| Title: | MP3 | ||
|---|---|---|---|
| Abstract: | MP3 ist der komplexeste Layer des MPEG Audiostandards. Aufbauend auf den MPEG Audiocodierungsprinzipien beschreibt diese Lerneinheit die technischen Erweiterungen von MP3 gegenüber den beiden einfacheren Layern I und II. Es werden die von MP3 verwendete Hybridfilterbank, die spezielle Hybridkodierung und die Besonderheit der variablen Datenratensteuerung beschrieben. Abschließend gibt es einen Überblick über die verschiedenen durch MPEG Audiokompression eingeführten Artefakte. | ||
| Status: | Final for Review #2 - Audio sample and captions missing | Version: | 2004-11-05 |
| History: |
2004-11-05 (Thomas migl): Acros added 2004-09-23 (Thomas Migl): abb. explanations korrigiert 2004-08-16 (Robert Fuchs): Checked, fixed and exported for Review #2. 2004-08-04 (Thomas Migl): PDA Abb importiert 2004-07-29 (Thomas Migl): Hörbeispiele und Abb-finalPC importiert, LOD1 etwas geändert 2004-07-26 (Robert Fuchs): Manual import into the Greybox. 2004-03-12 (Robert Fuchs): Closed for 50% Content Deadline import in Scholion. 2004-03-11 (Thomas Migl): LOD1 Header added 2004-03-05 (Thomas Migl): Abstract hinzugefügt 2004-03-05 (Robert Fuchs): Put sources into CorPU title where neccessary; added links. 2004-02-27 (HTMLContentTools): Replaced old numeric source refs by new alphanumeric ones. 2004-02-26 (Robert Fuchs): Upgrade from old LU 430, version 2003-12-03. 2004-02-25 (HTMLContentTools): Created skeleton page. 2003-12-03 (Robert Fuchs): Import von Version 2003-08-23 aus HTML Authoring Systeme v.1 |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einführung bran20001AUTO
Erweiterung gegenüber Layer I und II
2AUTOMP3 ist der komplexeste Layer im MPEG-1 Audiostandard (siehe Lerneinheit Der MPEG-1 Audiostandard). Im MPEG-2 Standard, Teil3 (siehe Lerneinheit Der MPEG-2 Standard) werden Erweiterungen von MP3 unter der Bezeichnung MPEG-1/2, Layer -3 beschrieben. MP3 wurde mit dem Ziel konzipiert, ein Stereosignal mit einer Datenrate von 128 kbps in bestmöglicher Qualität zu kodieren. Erweiterte Architektur gegenüber Layer I und IIMP3 baut auf Grund der Kompatibiltät streng auf die Architektur von MPEG1 Audio Layer I, II auf. Die wesentlichen Erweiterungen im Überblick:
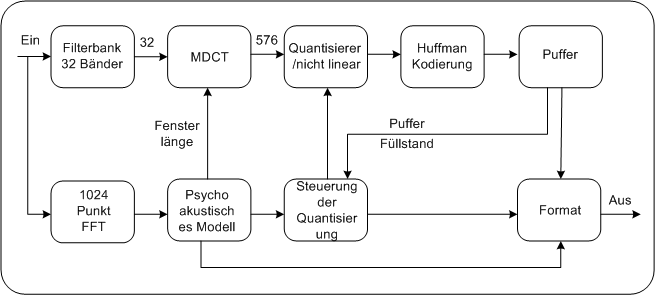
Erweiterte AbtastratenMPEG-2 definiert zusätzliche Abtastraten von 16 kHz, 22.05 kHz und 24kHz. Das entspricht genau der Hälfte der Werte aus MPEG-1. MPEG-2.5 Ist der Name einer MP3 Erweiterung des MPEG-1/2 Layers. MPEG-2.5 erlaubt zusätzlich die Kodierung von Audiosignalen mit Abtastfrequenzen von 8 kHz, 11.05 kHz, 12 kHz. Erweiterte BitratenIm MPEG-2 Standard wird der mögliche Bitratenbereich von 32-224kbps ( MPEG-1) auf 8-320kbps erweitert. Blockschaltbild MP3 Encoder1Abbildung: MP3 Encoder PC
Abbildung: MP3 Encoder PDA_Phone
2Abbildung: MP3 Encoder PC
Abbildung: MP3 Encoder PDA_Phone
Abbildung: MP3 Encoder
Hybridfilterbank1Polyphase Filterbank2-stufige Filterbank:
MDCT bei MP3Zerlegt Signal in 576 Frequenzbänder
Heisenberg Ungleichheit
Switch-Funktion für FensterlängeHybridfilterbank kann mit verschiedenen Fensterlängen arbeiten:
2AUTOMP3 benutzt zwei Stufen, um das Signal in Subbands zu zerlegen. Da die beiden Stufen nach verschiedenen Prinzipien arbeiten, werden sie als Hybrid Filterbank bezeichnet Polyphase Filterbank watk2001, 312Aufbauend auf die Architektur von MPEG-1/Audio behält Layer III die Eingangsstruktur des MPEG/Audio Standards mit der 32-Subband polyphase Filterbank bei (siehe Lerneinheit MPEG Audio Kodierungsprinzip). MDCT bei MP3 bran2000Jedes der 32 Subands der polyphasen Filterbank wird durch die MDCT in noch feinere Frequenzbänder aufgeteilt. Praktisch bewirkt die MDCT, dass jedes Subband in 18 Untersubbands gegliedert wird. Das entspricht dann einer Gesamtanzahl von 576 Subbands in MP3 gegenüber 32 Subbands in Layer I und II. Der Vorteil der höheren Anzahl an Subbands liegt darin, dass das psychoakustische Modell den Bändern passgenauere Maskierungsschwellwerte zuordnen kann, was eine höhere Kompression ermöglicht (siehe Lerneinheit MPEG Audio Kodierungsprinzip). Eigenschaften der MDCTBei der Verwendung der MDCT (siehe Transformationen) muss folgendes berücksichtigt werden. Im Gegensatz zur polyphasen Filterbank, die unabhängig von der gewählten Fensterlängeimmer 32 Subbands erzeugt, ist die Anzahl der Subbands bei der MDCT nicht konstant. Sie hängt von der gewählten Fensterlänge ab. Für lange Fenster ergeben sich mehr Subbbands, für kurze Fenster weniger (siehe Lerneinheit MPEG Audio Kodierungsprinzip). AUTOEs gilt: Anzahl der in einem Fenster enthaltenen Abtastwerte = Anzahl der Subbands. Daraus folgt: Je grösser man die Fensterlänge wählt (hohe Anzahl an Abtastwerten), desto höher die Anzahl der Subbands, desto genauer die Maskierungsschwellwertanpassung und desto grösser die zu erzielende Kompressionsrate. Heisenberg Ungleichheit watk2001, 313Obiges lässt die Schlussfolgerung zu, mann muss nur möglichst große Fenster verwenden, um eine optimale Audiokompression zu erzielen. Die Ausdehnung der Fensterlänge hat aber ihre Grenzen, die durch die Heisenberg Ungleichheit gegeben sind. Die Heisenberg Ungleichheit besagt, dass...
Heisenberg für AudiokodierungFür die Audiokomprimierung bedeutet dies: Wählt man ein grosser Fenster, so hat man zwar eine sehr gute Frequenzauflösung und damit verbunden eine hohe Anzahl an Subbands, andererseits kann aber auf das Fenster im Zeitbereich nur als eine Einheit Einfluss genommen werden (=grobe Auflösung im Zeitbereich). So kann im Zeitbereich immer nur ein Wert für das Quantisierungsrauschen eingestellt werden, der über eine gesamte Fensterlänge konstant ist. Der Betrag des Quantisierungsrauschen ist durch die hohe Frequenzauflösung zwar sehr genau berechnet, aber er kann nicht an zeitlichen Signaländerungen innerhalb eines Fensters angepasst werden. Daraus resultiert bei zu langen Fenstern verstärkt der gefürchtete Pre-Echoeffekt. Switch-Funktion für Fensterlänge watk2001Für die Audiokodierung wird das Audiosignal in kleine Zeitabschnitte, in Fenster, unterteilt. Bei Layer I und II ist die Fensterlänge immer konstant. Bei MP3 hingegen kann die Hybridfilterbank mit verschieden langen Fenstern arbeiten (siehe Lerneinheit MPEG Audio Kodierungsprinzip). Grundsätzlich werden zwei verschieden lange Fenster verwendet:
Zusätzlich zu den beiden Fenster gibt es noch zwei Übergangsfenster, die einen sanften Übergang zwischen den beiden Fenstern erlauben. Quantisierung und Kodierung1AUTO
2Nichtlinearer QuantisiererIm Gegensatz zu Layer I und Layer II werden bei MP3 die Werte nichtlinear quantisiert. Dadurch werden große Werte gröber quantisiert, kleinere Werte feiner. Die nichtlineare Quantisierung an und für sich bewirkt schon, dass im Vergleich zur linearen Quantisierung bei gleichen wahrnehmbaren Quantisierungsrauschen mit kürzeren Wortlängen gearbeitet werden kann (siehe Lerneinheit Grundlagen der digitalen Audiotechnik). HuffmankodierungDie Daten aus dem Quantisierer werden einer Hufmannkodierung unterzogen. Häufig vorkommende Werte werden kurze Wortlängen zugeordnet. Um die Huffmankodierung effektiver zu nutzen, kann für ein Fenster für jedes Subband eine eigene Huffman Tabelle verwendet werden. Regelschleife für DatenrateAuch bei MP3 ist auf Grund der vom User vorgegebene Datenstromrate die Gesamtanzahl der Bitstellen für ein Fenster vorgegeben (siehe Bitstellenzuweisung). Erfordern nun die ermittelten Huffmanwerte mehr Bitstellen,so muss eine gröbere Quantisierung gewählt werden, erfordern sie weniger, kann die Quantisierung feiner eingestellt werden. In diesem Regelkreis werden auch die optimalen Skalierungswerte iterativ festgelegt Diese Prozedur wird sooft wiederholt, bis die passenden Quantisierungseinstellungen für alle Subbands gefunden sind. Passende Einstellungen zeichnen sich folgendermassen aus:
Variable Datenratenkodierung1AUTO
Bit Reservoir Technik PC
Bitreservoir Technik PDA_Phone
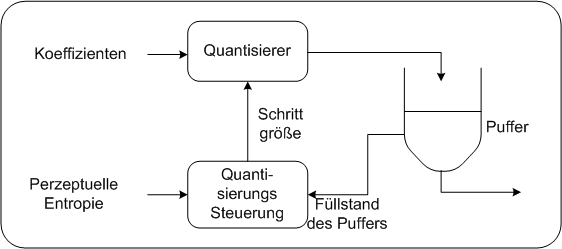
2AUTOMPEG/Audi fordert eine konstante Datenstromrate des komprimierten Signals. Daraus folgt für Layer I und II, dass jedem Fenster immer die gleiche Anzahl an Bitstellen zur Verfügung gestellt werden. MP3 bietet nun mit der Bit Reservoir Technik die Möglichkeit, dass aufeinander folgende Fenster ihre Bitstellen untereinander aufteilen können.
Bit Reservoir Technik PC
Der Puffer informiert die Quantisierungssteuerung laufend über seinen Füllstand.In der Phase, in der das bearbeitete Signal relativ regelmäßig verläuft, kann die Quantiserungssteuerung eine einen Hauch gröbere Quantisierung wählen, um den Puffer zu leeren. Wenn dann ein Fenster mit einem Ansprung des Signals kommt, kann der entleerte Puffer mit den aus dem Anstieg resultierenden großen Koeffizienten aufgefüllt werden, während davon völlig unbehelligt der Pufferausgang das Signal weiterhin mit konstanter Bitrate ausgegeben kann. Bit Reservoir Technik PDA_Phone
Der Puffer informiert die Quantisierungssteuerung laufend über seinen Füllstand.In der Phase, in der das bearbeitete Signal relativ regelmäßig verläuft, kann die Quantiserungssteuerung eine einen Hauch gröbere Quantisierung wählen, um den Puffer zu leeren. Wenn dann ein Fenster mit einem Ansprung des Signals kommt, kann der entleerte Puffer mit den aus dem Anstieg resultierenden großen Koeffizienten aufgefüllt werden, während davon völlig unbehelligt der Pufferausgang das Signal weiterhin mit konstanter Bitrate ausgegeben kann. Artifacts1AUTOArtifacts sind klangliche Störungen verursacht durch
Arten von ArtifactsVerlust der Bandbreite
Pre-EchoAbbildung: Pre-Echo PC
Abbildung: Pre-Echo PDA_Phone
Precho hörenRauhheit, Sprachverdopplung
Sprachverdopplung hörenStimme klingt verdopplet. play 2AUTOBei der perzeptuellen Audiokodierung wird danach getrachtet, dass nur jene Daten entfernt werden, die ohnehin nicht von unserem Gehör wahrgenommen werden können. Bei geringer Datenrate oder bei schlechten Encodern wird der Datenverlust aber als Artifacts hörbar. Arten von ArtefactsVerlust der Bandbreite bran2000, 7Wenn der Encoder mit den zur Verfügung stehenden Bitstellen nicht auskommt und auch die Iterationsalgorithmen zur Bitzuweisung kein befriedigendes Ergebnis liefern können, werden bestimmte Frequenzen einfach auf Null gesetzt, meistens die hohen. Bei Wiedergabe klingt das Signal dumpfer. Viel störender wirkt diese Artifact, wenn die Bandbegrenzung nicht konstant ist, sondern sich z.B. in 24ms Rythmus ändert. Dem Audiosignal wird ein störender Wowo-Effekt aufgeprägt. PreechoAbbildung: Pre-Echo PC watk2001, 291
Pre-Echo ist eine Artifact, die sich aus den Grundprinzipien der perzeptuellen Audiokomprimierungstechnik ergibt. Das maximal erlaubte Quantisierungsrauschen wird immer für ein Fenster berechnet und ist über dessen gesamte Länge konstant. Befindet sich innerhalb des Fensters ein starker Anstieg des Signals (Trommelschlag, Konsonant bei Sprache..), wird bei der Wiedergabe das Quantisierungsrauschen am Anfang des Fensters hörbar. Abbildung: Pre-EchoPDA_Phone
Abbildung: Pre-EchoPre-Echo ist eine Artifact, die sich aus den Grundprinzipien der perzeptuellen Audiokomprimierungstechnik ergibt. Das maximal erlaubte Quantisierungsrauschen wird immer für ein Fenster berechnet und ist über dessen gesamte Länge konstant. Befindet sich innerhalb des Fensters ein starker Anstieg des Signals (Trommelschlag, Konsonant bei Sprache..), wird bei der Wiedergabe das Quantisierungsrauschen am Anfang des Fensters hörbar. Precho hörenDas Pre-Echo wird von unserem Ohr als eine dem Ansteig vorausgehende, unschöne Rauschflanke empfunden. Besonders bei den Konsonanten wird das Preecho als ein störender Zischlaute wahrnehmbar. play Techniken zur Vermeidung des Pre-Echo Effektes
Rauhheit, Sprachverdopplung bran2000, 7Speziell bei niedrigen Bitraten und niedrigen Abtastfrequenzen kann der zeitliche Strukturverlauf des Signals nicht mehr korrekt wiedergegeben werden. Hörbar wird diese Artifact vorallem bei Sprachaufnahmen. Zur Verminderung dieses Effektes verwendet AAC das TNS Modul (siehe Lerneinheit MPEG-2 Audio: AAC). Sprachverdopplung hörenSpricht ein Sprecher, klingt seine Stimme verdoppelt: es klingt, wie wenn zwei Stimmen gleichzeitig sprechen würden. play |


| (empty) |