| Title: | MPEG Video Kodierungsprinzip | ||
|---|---|---|---|
| Abstract: | Videosequenzen bestehen aus einer großen Anzahl aufeinander folgender Standbilder. Will man Videosequenzen digital speichern und wiedergeben, kann man jedes Bild separat kodieren und die Videosequenz als Folge dieser kodierten Bilder darstellen. Die sich daraus ergebende Datenmenge ist aber enorm. MPEG Video nutzt zur Datenreduktion örtliche und zeitliche Redundanzen | ||
| Status: | Captions missing, 2 dead links | Version: | 2005-01-17 |
| History: |
2005-02-21 (Martin Hon): applet-m4_05_29_02 nicht erlaubte attribute entfernt 2005-02-21 (Martin Hon): codebase für applet-m4_05_29_02 hinzugefügt 2005-01-17 (thomas Migl): math-xml hinzugefügt 2005-01-07 (Robert Fuchs): Captions missing, two links dead; added applet-m4_05_29_02. 2004-11-15 (Thomas Migl): Flash Applet eingefügt 2004-11-09 (Thomas Migl): Instruktionen für applet hinzugefügt 2004-11-08 (Thomas Migl): fehlende PDA-Abb. hinzugefügt 2004-11-04 (Thomas Migl): Applet instructions added, acro added 2004-10-14 (Thomas Migl): pda Abb hinzugefügt 2004-09-23 (Thomas Migl): inhaltlichen Fehler ausgebessert 2004-09-22 (Thomas Migl): Applettext implementiert 2004-09-16 (Thomas Migl): PDA Abb. hinzugefügt 2004-09-13 (Thomas Migl): Text für Applet 2004-08-16 (Robert Fuchs): Checked, fixed and exported for Review #2. 2004-08-10 (Thomas Migl): In greybox importiert, finalisiert, Abb für PDA fehlen 2004-03-12 (Robert Fuchs): Closed for 50% Content Deadline import in Scholion. 2004-03-12 (Robert Fuchs): Fixed bugs in content tagging; nested lists bug. 2004-03-11 (Thomas Migl): LOD1 Headers added 2004-03-09 (Thomas Migl): LOD1 und Abstract hinzugefügt 2004-03-05 (Robert Fuchs): Added links. 2004-03-04 (Robert Fuchs): Imported and tagged content from "m4-LU29-Videokomprimierungsprinzip-fertig.doc"; some changes to structure, more CorPUs than in Word document. 2004-02-25 (HTMLContentTools):Created skeleton page |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | Chrisitan Ritzinger | E-Mail: | (empty) |
| Author 3: | Eva Wohlfart | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einführung1Speicherbedarf PAL Fernsehen
Redundanzen
2autoVideosequenzen bestehen aus einer großen Anzahl aufeinander folgender Standbilder. Ab einer bestimmten Bildfrequenz (z.B. Pal-TV 25 Bilder/s) werden Bild-zu-Bild-Änderungen von unserem Gehirn als Bewegung wahrgenommen. Die Abfolge statischer Bilder suggeriert uns einen zeitlich kontinuierlichen Bildverlauf. Will man Videosequenzen digital speichern und wiedergeben, kann man jedes Bild separat kodieren und die Videosequenz als Folge dieser kodierten Bilder darstellen. Die sich daraus ergebende Datenmenge ist aber enorm. Speicherbedarf für PAL FernsehenEin Fernsehbild besteht aus 370.944 Pixel. Um die Farbinformationen jedes Pixels speichern zu können, benötigt man 8 Bit pro Grundfarbe. Daraus ergeben sich erforderliche 24 Bit pro Pixel. Für ein einziges Bild benötigte man dann 1,08 MB Speicherplatz, für eine Sekunde Film (ohne Ton) das 25-fache, nämlich 27MB. Auf einer CD könnte gerade eine 26 sekundenlange Filmsequenz gespeichert werden, auf einer DVD mit 4,7GB knappe 3 Minuten. reyn2004 Zeitliche und örtliche RedundanzZiel der MPEG 31 -Kodierung ist ist es nun, diese hohen Bitraten ohne wesentliche Qualitätseinbußen des Videosignals zu reduzieren. Dabei betrachtet man die Redundanzen einer Videosequenz sowohl in örtlicher als auch in zeitlicher Richtung. siko1997
Differenzbild1auto
2autoDa aufeinanderfolgende Bilder einer Videosequenz gewöhlich einen ähnlichen Bildinhalt aufweisen, liegt es nahe, sich der Differenzkodierung zu bedienen. Es wird dabei nicht jedes Bild für sich kodiert. Vielmehr versucht man ein Bild aus einem vorhergehenden Referenzbild zu rekonstruieren. Anstelle der gesamten Bilder werden nur dessen Differenzen gegenüber einem Referenzbild gespeichert. Algorithmus für DifferenzbildZur Differenzbildung werden bei Video MPEG nur die Grauwerte der einzelnen Pixel verwendet. Die Farbwerte spielen dabei keine Rolle. Bild 2 ist das Bild1 unmittelbar folgende Bild.
mit
Bild 1 und Bild 2 sind ident1Errechnung des Diferenzbildesauto PC
auto PDA_Phone
Decodierung des Bildes 2 aus Bild 1 und Differenzbildauto PC
auto PDA_Phone
2Errechnung des DifferenzbildesSind nun das Referenzbild und dessen nachfolgendes Bild absolut gleich und man bildet die Differenz der beiden, ergibt sich ein homogenes schwarzes Differenzbild (Pixelwerte sind alle gleich Null). Bild 1 ist das Referenzbild, Bild 2 das in der Videosequenz zeitlich darauffolgende. In der Videosequenz sitzt die Person regungslos auf ihrem Bürosessel. Referenzbild und das darauffolgende Bild sind absolut gleich. Das daraus resultierende Differenzbild ist schwarz. auto PC
auto PDA_Phone
Kodierung gleicher BilderBei der Kodierung der Videosequenz wird bei MPEG-Video nur das Referenzbild und das Differenzbild kodiert. Da eine schwarze Fläche nur wenig Information enthält, lässt sich dieses durch Lauflängenkodierung etc. auf ein Minimum von Daten komprimieren. Die Dateigröße von Bild 1 und Differenzbild entspricht fast nur mehr der Hälfte jener, als wenn man Bild 1 und Bild 2 kodierte. Sind die folgenden Bilder der Videosequenz Bild 3, Bild 4....auch ident mit Bild 1, so werden auch diese für die MPEG-Kodierung durch ihre Differenzbilder bezogen auf das Referenzbild 1 ersetzt. Dabei gilt, je mehr Bilder, desto höher die Kompression. Decodierung des Bildes 2 aus Bild 1 und DifferenzbildBei der Wiedergabe errechnet der MPEG-Dekoder Bild 2 aus dem Differenz- und dem Referenzbild. auto PC
auto PDA_Phone
Bild 1 und Bild 2 nicht ident1Errechnung des Differenzbildesauto PC
auto PDA_Phone
2Errechnung des DifferenzbildesDie Person bewegt sich mit ihrem Bürosessel Richtung Schreibtisch. Bild 2 ist dabei wieder das dem Referenzbild Bild 1 zeitlich folgende Bild. Das resultierende Differenzbild ist nicht mehr eine homogene schwarze Fläche, sondern es sind je nach dem Ausmaß der Bewegung Strukturen im Bild sichtbar. Überall dort, wo durch Bewegung verursachte veränderte Bildinhalte im Bild 2 gegenüber Bild 1 auftreten (Person und Sessel), sind im Differenzbild Strukturen erkennbar. Bildbereiche, in denen keine Veränderungen stattgefunden haben, bleiben auch hier schwarz (Hintergrund). auto PC
auto PDA_Phone
Kodierung nicht identer BilderDa in diesem Fall das Differenzbild mehr Information als eine homogene schwarze Fläche enthält, kann das Differenzbild nicht mehr so stark komprimiert werden. Dabei gilt, je mehr Bewegung, desto mehr Information und desto schlechter komprimierbar. Die Technik der Kodierung des Differenzbildes kann in diesem Fall nicht mehr so eine hohe Kompression erzielen. Bewegungsvektor, Prädiktionsbild, Prädiktionsfehler1Bewegungsvektor
Veranschaulichung Bewegungsvektor PC
Veranschaulichung Bewegungsvektor PDA_Phone
Prädiktionsbild
PrädiktionsfehlerDifferenzbild zwischen Prädiktionsbild und Origonalbild 2BewegungsvektorUm möglichst ein schwarzes homogenes Differenzbild auch im Fall einer Bewegung zu erhalten, arbeitet man bei MPEG-Video mit Bewegungsvektoren. Der Bewegungsvektor gibt an, wohin sich ein bestimmter Bildbreich aus Bild 2 relativ zu Bild 1 verschoben hat. (siehe Bewegungskompensation) Veranschaulichung Bewegungsvektor PCDie Abbildung veranschaulicht den Bewegungsvektor, der die örtliche Änderung der Lehne des Bürosessels beschreibt.
Veranschaulichung Bewegungsvektor PDA_Phone
PrädiktionsbildMan verwendet nun für die Erzeugung des Differenzbildes statt des Referenzbildes das durch Bewegungskompensation errechnete Prädiktionsbild. siehe Bewegungskompensation) Der MPEG-Standard benützt zur Erzeugung eines Prädiktionsbildes das Block-Matchingverfahren (siehe Bewegungsschätzung und -kompensation) Bei optimaler Bewegungskompensation ist das Differenzbild wieder einheitlich schwarz, was eine optimale Komprimierung bewirkt. Das Originalbild kann in diesem idealen Fall allein durch Kenntnis des Referenzbildes und den Bewegungsvektoren originalgetreu rekonstruiert werden. PrädikitonsfehlerDa es sich bei den Bewegungsvektoren um Schätzwerte handelt, werden Prädiktionsbild und Originalbild je nach Qualität der Schätzung mehr oder weniger von einander abweichen. Um das Originalbild trotzdem verlustlos rekonstruieren zu können, muss neben Referenzbild und Bewegungsvektoren zusätzlich der Prädiktionsfehler bekannt sein. Der Prädiktionsfehler ist dabei das Differenzbild von Originalbild und Prädiktionsbild. Group of Pictures siko1997 stru2002,1921auto
GOP kann enhalten:
Kodierung einer GOP PC
Kodierung einer GOP PDA_Phone
geschlossene/offene GOP
Geschlossene/offene GOP
2autoDie GOP (Group of Pictures) beschreibt die Anordnung der im MPEG-Standard definierten Frametypen (siehe Frames inMPEG Video) in einer MPEG-Videosequenz. Jede Gruppe muß mit einem I-Frame beginnen. Anzahl, Typen und Anordnung die innerhalb einer GOP enthalten sind, kann frei gewählt werden. Unterschiedliche GOPs sind jeweils für verschiedene Anwendungen geeignet. GOP nur mit I-FramesNur mäßige Kompression. Bietet höchsten Grad an Editierbarkeit, da man auf jedes einzelne Bild zugreifen kann. GOP nur mit I-FramesIIIIIIIIIII GOP mit I und P- FramesErgibt bessere Kompression, aber eingeschränkte Editierbarkeit. GOP mit I und P- FramesIPPPPPPPPPPPIPPPPP etc. GOP mit I,P und B-FramesFür maximale Kompression. Beim Einsatz von B-Frames müssen allerdings einige Dinge beachtet werden. Sie müssen so lange zwischengespeichert werden, bis das nächste P oder I Frame kommt. Das bedeutet neben erhöhtem Speicheraufwand eine Zeitverzögerung. Diese Tatsache machen diese GOP Struktur für Videotelefonie und anderen Echtzeitanwendungen unbrauchbar. Weiters ist zu bedenken, je mehr B-Frames zwischen einem I und einem P-Frame liegen, umso mehr verschlechtert sich durch den vergrößerten Zeitabstand die Prädiktionsmöglichkeit des P-Frames. GOP mit I, P und B FramesIBBPBBP Kodierung einer GOP PCDie Grafik zeigt exemplarisch eine GOP. Die I, P und B Frames enthält. Weiters ist für dieses Beispiel die Kodierungsabfolge angegeben.
Kodierung einer GOP PDA_PhoneDie Grafik zeigt exemplarisch eine GOP. Die I, P und B Frames enthält. Weiters ist für dieses Beispiel die Kodierungsabfolge angegeben.
Offene/geschlossene GOPsOffene GOPIn einer "offenen GOP" ist das letzte Frame stets ein B-Frame. Da das Schluss B-Frame dieser GOP nur mit Hilfe des Start I-Frames der nächsten GOP encodet werden kann ist eine direkte Editierbarkeit eines solchen Datenstroms nicht möglich. Offene GOPVideostream: IBBPBBPIBBPBBPIBBPBBPIBBPBBP etc. offene GOP: IBBPBBP Geschlossene GOPEine "geschlossene GOP" endet stets mit einem P-Frame. Ein solcher MPEG-Datenstrom kann editiert werden. Eine Videosequenz kann am Enpunkt jeder GOP geschnitten werden, ohne das Information verloren geht. Geschlossene GOPVideostream: IBBPBBIIBBPBBIIBBPBBIIBBPBBI etc. geschlossene GOP: IBBPBBI 3Downloadsuntere www.tmpgenc.net kann man einen MPEG Encoder downloaden, mit dessen Hilfe man in den Kodierungsvorgang in Bezug auf GOP, Vidoepuffergröße, Quantisierungstabelle etc. sehr genau eingreifen kann. Videopuffer1Wozu dient der Videopuffer?
Funktionsweise
Puffergröße
Videopuffergröße im MPEG-Standard
2Wozu dient der Videopuffer?Der Videopuffer ist dafür verantwortlich, dass eine Videosequenz unabhängig von Bildinhalt, der Art der Bewegungen usw...in einem MPEG-Datenstrom konstanter Datenrate kodiert wird. Funktionsweise des VideopuffersEin besonderes Feature von MPEG-1 ist es, dass unabhängig vom Bildinhalt die Datenstromrate immer konstant ist. Diese Aufgabe übernimmt der Videopuffer, der über eine Rückkopplung Einfluss auf die Quantisierungsgröße der DCT 242 -Koeffizienten nimmt. Der Videopuffer selbst ist nichts anderes, als ein Zwischenspeicher. An seinem Ausgang werden die Daten in der vorgeschriebenen konstanten Datenrate ausgelesen und an den Decoder gesandt. Ist eingangseitig eine erhöhte Datenrate, wird der Puffer aufgefüllt. Um ein Überlaufen des Puffers zu vermeiden, wird eine gröbere Quantisierung der Koeffizienten gewählt, was eine Verschlechterung der Bildqualität aber auch eine Reduktion des Datenstromes bewirkt. Liegt der Datenstrom unterhalb der gewünschten Ausgangsrate, sinkt der Füllstand des Puffers. Jetzt wird die Quantisierung verfeinert, die Bildqualität und damit wieder die Datenrate am VP 524 -Eingang erhöht. PuffergrößeKriterien zur Dimensionierung des Puffers:
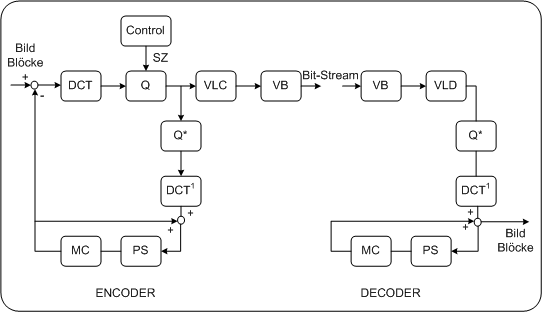
Videopuffergröße im MPEG-StandardMPEG Standard definiert einen Maximalwert für die Größe des Videopuffers. Jeder MPEG-Decoder muss über einen Puffer dieser Größe verfügen. Auf Encoderseite steht es dem Produzenten frei, auch eine kleinere Puffergröße zu verwenden. Dazu wird im Encoder eine virtuelle Puffergröße angegeben. Diese wird mit dem MPEG-Datenstrom mit übertragen. 3DownloadsUnter http://www.tmpgenc.net/ kann man einen MPEG Encoder downloaden, mit dessen Hilfe man in den Kodierungsvorgang in Bezug auf GOP, Vidoepuffergröße, Quantisierungstabelle etc. sehr genau eingreifen kann. MPEG Kodierer/Decoder1Blockschaltbild PC
Blockschaltbild PDA_Phone
2BlockschaltbildDas Blockbild zeigt Prinzip eines MPEG- Encoders und Decoders. Es wird dabei jeder 8x8-Pixel Block separat verarbeitet. siko1997 Abbildung: MPEG Codec PC
Blockschaltbild PDA_Phone
Blockschaltbild MPEG CodecKodierung I FrameDas erste Bild, das kodiert wird ist ein I-Frame. Mit dem ersten Block beginnend wird jeder Block einer DCT unterzogen, dessen resultierenden Koeffizienten quantisiert, und nach Entropykodierung (im Blockbild VLC) an den Eingang des Videopuffers gelegt. Je nach Beschaffenheit des soeben kodierten Bildblockes ist die Datenrate am Eingang des VB verschieden groß. Sind im Bildblock starke Konturen enthalten, wird die Datenrate groß sein, ist nur wenig Bildinhalt enthalten, wird sie klein sein. Ein besonderes Feature von MPEG-1 ist nun aber, dass unabhängig vom Bildinhalt die Datenstromrate immer konstant ist. Kodierung P-FrameFür die Kodierung eines P-Frames muss zuerst das vorangegangene I- oder P-Frame in einem Speicher (FS) abgelegt werden. Durch Bewegungsschätzung wird für jeden 16x16-Pixel Makroblock der Bewegungsvektor eruiert. Dieser wird kodiert an den Decoder weitergesendet. Der Prädiktionsfehler jedes Makroblockes ergibt sich aus dem Differenzbild Original- Prädiktionsbild. Jeder Makroblock wird in vier 8x8-Pixel Luminanzblöcke und in einer der Anwendung entsprechenden Anzahl an Chrominanzblöcken (für MPEG-1 je 1, für MPEG-2 je 1,2 oder 4) unterteilt. Für jeden dieser 8x8-Pixel-Blöcke wird die selbe Prozedur wie die bei I-Frame Kodierung angewandt. Für die Quantisierungssteuerung gilt, daß für jeden Makroblock eine eigene Quantisierungsgenauigkeit eingestellt werden kann. Kodierung B-FrameFür die Kodierung eines B-Frame müssen das vorangegangene und das nachfolgende Bild im Speicher FS abgelegt werden. Es werden zuerst die beiden Bewegungsvektoren pro Makroblock, dann alle 3 möglichen Prädiktionsbilder (vor-, rückwärtsprädiziert oder gemittelt) und deren Prädiktionsfehler berechnet. Für jeden Makroblock wird jener Vektor zur darauffolgenden Kodierung verwendet, der den geringsten Prädiktionsfehler ergeben hat. Applet Grundprinzip Videokomprimierung1Applet Bewegungskompensation: Vollbild applet-m4_05_29_02
2Applet Bewegungskompensation applet-m4_05_29_02Dieses Applet zeigt, wie zeitliche Redundanz zweier aufeinanderfolgender Bilder innnerhalb einer Videosequenz durch Errechen von Bewegungsvektoren und dazugehörigen Prädiktionsfehler von MPEG Encodern beseitigt werden. Es kann eine Videosequenz gewählt werden, eine gewünschte Costfunction (siehe Lerneinheit Bewegungsschätzung und-kompensation, Teil 1) und Suchmethode (siehe Lerneinheit Bewegungsschätzung und-kompensation, Teil 2). Applet Blockmatching (Vollbild)Mit dem Applet Bewegungskompensation, Reiter Vollbild, kann man nachvollziehen, wie sich bei zwei aufeinanderfolgenden Bilder einer Videosequenz sich die Bewegungsvektoren und der Prädiktionsfehler ergeben. Man kann eine bestimmte Videosequenz, die Costfunction und die Suchmethode, die bei der Blocksuche verwendet werden sollen, wählen . Angezeigt werden die errechneten Bewegungsvektoren, das Differenzbild (durch Schaltfläche Change wahlweise bewegungskompensiert oder nicht bewegungskompensiert), und ein Bild, das nur anhand der Bewegungsvektoren rekonstruiert worden ist (ohne Prädiktionsfehler). Der Prädiktionsfehler ist das Differenzbild bei Bewegungskompensation. Für Karteireiter Makro siehe Lerneinheit Bewegungsschätzung und -kompensation 2. Instruktionen
Bildsequenzen, die zur Auswahl stehen
MPEG-Video Bitratensteuerung1CBR/VBR
Applet: MPEG-Video Bitratensteuerung CBR/VBR applet-m4_05_29_01
2CBR/VBRBei MPEG-Videokodierung wird die Bitrate vom Encoder aktiv gesteuert. Bisher wurde nur der Fall betrachtet, dass der Encoder unabhängig vom Videoinhalt die Datenrate immer konstant hält. MPEG Video erlaubt aber auch einen Betriebsmodus, in welchem der Encoder im Bedarfsfalle die Datenrate erhöhen bzw. reduzieren kann. Diese Technik bezeichnet man als VBR 450 - Kodierung (im Gegensatz zur CBR 449-Kodierung). Der Encoder kann nun bei Szenen, die viel Bewegung beinhalten, die Datenrate dementsprechend erhöhen, bei Szenen, die eher statisch sind, die Datenrate reduzieren. Es ergibt sich dadurch eine durchschnittliche Datenrate, die bei den meisten Decoder die Benützerin vorgeben kann. In der Regel sind VBR kodierte Videos qualitativ besser als CBR kodierte, obwohl die durchschnittliche Datenrate der VBR-Kodierung gleich der Datenrate der CBR- Kodierung ist. Verwendet wird der VBR Modus zum Beispiel zur Speicherung von Videomaterial auf DVD 311 . Für Broadcasting-Anwendungen, Videokonferenzen, Streaming etc. hingegen ist die VBR Kodierung nicht geeignet, da sich hier die Datenrate nach der zu Verfügung stehenden Bandbreite des Nachrichtenkanals ergibt, aber diese nicht variiert werden kann. Applet: MPEG-Video Bitratensteuerung CBR/VBR applet-m4_05_29_01BeschreibungIn diesem Applet werden Videodaten und die grafische Repräsentation der Bitrate und Quantisierung dargestellt. Zu Beginn erfolgt die Videoauswahl, es stehen 6 Videos zur Verfügung. Von jedem Video gibt es jeweils eine VBR und eine CBR Variante, die gleichzeitig abgespielt werden. Unter den Videobildern befinden sich die Grafiken, bei denen auch die Peaks und Durchschnittswerte für Bitrate und Quantisierung angegeben sind. Mittels Scroll-Leiste kann man beliebige Videostellen anwählen. InstruktionenGehen Sie die verschiedenen Videos durch und beobachten Sie, wodurch Quantisierung und Bitrate beeinflusst werden.
|










| (empty) |