| Title: | Entropiekodierung | ||
|---|---|---|---|
| Abstract: | Die Entropie bezeichnet den mittleren Informationsgehalt einer Nachricht. Der Informationsgehalt eines Zeichens hängt von der Auftrittswahrscheinlichkeit ab und ist umso größer, je kleiner die Auftrittwahrscheinlichkeit ist. Entropiekodierung ist auf alle Daten gleichermaßen anwendbar. In dieser Lerneinheit werden auf Entropie basierende Codierungstechniken, die oft zur Kompression mulitmedialer Daten verwendet werden, genauer beschrieben: Lauflängenkodierung, LZ und LZW Codierung, Huffmancodierung. | ||
| Status: | One applet missing - Does not validate! | Version: | 2005-01-05 |
| History: |
2005-01-05 (Thomas Migl): LOD3 "arithmetische Kodierung"
und LOD3 "Lauflängenkodierung" hinzugefügt: Text +link auf
applet |
||
| Author 1: | Hannes Eichner | E-Mail: | (empty) |
|---|---|---|---|
| Author 2: | Stefan Chung | E-Mail: | (empty) |
| Author 3: | Paul Pöltner | E-Mail: | (empty) |
| Author 4: | Julian Stöttinger | E-Mail: | (empty) |
| Author 5: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
| Organization: | Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einleitung1Entropiekodierung
2Entropie rech2002, 195Der Begriff der Entropie kommt aus der Informationstheorie. Die Entropie bezeichnet den mittleren Informationsgehalt einer Quelle (Nachricht). Der Informationsgehalt eines Zeichens hängt von der Auftrittswahrscheinlichkeit ab und ist umso größer, je kleiner die Auftrittwahrscheinlichkeit ist. Entropiekodierung hals2000, 118 gibb1998, 117Die Entropiecodierung ist verlustfrei und auf alle Informationstypen gleichermaßen anwendbar. Die Bedeutung der digitalen Werte ist hier irrelevant. Sie nutzt statistische Eigenschaften (z.B. Häufigkeit eines Zeichens) für eine effiziente Repräsentation der Information aus. Trotzdem die Darstellung der Information anders zu den Ausgangsdaten ist, können diese vollständig rekonstruiert werden. Lauflängencodierung (engl. "Run Length Encoding", RLE)1Funktionsweise
RLE-komprimierter Textstring
! - Fluchtzeichen; Indizierung des Zählers Anwendungen
Lauflängenkodierung applet40107 PC
2FunktionsweiseDie Lauflängencodierung (Run Length Encoding = RLE) ist ein sehr einfaches und schnelles Verfahren. In vielen Daten kommen Folgen identischer Zeichen (Bytes) vor. Diese Tatsache macht sich dieses Verfahren zu nutze und ersetzt diese im Ausgabecode durch das Zeichen gefolgt von einem Zähler, der die Anzahl des Auftretens angibt. Um den Zähler zu kennzeichnen wird ihm ein Zeichen vorangestellt, das im Originaltext selten vorkommt (es kann aber durchaus auftreten). Für die untenstehende Ausführung sei dies das Zeichen !. RLE-komprimierter Textstring
AUTOEin Zähler wird erst ab vier identischen Zeichen verwendet, da es bei drei Zeichen noch keine Ersparnis gibt. Bei einem oder zwei Zeichen wäre die Nachricht bei Verwendung eines Zählers sogar länger. FluchtzeichenEine Zahl im Code kann nun einerseits ein normaler Textbestandteil sein (eine Zahl eben), oder ein Zähler. Um einen Zähler anzuzeigen, wird ihm ein Fluchtzeichen (Escape-Symbol) - hier ! - vorangestellt. Die Zahlen 7 und 6 im obigen Beispiel sind Zähler für C bzw. E. Da nun ein ! bereits im Ausgangstext vorkommen kann, behilft man sich in einem solchen Fall damit, dem "!" dann eine 0 folgen zu lassen. Dies ist eindeutig, da ein Zähler mit dem Wert 0 sonst nie vorkommen kann. RLE-komprimierter Textstring dank2001, 313
Im Beispiel gibt es eine Reduktion von 21 auf 14 Zeichen (Byte). Das entspricht einer Kompression um 33,3% (14/21 = 0,666...). Im zweiten Beispiel werden die Daten von 25 auf 18 Byte reduziert. Da 18/28 gleich 0,72 ist, beträgt die Ersparnis 28%. AnwendungsgebieteRLE eignet sich besonders für Daten mit langen Folgen gleicher Zeichen wie Schwarzweißbildern. Das Verfahren wird demnach häufig für FAX-Formate verwendet. Dort treten nämlich große weise Flächen die durch schwarze Buchstaben unterbrochen werden auf. bovi2000 Als Teil einer Hybridkodierung (siehe Lerneinheit Motivation und Überblick) kommt die RLE Kodierung in Audio-, Bild- und Videokomprimierungsalgorithmen sehr häufig vor. Applet: Lauflängenkodierung applet40107 PCBeschreibungDas 10 x 10 große Feld links oben dient als Eingabefeld. Hier kann mit der Maus ein Bild gezeichnet werden oder mit den Buttons rechts daneben ein Muster geladen werden. Durch Drücken auf "Kodieren" wird der Kodierungsvorgang durchgeführt. Der Eingabestring veranschaulicht eine unkomprimierte Kodierung, in dem jedes "Pixel" einzeln als Buchstabe gespeichert wird. Das Ausgabefeld zeigt den String lauflängenkodiert an. In der Statistik darunter werden neben der Legende der Codierung der Speicherbedarf der Strings und die Kompressionsrate ausgegeben. Der Button "Animieren" veranschaulicht den Vorgang der Kodierung, der Button "Schrittweise" kodiert jeweils ein Zeichen der Eingabe. Mit "Zurücksetzen" werden alle Felder gelöscht, mit "Fläche löschen" kann das Eingabefeld zurückgesetzt werden. Instruktionen
3Applet "Lauflängenkodierung"Unter http://www.kom.e-technik.tu-darmstadt.de/projects/iteach/itbeankit/lessons/jpeg/Beginner/Runlength_Encoding/runlength_encoding.html finden Sie ein Applet, welches die grundlegende Arbeitsweise der Lauflängenkodierung veranschaulicht. BeschreibungNach der Auswahl von "File" - "New" in der Menüleiste kann ein beliebiger String eingegeben werden. Durch das Drücken des Buttons "Play" wird die Eingabe codiert und erscheint im rechten Fenster. Die Größenangaben unter den Fenstern beziehen sich auf den jeweiligen Speicherbedarf, der gelbe Balken "Coding Ratio" veranschaulicht den Kompressionserfolg. InstruktionenVersuche durch Experimentieren folgende Fragen zu beantworten:
LZ Codierung (Lempel-Ziv)1Hintergrund
Funktionsweise
Kompressionsrate
Anwendung für multimediale Daten
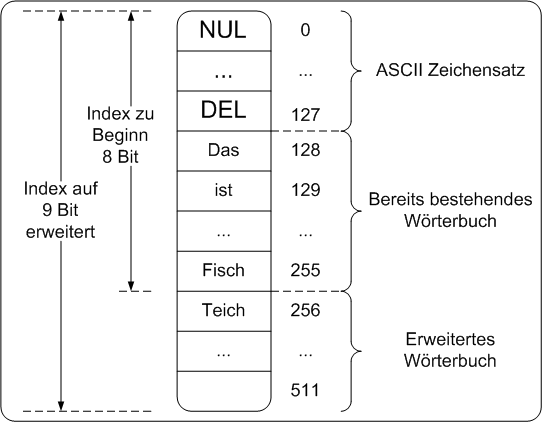
2FunktionsweiseDer Komprimierungsalgorithmus kodiert nicht einzelne Zeichen, sondern ganze Wörter. Für die Kompression eines Textes gibt es eine Tabelle mit allen im Text vorkommenden Wörtern. Für jedes Wort gibt es einen entsprechenden Index (Codewort). Anstatt nun die einzelnen Zeichen des Wortes zu kodieren, wird nur der Tabellenindex für das Wort gespeichert (übermittelt). Der Decoder kann dann den Index mit Hilfe derselben Tabelle in den Ausgangstext zurückverwandeln. Ein solcher Algorithmus wird auch als "wörterbuchbasierte Algorithmus" bezeichnet, da die Tabelle einem Wörterbuch entspricht. LZ Kodierung zur TextkompressionMan verwendet den LZ-Algorithmus um eine Textdatei zu komprimieren. Die durchschnittliche Wortlänge beträgt 6 und das Wörterbuch fasst 4096 Einträge. Wie groß ist die Kompression verglichen mit einer 7-Bit ASCII Codierung? Im Allgemeinen kann ein Wörterbuch mit Indizes von n Bit 2n Einträge haben. Da das Wörterbuch 4096 Einträge fasst, muss man für den Index 12 Bit verwenden, da:
Mit 7-Bit ASCII Codierung benötigt man für 6 Zeichen 42 Bits. Durch die Verwendung von Indizes hingegen nur 12.
Kompressionsverhalten hals2000, 136Viele lange Wörter im Text bringen in Summe gute Kompressionsraten, kurze Wörter bringen schlechtere Ergebnisse, da die Ersparnis geringer ist. Eine Vorraussetzung für das Verfahren ist, dass das gleiche Wörterbuch beim Codierer und Decodierer vorhanden ist. Es gibt aber ein erweitertes Verfahren (LZW), welches diesen Nachteil umgeht. Anwendungen für MultimediadatenAus obigem Beispiel könnte man schließen, dass diese Kodierungstechnik nur zur Kompression von Textdateien geeignet ist. Aber Wörter müssen nicht unbedingt aus Buchstaben bestehen, sondern können beliebige Zeichensequenzen sein. LZ Kodierung zur BildkomprimierungEs kann ein waagrechter Strich bestimmter Länge in einem Bild als ein Wort interpretiert werden. Kommt besagter Strich innerhalb eines Bildes öfters vor, so wird nicht jeder dieser Striche pixelweise, sondern nur durch seinen Index kodiert. LZW Codierung (Lempel-Ziv-Welsh)1Hintergrund
Dynamisches Wörterbuch
Abbildung: LZW Kodierung PCGegebender Text: "This is simple as it is... ...the fish pond..." Abbildung: LZW Kodierung PDA_Phone
Anwendung für multimediale Daten
2AUTOLempel-Ziv-Welsh Algorithmus baut auf den LZ Algorithmus auf. Durch Verwendung eines sogenannten "Dynamischen Wörterbuches" wird der Nachteil beseitigt, dass sowohl auf Decoder wie auf Encoderseite das gesamte Wörterbuch bekannt sein muss. Dynamisches WörterbuchAUTOBeim LZW-Algorithmus bauen sowohl Encoder und Decoder den Inhalt des Wörterbuchs dynamisch auf. Das heißt, es muss kein vorgegebenes Wörterbuch statisch bei Empfänger und Sender vorliegen, sondern wird beim Einlesen der Nachricht sukzessive aufgebaut. Als Anfangswerte beinhalten beide Wörterbücher den Zeichensatz, mit dem die Nachricht erstellt wurde (z.B. ASCII). Die anderen Einträge werden erst nach und nach erstellt. AUTOEin Zeichensatz enthält 128 Zeichen, das Wörterbuch ist auf 4096 Wörter beschränkt, dann sind die ersten 128 Einträge die Buchstaben und Sonderzeichen. Die restlichen 3968 Einträge enthalten Wörter mit einer Mindestlänge von zwei Zeichen. Je öfter ein Wort vorkommt oder je länger die Wörter sind, desto besser ist die Kompression. Im Wörterbuch werden nur alphanumerische Zeichenfolgen abgelegt und alle anderen Zeichen werden als Worttrennzeichen interpretiert. LZW Kodierung zur TextkompressionWir wollen nun an Hand eines Beispiels ein Wörterbuch dynamisch aufbauen. Der zu komprimierende Text sei: "This is simple as it is... ...the fish pond..." Anfangs beinhalten die Wörterbücher von Encoder und Decoder jeweils die Einträge des individuell verwendeten Zeichensatzes. Deshalb kann das erste Wort (This) nur durch die Indizes der einzelnen Zeichen gesendet werden. Wenn der Encoder nun das Leerzeichen liest, erkennt er dieses als Trennzeichen und somit als Wortende. Es wird ebenfalls der Index vom Leerzeichen gesendet und zusätzlich das vorhergehende Wort in die nächste freie Position ins Wörterbuch geschrieben (Abbildung, Position 128). Der Decoder macht das ganz ähnlich: Er liest die Indizes der einzelnen Buchstaben, um den Text zu rekonstruieren. Sobald der Leerraum erreicht ist, wird der Worteintrag im Decoder-Wörterbuch gesetzt. Diese Vorgehensweise setzt sich auf beiden Seiten so fort (für die Wörter is, simple, as). Bevor ein Wort durch die Codes der einzelnen Zeichen gesendet wird, überprüft der Encoder ob das Wort schon im Wörterbuch eingetragen ist. Wenn dies der Fall ist, braucht nur der Index des Wortes übermittelt werden. Genauer betrachtet heißt das, sobald ein Wort ein zweites Mal vorkommt, kann das Einsparungspotential genutzt werden, denn genau dann ist es schon im Wörterbuch auf beiden Seiten abgelegt. Dieser Fall tritt beim zweiten Vorkommen des Wortes 'is' ein. Nun müssen nicht die Codes der einzelnen Zeichen übermittelt werden, sondern nur der Index der im Wörterbuch auf dieses Wort verweist (Position 129). Abbildung: LZW Kodierung PCGegebender Text: "This is simple as it is... ...the fish pond..." Abbildung: LZW Kodierung PDA_Phone
Huffman Codierung1Prinzip der Huffmancodierung
CodebaumDarstellung der Codetabelle in Baumstruktur Hufmanncodetabelle PC
Huffman Codebaum PC
Huffman Codebaum PDA_Phone
Dynamische HuffmancodieungZwei Methoden der Huffmancodierung:
Anwendung für multimediale Daten
Huffmankodierung applet40101 jar und code vorhanden
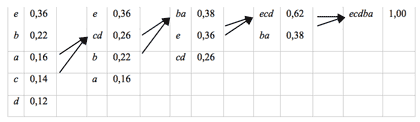
2Statistische Kodierung stei2000, 123Verschiedene Zeichen müssen nicht notwendigerweise auf eine feste Anzahl von Bits abgebildet werden. Dieses Prinzip wurde schon vor Beginn des Computerzeitalter vom Morsecode genutzt: Häufig auftretende Zeichen werden auf kurze Zeichenfolge abgebildet, seltene Zeichen werden durch längere Sequenzen codiert. Eine statistische Codierung verwendet also Wahrscheinlichkeiten von Zeichen, um möglichst optimal zu codieren. Die bekanntesten Verfahren dieser Gruppe sind die Huffman und die arithmetische Codierung. Prinzip Huffman Codierung stei2000, 123Für die Huffman Codierung seien die zu codierenden Zeichen mit der Wahrscheinlichkeit ihres Auftretens gegeben. Der Huffman Algorithmus ermittelt dann die Kodierung eines Zeichens mit der minimalen Anzahl benötigter Bits für die vorgegebene Auftrittswahrscheinlichkeit. Dabei wird eine Codetabelle aufgebaut, die jedem Zeichen eine Bitfolge zuordnet. Die Länge der Bitfolgen sind hier je nach Zeichen unterschiedlich. Codebaum dank2001, 244Die Codetabelle kann auch als binärer Baum dargestellt werden, bei dem jeder Knoten jeweils eine Kante mit der Beschriftung 0 und 1 hat. Die Blätter des Baums entsprechen den codierten Zeichen. Gerade für das Dekodieren beim Empfänger eignet sich diese Darstellung: Beginnend von der Wurzel folgt man je nach 0 oder 1 im Code den jeweiligen Ast. Dies setzt man fort, bis man ein Blatt erreicht. Die Bezeichnung des Blattes entspricht dem decodierten Zeichen. Nun setzt man den Algorithmus ausgehend von der Wurzel des Baumes fort. Aufbau des CodebaumesDer Huffman Algorithmus baut den Codebaum rekursiv auf, indem er die zwei Zeichen mit den geringsten Wahrscheinlichkeiten zu einem Teilbaum zusammenfasst. Dieser Teilbaum wird zu einem neuen Symbol mit dem Wahrscheinlichkeitswert der Summe der Einzelwahrscheinlichkeiten. Dieses neue "kombinierte" Symbol wird in den folgenden Schritten des Algorithmus weiter berücksichtigt. Die Kanten des Teilbaums werden mit 0 und 1 beschriftet. Diese Vorgehensweise wird nun rekursiv auf die neue Symbolmenge ausgeführt, bis alle Symbole zusammengefasst sind. Huffman CodierungGegeben seien die fünf Symbole der Quelle a, b, c, d, e mit den zugehörigen Wahrscheinlichkeiten. Anfangs werden jeweils die zwei Symbole mit den kleinsten Wahrscheinlichkeiten zu einem neuen zusammenfasst. Gleichzeitig ergibt sich durch diesen Schritt ein Teilbaum. Als Resultat erhält man den Codebaum bzw. die Codetabelle. dank2001, 245 Hufmanncodetabelle PC
Huffman Codebaum PC
Huffman Codebaum PDA_Phone
Ergebnis der HuffmankodierungUm fünf Symbole binär zu codieren sind normalerweise 3-Bit notwendig. Anstatt der festen 3-Bit Codierung werden jetzt einige Zeichen kürzer codiert und zwar die mit hoher Auftrittswahrscheinlichkeit. Ein Text, der Huffman codiert ist dadurch kürzer. KompressionsrateUm die Kompressionsrate zu bestimmen, errechnet man zuerst die durchschnittliche Wortlänge für die Huffman Codierung: Dabei multipliziert man die Wahrscheinlichkeiten der Symbole mit der Wortlänge des Symbols und bildet darüber die Summe
Im Vergleich zur 3-Bit Codierung ergibt sich bei diesem Beispiel durch Huffman eine Kompression auf 75,3 %.
Dynamische HuffmankodierungIm vorgestellten statischen Huffman-Verfahren müssen Sender und Empfänger die Codetabelle kennen, bzw. über die Wahrscheinlichkeiten Bescheid wissen. Es gibt eine andere Variante des Huffman-Algorithmus, der unter dem Namen "Dynamische Huffman-Codierung" bekannt ist. Hier wird der Codebaum dynamisch, also während der Übermittlung aufgebaut. Details dazu findet man in hals2000, 125. Anwendungen für MultimediadatenDie Huffman Kodierung spielt als Teil einer Hybridcodierung für sämtlicher multimediale Dateien (Audio, Video, Bild) eine entscheidende Rolle. Huffmankodierung applet40101 jar und code vorhandenBeschreibungIm oberen Teil der Anwendung kann der Eingabestring eingegeben werden. Mit dem "Clear" Button rechts wird das Formular zurückgesetzt. Der Button "Compress" führt die gesamte Kodierung in einem Schritt durch. Es erscheint im Wahrscheinlichkeitsfenster links eine Liste der im String verwendeten Zeichen und deren Auftrittswahrscheinlichkeiten. Im grauen Fenster in der Mitte der Anwendung wird die Kodierung durch den Huffman-Baum visualisiert. Die Zahlen in den blauen Knoten symbolisieren jeweils die Gesamtwahrscheinlichkeit des Unterbaumes bzw (an den Endknoten) die Auftrittswahrscheinlichkeit der jeweiligen Zeichen. In einigen seltenen Fällen kann auf Grund von internen Rundungsfehlern die Gesamtwahrscheinlichkeit ungleich eins sein. Aus dem Huffman-Baum werden dann im rechten Fenster die fertigen Bitfolgen des Codes generiert. In der Outputleiste darunter wird der gesamte Outputstring ausgegeben. In der abschließenden Statistik wird die Länge der ASCII ID Eingabe mit der generierten Kodierung verglichen und die durchschnittliche Wortlänge berechnet. Mit dem Button "Stepwise Compression" werden nur die Auftrittswahrscheinlichkeiten berechnet und jedes Zeichen als eigener Baum dargestellt. Durch das Drücken auf den Button "Next Step" unter den Fenstern werden jeweils die zwei Bäume mit den niedrigsten Gesamtwahrscheinlichkeiten zusammengefasst. Sobald ein Zeichen in einem Baum eingefügt wurde, wird eine einstweilige Kodierung ausgegeben. Mit dem Button "Finish Up" kann der Vorgang in einem Schritt beendet werden. InstruktionenKodiere reale Wörter und Sätze sowie auch "extreme" Zeichenketten mit sich oft wiederholenden Buchstaben. Wie verändert sich die Baumstruktur? Wie muss ein String beschaffen sein, um ihn gut kodieren zu können? Behindern Zeichen, die nur selten vorkommen, eine perfekte Kodierung? Welcher Zusammenhang besteht zwischen der Codelänge und der Auftrittswahrscheinlichkeit eines Zeichens? Vollziehe die einzelnen Schritte einer Kodierung von mehr als zehn verschiedenen Zeichen nach! Kennst du die Struktur des nächsten Durchganges bevor du ihn durch den "Next Step" Button durchführst? Wie werden die Zwischenkodierungen berechnet? Im fertigen Huffman-Code gibt es unterschiedliche Wortlängen. Wieso kann aus einem Bitstream der richtige Text dekodiert werden, obwohl es keine Trennzeichen zwischen den Wörtern gibt? In anderen Worten: Wie ist sichergestellt, das kein Codewort der Anfang eines anderen Codeworts ist (Präfixfreiheit)?
3Ein weiteres Huffman Applet applet40102BeschreibungDurch eine Eingabe im Textfeld wird die Codierung in Echtzeit berechnet und dargestellt. Die Auswahl zwischen "Numeric" und "Symbolic" gibt an, ob an den Blättern des Huffman Baumes die Zeichen selbst oder dessen Auftrittshäufigkeiten angezeigt werden. Mit dem Button "code" bzw. "tree" kann zwischen der Baumansicht und einer Liste der vorkommenden Zeichen und dessen generierter Code umgeschalten werden. Der Button "random tree" liefert einen Zufallsstring als Eingabe. InstruktionenExperimentiere mit Strings mit vielen Wiederholungen. Sind oft vorkommende Zeichen im Vergleich zu selten vorkommenden Zeichen im Baum nahe oder fern der Wurzel zu finden? Wie wirkt sich das auf ihren Code aus? Vollziehe den Aufbau eines Baumes und des Codes gedanklich nach. Welches Kind eines Knotens liefert als Codierung eine Null: Das Rechte oder das Linke? Könnte dies einfach vertauscht werden? Was kann man über die Auftrittswahrscheinlichkeit eines Zeichens sagen, wenn "sein" Blatt als einziges direkt an der Wurzel hängt und alle restlichen Zeichen den anderen Unterbaum der Wurzel bilden? (Beispieleingaben: "alabama" oder "ananas") Kann man diese Aussage auch auf Knoten weiter unten im Baum anwenden?
Arithmetische Kodierung1auto
Platzhalter für Applet Arithmetische Kodierung!!! 2autoDas Prinzip der arithmetischen Codierung ist die Darstellung einer Nachricht als Intervall in den rationalen Zahlen.Eine arithmetische Codierung hat, wie die Huffman Codierung, Wahrscheinlichkeiten als Ausgangspunkt. Aus der Sicht der Informationstheorie sind beide Codierungen optimal. Im Gegensatz zu anderen Verfahren werden durch eine Bitfolge mehrere Zeichen kodiert, dabei wird ein einzelnes Quellsymbol durch eine gebrochene Anzahl an Bits codiert und nicht, wie es sonst der Fall ist,durch eine ganzzahlige Anzahl. Abgesehen von der Hardwarebeschränkung für die Rechengenauigkeit ist damit absolut redundanzfreie Komprimierung möglich. Während die Huffman Codierung jedes einzelne Zeichen isoliert betrachtet, wird bei der arithmetischen Codierung das aktuelle Zeichen unter Berücksichtigung der vorangegangenen codiert. Deshalb muss ein arithmetisch codierter Datenstrom immer von Anfang an gelesen werden, ein wahlfreier Zugriff ist daher nicht möglich. 3Applet "Verlustlose Kodierung"Unter http://www-mm.informatik.uni-mannheim.de/veranstaltungen/animation/multimedia/Schmid_2002/ finden Sie ein Applet, das Huffman-, LZW- und arithmetische Kodierungsverfahren miteinander vergleicht. BeschreibungIn einem Textfeld gibt man eine beliebige Zeichenfolge ein, und wählt dann das gewünschte Kompressionsverfahren. Anschließend wird mit Hilfe einer Animation das Verfahren schrittweise veranschaulicht. Beschränkungen fur die Texteingabe
Instruktionen
Platzhalter für Applet Arithmetische Kodierung Kurzbeschreibung Applt füt Huffamn, arithmetische Kodierung www http://herodot.informatik.uni-mannheim.de/appverw/appletlist.php Autor Oliver Schmid |


| (empty) |