein selbstständiges Bild. Es beinhaltet lediglich Informationen, mit deren Hilfe man aus dem unmittelbar vorhergehenden Referenzbild das Originalbild rekonstruieren kann. Referenzbilder können dabei I-Frames oder ein vorhergehendes P-Frame sein.
Informationsgehalt P-Frame
In einem P-Frame sind für jeden Makroblock Bewegungsvektor und Prädiktionsfehler angegeben.
Kodierung
Da der Prädiktionsfehler ein Bild ist , kann ein P-Frame auch wie ein Bild kodiert werden. Zusätzlich muss allerdings für jeden Makrobild der Bewegungsvektor in die Kodierung mit einbezogen werden. reyn2004
- Kompressionsverhalten
- 20:1 bis 30:1
B-Frames
1
Rückwärts/Vorwärts Prädiktion
- B steht für Bidirectional
- Keine selbständiges Bild, beinhaltet nur Informationen über Änderungen gegenüber vorhergehendem und/oder nachfolgendem Referenzbild
- Referenzbilder können I oder P-Frames sein
- Für jeden Makroblock enthält P-Frame
Erzeugung B-Frame
- Für jeden Makroblock kann aus drei Varianten der Prädiktion gewählt
werden
- Makroblock wird aus vorhergehendem Referenzbild prädiziert
- Makroblock wird aus nachfolgendem Referenzbild prädiziert
- Makroblock des B-Frames ergibt sich aus dem Mittelwert der beiden gefundenen Makroblöcke in den beiden Referenzbilder
Auswahl einer Variante PC
- es wird jene Variante gewählt, die beste Kompression verspricht
- Kompressionsverhalten - 30:1 bis 50:1
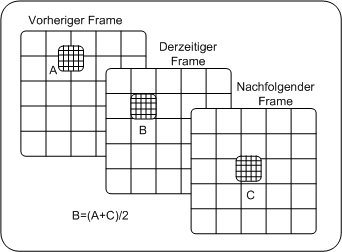
uswahl einer Variante PDA_Phone
- es wird jene Variante gewählt, die beste Kompression verspricht
- Kompressionsverhalten - 30:1 bis 50:1
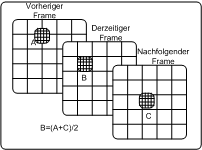
2
Rückwärts/Vorwärts Prädiktion stru2002, 156
B steht für „Bidirectional“.
Bei der bidirektionalen Kodierung verwendet man nicht nur das vorhergehende, sondern auch das nachfolgende Bild als Referenzbild. Als Referenzbilder sind I und P Frames möglich, nicht aber B-Frames.
Bei der Rückwärtsprädiktion verwendet man genau die gleichen Allgorithmen wie bei der Vorwärtsprädiktion.
Die Rückwärtsprädiktion bringt zum Beispiel dort einen Vorteil, wo im Originalbild Dinge sichtbar werden, die im vorhergehenden Bild noch verdeckt waren und daher durch Bewegungskompensation nicht prädiziert werden können. Im Bild, welches dem Originalbild unmittelbar folgt sind diese Dinge gewöhnlich sichtbar und können daher deren Position für das Originalbild prädizieren. In diesem Fall ergibt sich bei Rückwärtsprädiktion ein kleinerer Prädiktionsfehler und damit einhergehend eine wesentlich effektivere Kompression.
Erzeugung B-Frame
Zur Erzeugung eines B-Frames werden sowohl die Bewegungsvektoren, die sich auf das vorangegangene Bild beziehen als auch jene, die sich auf das nachfolgende Bild beziehen, berechnet. Für jeden Block im Originalbild gibt es jetzt 2 Bewegungsvektoren. In einer weiteen Prozedur wird eruiert, welcher der beiden Vektoren zu einer besseren Kompressionsrate verhilft.
Die 3 Varianten der Prädiktion PC
Jeder Makroblock eines B-Frames kann jetzt mit den beiden errechneten Bewegungsvektoren auf drei verschiedene Möglichkeiten prädiziert werden
- Makroblock wird aus vorhergehendem Referenzbild prädiziert
- Makroblock wird aus nachfolgendem Referenzbild prädiziert
- Makroblock des B-Frames ergibt sich aus dem Mittelwert der beiden gefundenen Makroblöcke in den beiden Referenzbilder
Die 3 Varianten der Prädiktion PDA_Phone
Jeder Makroblock eines B-Frames kann jetzt mit den beiden errechneten Bewegungsvektoren auf drei verschiedene Möglichkeiten prädiziert werden
- Makroblock wird aus vorhergehendem Referenzbild prädiziert
- Makroblock wird aus nachfolgendem Referenzbild prädiziert
- Makroblock des B-Frames ergibt sich aus dem Mittelwert der beiden gefundenen Makroblöcke in den beiden Referenzbilder
Auswahl einer Variante
Welche Variante verwendet wird, wird für jeden Makroblock individuell entschieden. Dazu wird für jede der 3 Varianten der Prädiktionsfehler berechnet, jene Variante mit dem kleinsten Prädiktionsfehler wird für die Kodierung weiter verwendet.
Vorteil
Durch die Möglichkeit, aus drei Varianten für jeden Block die am bestgeeignete zu wählen, wird eine hohe Genauigkeit der Bewegungskompensation erzielt. B-Frames bewirken daher im Allgemeinen einen viel höheren Kompressionsfaktor als P-Frames.
Nachteil
Kodierung von B-Frames erfordert längere Rechenzeiten als P-Frames. B-Frames können erst dann kodiert/decodiert werden, wenn ein zeitlich späteres Bild bereits vorhanden ist. Das macht die B-Frame-Kodierung für Echtzeitanwendungen wie Videotelefonie, Videokonferenz unbrauchbar.
D-Frames
1
auto reyn2004
- D-Frames sind selbstständige Bilder
- Bilder haben geringe Auflösung
- Sind nicht Bestandteil der GOP
- Haben ausschließlich Repräsentationsfunktion
- dienen hauptsächlich zur schnellen Durchsicht von Videos unabhängig von Komplexität der Hardware
2
auto reyn2004
Zusätzlich zu den bisher beschriebenen Frames definiert MPEG Video noch ein D-Frame. Dieses Frame ist einzig für Repräsentationszwecken gedacht und ist nicht Bestandteil der GOP .
D-Frames sind Intraframes mit einer sehr geringen Auflösung. Sie wurden bei der Entwicklung des Standards definiert, um ein schnelles Durchsuchen einer MPEG Videosequenz mittels fast forward/fast rewind Funktion zu ermöglichen. Die geringe Auflösung erzielt man dadurch, dass man jeden 8x8 Pixel Block nur durch seinen DC-Koeffizienten (siehe JPEG Bildvorbereitung) repräsentiert.
Durch die geringe Auflösung ist die erforderliche Dekodierzeit für ein D-Frame dementsprechend niedrig. So können viel mehr Bilder pro Zeiteinheit dekodiert werden, was eine schnellere Durchsicht des Videomaterials erlaubt.
Heute spielen die D-Frames keine sehr große Rolle mehr, da heute verwendete Hardware schnell genug ist, auch mit Hilfe der in der GOP enthaltenen I-Frames ein schnelles Durchsuchen zu ermöglichen.
Kodierung von Intraframes
1
Bildvorbereitung
- Farbraumtransformation
- Blockzerlegung - Zerlegung in 8x8 Pixel Blöcke
- DCT
Quantisierung
- mit Hilfe Quantisierungstabelle
- es gibt empfohlene Tabellen
- können aber auch frei gewählt werden
- Beschränkung: DC ist für MPEG-1 immer 8, für MPEG-2 8, 4, 2 oder 1
Bestimmung Skalierfaktor für Quantisierungstabelle
- Ist geforderte Datenrate niedrig, muss hoher Wert gewählt werden
- Ist geforderte Datenrate hoch, kann kleiner Wert gewählt werden
Kodierung der quantisierten DCT Koeffizienten
- DC-Koeffizienten Differenzkodierung
- AC-Koeffizienten
- Zick-Zack Abtastung (siehe JPEG Kodierungstechnik)
- Lauflängen- und Huffmankodierung
2
Bei der Intraframe-Kodierung werden Bilder ohne Bezug auf andere Bilder als selbstständige Bilder kodiert. MPEG-Kompressionsalgorithmen verfahren ähnlich wie jene des JPEG-Standards .
Bildvorbereitung
Farbraum Transformation
Das Farbbild wird durch ein Grauwertbild und zwei Chrominanzbilder dargestellt. Die beiden Chrominanzbilder werden je nach verwendetem Standard unterabgetastet.. Während MPEG-1 nur eine Farbunterabtastung von 4:2:0 zulässt, gibt es im MPEG-2 Standard zusätzlich die Wahl von 4:2:2, 4:4:4 (siehe MPEG-2 und MPEG-2 Levels und Profiles)
Blockzerlegung, DCT
Das Bild wird in 8x8 Pixel Blöcke unterteilt. Für jeden Block werden mittels Diskreter Cosinustransformation die DCT Koeffizienten ermittelt.
Quantisierung stru2002
Auch der MPEG Standard schlägt Quantisierungstabellen vor.
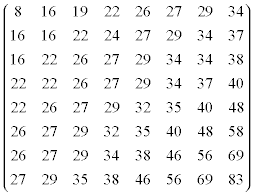
Der DC Koeffizient ist für MPEG-1 ist mit 8 festgelegt. Für MPEG-2 sind auch Werte von 4, 2 und 1 erlaubt.
Skalierfaktor für Quantisierungstabelle
Die Werte derQuantisierungstabelle können nach Bedarf mit einem Skalierfaktor multipliziert werden. Dieser dient zur Anpassung der Kompressionsrate an die Bitratensteuerung.
Skalierfaktor für Quantisierungstabelle
Ist die geforderte Datenbitrate niedrig, ist eine hohe Kompressionsrate notwendig. Es müssen daher die Werte der Quantisierungstabelle dementsprechend vergrößert werden. Dies erreicht man dadurch, dass man alle Werte mit einem Skalierfaktor multipliziert. Je höher der gewählte Wert für den Skalierfaktor, desto größer die erzielbare Kompression.
MPEG erlaubt Skalierfaktoren zwischen 1 und 31. Dieser wird vom Encoder je nach zur Verfügung stehender Anzahl an Bits eingestellt.
Kodierung der DC Koeffizienten
DC Koeffizienten werden gleich wie bei der JPEG Kodierung behandelt. (siehe LU 20). Es werden die Differenzen aufeinander folgender DC Koeffizienten kodiert. Die Differenzwerte werden in Klassen eingeteilt. Die Kategorienummer wird Huffman kodiert.
Kodierung der AC Koeffizienten
Gleich wie bei JPEG werden die Prozeduren der Zick-Zack- Abtastung (siehe JPEG Kodierungstechnik), derLauflängen- und der Huffmankodierung durchlaufen. Im Gegensatz zu JPEG werden die AC Koeffizienten nicht in Kategorien eingeteilt.
Kodierung von Interframes
1
Inter/Intrakodierung
- Jeder Makroblock wird eigenständig kodiert
- Wahl der geeigneten Kodierung
- War Blockmatching erfolglos, wird intrakodiert
- War Blockmatching erfolgreich, wird interkodiert
Interkodierung
- ähnlich der Interkodierung
- Prädiktionsfehler ist Bild
- Unterschiede zur Intrakodierung
- Quantisierungstabelle ist fix
- DC Koeffizienten werden nicht separat kodiert
- Bewegungsvektor und Information über Referenzbild muss mit kodiert werden
Tabelle für Interkodierung

2
auto
Die Kodierung eines Interframes ist wesentlich komplexer. Es kommen sowohl Techniken der Intraframe Kodierung, wie auch eine eigene Technik für Interframes zum Einsatz.
Inter/Intrakodierung
Für jeden Makroblock wird entschieden, ob interkodiert oder intrakodiert wird. Welche Methode gewählt wird, richtet sich nach dem Ergebnis des Blockmatchingverfahrens.
- War Blockmatching für eine Makroblock erfolglos, wird intrakodiert. Der Makroblock wird genau so kodiert, als wäre er ein Makroblock eines I-Frames.
- war Blockmatching für einen Makroblock erfolgreich, wird er interkodiert.
Interkodierung
Die Interkodierung funktioniert im Prinzip wie die Intrakodierung. Als Bild fungiert der Prädiktionsfehler. Im Gegensatz zur Intrakodierung ist die Quantisierungstabelle fix vorgegeben. Da die Makroblöcke eines Interframes durch Bewegungskompensation entstanden sind, gibt es oft keine Korrelation zwischen benachbarten Makroblöcken. Es werden daher die DC Koeffizienten nicht separat kodiert, sondern gemeinsam mit den zum jeweiligen Block gehörenden AC Koeffizienten. Zusätzlich müssen für jeden Makroblock der Bewegungsvektor und Informationen, auf welches Bild referenziert wird, in die Kodierung miteinbezogen werden.
Tabelle für Interkodierung
Komprimierungsverhalten der verschiedenen Frames reyn2004
1
auto
| Kompressionsverhalten | |
|---|---|
| I-Frame | 10:1-20:1 |
| P-Frame | 20:1-30:1 |
| B-Frame | 30:1-50:1 |
2
auto
| Kompressionsverhalten | |
|---|---|
| I-Frame | 10:1-20:1 |
| P-Frame | 20:1-30:1 |
| B-Frame | 30:1-50:1 |