| Title: | MPEG Audiokodierungsprinzip | ||
|---|---|---|---|
| Abstract: | In dieser Lerneinheit werden die Grundprinzipien jener MPEG Audiocodierungstechnik beschrieben, die die perzeptuellen Eigenschaften unseres Gehörs für Datenkomprimierung nutzen. Ausgehend von einem einfach aufgebauten MPEG Decoder wird die Funktionsweise des Psychoakustischen Modells , die von MPEG verwendete 32-stufige Filterbank, die Technik der Skalierung und das im MPEG Standard festgelegte Datenstromformat näher erläutert. | ||
| Status: | Final for Review #2 - Captions missing | Version: | 2004-11- 05 |
| History: |
2004-11-05 (Thomas Migl): Acro added 2004-09-23 (Thomas Migl): Abb. explanations korrigiert 2004-08-16 (Robert Fuchs): Checked, fixed and exported for Review #2. 2004-08-03 (Thomas Migl): Inhalte in Greybox importiert, fertiggestellt 2004-03-12 (Robert Fuchs): Closed for 50% Content Deadline import in Scholion. 2004-03-11 (Thomas Migl): LOD1 header added 2004-03-08 (Robert Fuchs): Fixed sHeader that was applied via <span> instead of <p>; fixed sHeader that was applied to an image 2004-03-07 (Robert Fuchs): Fixed image file name ("layer1_bisteam" => "layer1_bitstReam") 2004-03-05 (Thomas Migl): Abstract hinzugefügt 2004-03-05 (Robert Fuchs): Put sources into CorPU title where neccessary; removed dummy entries for LOD 3; added links. 2004-02-27 (HTMLContentTools): Replaced old numeric source refs by new alphanumeric ones. 2004-02-26 (Robert Fuchs) - Upgrade from old LU 420, version 2003-12-03. 2004-02-25 (HTMLContentTools) - Created skeleton page. 2003-12-03 (Robert Fuchs): Import von Version 2003-08-23 aus HTML Authoring Systeme v.1 |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Organisation: Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einführung MPEG Audiokomprimierung1Subbandcodierung
Variable Quantisierung
Fenstertechnik
Psychoakustisches Modell
Skalierung
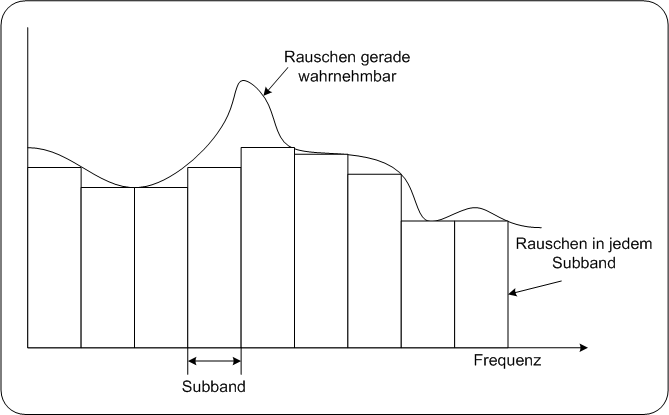
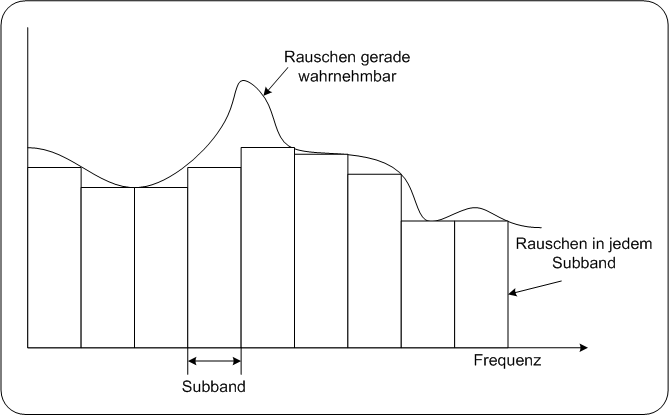
2Überblick MPEG AudiokodierungstechnikenMPEG-1 verwendet zur Audiokompression ausschließlich Algorithmen, die sich von den perzeptuellen Eigenschaften unseres Gehörs ableiten (siehe Grundlagen der perzeptuellen Audiokodierung). Bei Audio MPEG-2 gibt es zusätzlich Tools, die spezielle Prädiktionstechniken zur Kompression verwenden. (siehe TNS bei AAC).Mit diesen Tools ist auch eine verlustlose Komprimierung möglich. All diese Algorithmen arbeiten unabhängig von der Beschaffenheit des Audiosignals. In Audio MPEG-4 werden zusätzlich eigene Kompressionstechniken standardisiert, die darauf Rücksicht nehmen, ob es sich um eine Sprach- oder Musikaufnahme handelt. In dieser Lerneinheit werden die Grundprinzipien jener MPEG Audiocodierungstechnik beschrieben, die die perzeptuellen Eigenschaften unseres Gehörs für Datenkomprimierung nutzen .Ausgehend von einem einfach aufgebauten MPEG Decoder wird die Funktionsweise des Psychoakustischen Modells , die von MPEG-1 verwendete 32-stufige Filterbank, die Technik der Skalierung und das im MPEG Standard festgelegte Datenstromformat näher erläutert. SubbandcodierungMPEG 31 Audiokodierungstechniken, die auf den perzeptuellen Eigenschaften des Gehörs aufbauen, verwenden die Subbandkodierung. Mit Hilfe dieser können perzeptuelle Hörphänomene zu einer wesentlich höheren Datenreduktion beitragen. Der für die MPEG Audio Komprimierung wichtigste perzeptuelle Effekt ist dabei der Maskierungseffekt. Variable QuantisierungDer Schlüssel der MPEG Audiokomprimierung liegt in der Quantisierung, genauer gesagt, in der Wahl der passenden Quantisierungsgenauigkeit. Quantisierung für PCM SignaleBei der PCM 38 Kodierung wird mit einer für alle Audiosignale gültigen festgelegten Quantisierungsgenauigkeit gearbeitet. Jeder Wert wird mir der gleichen Wortlänge kodiert. Quantisierung in MPEG AudioIm Gegensatz dazu wird bei der MPEG- Audiokomprimierung mit variabler Quantisierung gearbeitet, d.h.es wird das Signal abschnittsweise mit verschiedenen Wortlängen kodiert. furt1995 FenstertechnikZur Bestimmung der Wortlängen wird das Audiosignal in kleine Abschnitte ( im Bereich von einigen Millisekunden) unterteilt. Diese Zeitabschnitte werden als Fenster bezeichnet. Jedes Fenster wird wiederum mittels Subbandkodierung in mehrere Frequenzbänder aufgeteilt. Für die Werte jedes Subbands werden die maximal erforderliche Wortlänge ermittelt. Psychoakustisches ModellZur perzeptuellen Bewertung der Subbands führt MPEG/Audio das psychoakustische Modell ein. Das psychoakustische Modell simuliert quasi das menschliche Gehör und dessen psychoakustischen Eigenschaften. Es untersucht, in welchen Subbändern maskierende Werte sind, berechnet daraus das maximal erlaubte Quantisierungsrauschen, sodaß es von unserem Gehör nicht wahrgenommen wird. Dadurch wird die maximal erforderliche Wortlänge für jedes Subband festgelegt. SkalierungNeben der Untersuchung von Maskierungseigenschaften spielt die Skalierung eine bedeutende Rolle in der MPEG/Audio Komprimierung . Bänder mit kleinen Werten, deren Werte keine nennenswerte Maskierungseigenschaften haben, werden vor der Kompression skaliert. So wird das von anderen Subbands eingeführte Quantisierungsrauschen bei der Wiedergabe gedämpft. Blockschaltbild einfacher MPEG-Kodierer1Abbildung: MPEG Encoder PC
Abbildung: MPEG Encoder PDA_Phone
Qualität des Encoders
2Abbildung: MPEG Encoder PC
Abbildung: MPEG Encoder PDA_Phone
Abbildung: MPEG EncoderDas Eingangssignal passiert eine Filterbank .(siehe auch Prinzip Filterbank). Diese teilt das Signal in mehrere Frequenzbänder auf. Parallel dazu gelangt das Signal zum Psychoakustischen Modell, welches den Maskierungsschwellwert für jedes Subband festlegt. Für die Werte jedes Subbands wird ein Skalierfaktor (siehe auch Prinzip der Skalierung) festgelegt. Bei der Bitzuweisung wird über die benötigte Wortlänge für jedes Subband entschieden.
Qualität des EncodersWährend des Kodiervorganges ist eine hohe Anzahl an Berechnungen notwendig. Allgemein gilt, je höher die gewünschte Qualität, desto zeitaufwendiger die Prozedur. Für Echtzeitanwendungen muss jeweils ein geeigneter Kompromiss gefunden werden. Allgemein gilt , dass der Standard in der Umsetzung der Aufgaben eines Kodierers den Entwicklern große Freiheiten lässt. Dadurch ist gewährleistet, dass keine Grenzen in Bezug auf erzielbare Qualität gesetzt sind. Jeder Entwickler kann seine eigenen Rechenstrategien einsetzen. Der Standard schreibt vor, welche Daten zu liefern sind, aber nicht, wie man zu diese zu kommen hat. Filter Bank1auto
Ideale Filterbank
MPEG Audio Polyphase Filterbank
2autoDamit man die Vorteile der Subbandkodierungstechnik nutzen kann, muss das Audiosignal zuerst mit Hilfe einer geeigneten Filterbank in seine verschiedenen Subbands aufgeteilt werden. Ideale FilterbankDie Bandbreiten der Subbands sollten idealerweise kleiner sein als die kritischen Bandbreiten unseres Gehörs. Um diese Bedingung vollständig erfüllen zu können, müsste man mit Filtern hoher Komplexität arbeiten. Eine weitere Schwierigkeit bei der Realisierung einer idealen Filterbank ist, dass die kritischen Bandbreiten unseres Gehörs stark frequenzabhängig sind. MPEG Audio FilterbankUm den Aufwand in Grenzen zu halten, arbeitet MPEG/Audio mit einer polyphasen Filterbank , dessen Filter relativ einfach aufgebaut sind. Das Audiosignal wird dabei in 32 Subbands gesplittet. Mit der Einfachheit handelt man sich allerdings Beschränkungen ein. Konstante BandbreitenDie Filterbank kann nur Subbands mit gleichen Bandbreiten erzeugen. Dadurch erstreckt sich im unteren Frequenzbereich ein Subband über mehrere Kritische Bandbreiten, bei hohen Frequenzen wiederum liegen mehrere Subbands im Bereich einer kritischen Bandbreite. Überlappende SubbandsBei der Filterung überlagern sich benachbarte Subbands. Das heisst, eine Signalkomponente, dessen Frequenz in unmittelbarer Nähe des Subbandübergangs liegt, wird es in beiden Subbands kodiert und so als zwei verschiedene Signale interpretiert. Das ist der Grund, dass eine polyphase Filterbank nicht verlustlos arbeiten kann. Es kann aus den Werten der 32 Subbands das Originalsignal nicht mehr 100prozentig rekonstruiert werden. Psychoakustisches Modell pan19961Aufgabe des psychoakustischem Modellls
ModelleDer MPEG Audio Standard bietet 2 exemplarische Implementationen von psychoakustischen Modellen:
Arbeitsweisen der psychoakustischen ModelleBeide Modelle berechnen mehrere Schwellwerte innerhalb eines Subbands und leiten daraus erst den endgültigen Schwellwert ab. Modell 2 setzt gegenüber dem Modell 1 dafür komplexere Algorithmen, verbunden mit einer höheren Genauigkeit, ein. Tonale/geräuschähnliche Komponenten
Eingangsdaten für Psychoakustisches ModellSubbandwerte
Fast Fourier Transformation
Zusammenfassung der Werte
FFT für Layer1 und Layer2Psychoakustisches Modell: Beispiel Rechenergebnis PC
Psychoakustisches Modell: Beispiel Rechenergebnis PDA_Phone
2Aufgabe des psychoakustischem ModelllsDie Aufgabe des psychoakustischen Modells besteht darin, für jedes Subband den Maskierungsschwellwert zu eruieren. Aus diesem errechnet es dann das maximal erlaubte Quantisierungsrauschen und damit die maximal benötigte Wortlänge der Werte dieses Subbands. ModelleContent Der MPEG Audio Standard bietet 2 exemplarische Implementationen von psychoakustischen Modellen:
Arbeitsweisen der psychoakustischen ModelleBeide Modelle berechnen mehrere Schwellwerte innerhalb eines Subbands und leiten daraus erst den endgültigen Schwellwert ab. Modell 2 setzt gegenüber dem Modell 1 dafür komplexere Algorithmen, verbunden mit einer höheren Genauigkeit, ein. Tonale/geräuschähnliche KomponentenWesentlicher Unterschied der beiden Modelle ist die Art und Weise, wie entschieden wird, ob es sich bei dem betrachteten Signalabschnitt um ein tonales, oder eher atonales Ereignis handlet. Die genaue Bewertung ist für eine gute Kompressionsqualität ausschlaggebend, da tonale und atonale akustische Ereignisse unterschiedliche Maskierungseigenschaften haben.
Eingangsdaten für Psychoakustisches ModellDas Psychoakustische Modell benötigt entsprechende Informationen über das zu kodierende Audiosignal. SubbandwerteAm einfachsten ist es es, direkt mit den Werten der Subbands zu arbeiten. Es werden alle Werte der 32 Subbands auf ihr Maskierungsverhalten untersucht. Für jedes Subband ergibt sich daraus ein maximaler Schwellwert. Diesen bestimmt das psychoakustische Modell als Maskierungsschwellwert für das gesamte Subband. Diese Methode ist sehr einfach, aber auf Grund der Tatsache, dass kritische Bandbreite und Subbandbandbreite sich nicht decken, ist auch das Ergebnis sehr grob. Weiters kann damit keine Analyse des Frequenzspektrums durchgeführt werden. Es kann nur mäßige Kompression erzielt werden. Fast Fourier TransformationUm eine feinere Berechnung der Maskierungsschwellwerte zu erhalten, wird im MPEG1 Audio eine Fast FourierTransformation (FFT) eingesetzt, die das Originalaudiosignal in seinem Frequenzspektrum darstellt. Im Vergleich zur Filterbank liefert die FFT eine viel feinere Frequenzauflösung des Signals. Es ist daher eine genauere Untersuchung der Maskierungseigenschaften des Signals möglich. Zusammenfassung der WerteUm den Rechenaufwand in Grenzen zu halten, fasst man Frequenzkomponenten, die innerhalb einer kritischen Bandbreite unseres Gehörs liegen, jeweils zu einer Frequenzgruppe zusammen. FFT für Layer1 und Layer2Siehe Layerstrukur des MPEG-1 Standards. Layer I verwendet eine 512-Punkt FFT, Layer II eine 1024-Punkt FFT. Die FFT stellt weiters dem psychoakustischem Modell 1+2 jene Werte zur Verfügung, die es benötigt, um zwischen tonale und geräuschähnliche Signalanteile unterscheiden zu können. Psychoakustisches Modell: Beispiel Rechenergebnis PC
Psychoakustisches Modell: Beispiel Rechenergebnis PDA_Phone
Festlegung des Skalierfaktors watk2001, 3081Funktionsweise Skalierung
SNR für Audio
Bestimmung der Skalierung
2Funktionsweise SkalierungSkalierung ist vor allem für Subbands wichtig, die nur kleine Werte enthalten. Durch die Skalierung werden sie vor der eigentlichen Kompression mit einem bestimmten Faktor mulitpliziert. So haben sie einen verbesserten SNR bezüglich des durch die nachfolgende Prozedur der Kompression eingeführten Quantisierungsrauschens. Auf Decoderseite werden die Werte wieder auf ihren ursprünglichen Wert zurück skaliert, aber der hohe SNR bleibt trotzdem erhalten, da das Rauschen im selben Maße gedämpft wird. SNR für AudioSNR steht für Signal to Noise Ratio und gibt das Verhältnis zwischen Nutz- und Störsignal an. Für Audiosignale bedeutet ein hoher SNR 396 Wert, dass nur wenig oder gar kein Rauschen hörbar ist, ein kleiner SNR Wert repräsentiert eine stark verrauschte Aufnahme. Maßeinheit ist das logarithmische Maß Dezibel. Bestimmung der SkalierungFür jedes Subband wird ein eigener Skalierfaktor errechnet. Zur Bestimmung
dieses Faktors wird der jeweils größte Wert des Subband (siehe Subbandkodierung)
genommen. In MPEG/Audio verwendet man einen 6-Bit Skalierfaktor, der
für jedes Subband im Datenstrom mitgespeichert werden muss. Zur originalgetreuen
Wiedergabe muss der Decoder die Werte durch den Skalierfaktor wieder
dividieren. Gleichzeitig wird auch das in diesem Subband eingeführte
Quantisierungsrauschen
um den selben Faktor reduziert. Bitzuweisung (Bit Allocation)1auto
Bitzuweisung bei hohe Datenraten
Bitzuweisung bei niedrigen Datenraten
MPEG Tabellen
2autoEin besonderes Feature des MPEG Audiostandards ist, dass der Benützer dem komprimierten Datenstrom eine bestimmte konstante Datenrate vorgeben kann. Durch diese Vorgabe ist die Gesamtanzahl der Bits für ein Fenster fix vorgegeben. Bitzuweisung bei hohe DatenratenDas Psychoakustische Modell hat für jedes Subband die maximal erforderliche Wortlänge errechnet, sodass kein Quantisierungsrauschen hörbar ist. Bei hohen Datenraten wird die Gesamtheit der Werte nicht mehr als die vorgegebenen Bitstellen benötigen, das Signal kann ohne Auftreten von Quantisierungsrauschen kodiert werden. Bitzuweisung bei niedrigen DatenratenBenötigt die Gesamtheit der Werte mehr Bitstellen als vorhanden, muss ein Kompromiss gefunden werden. Bei niedrigen Datenraten ist eine Einführung von Quantisierungsrauschen daher unumgänglich. Die Aufgabe bei der Bitzuweisung ist es nun, dieses Rauschen wohl zu dosieren. Iterationsalgorithmen bestimmen dabei, welche Subbands lange Wortlängen unbedingt brauchen, und welche auch mit kürzeren auskommen können, ohne dass die Qualität des Signals in allzu große Mitleidenschaft gezogen wird. MPEG TabellenDer MPEG/Audio Standard stellt für diese Prozedur Tabellen zur Verfügung. Diese Tabellen sind nur eine Empfehlung, es steht jedem Entwickler frei, mit eigenen Methoden zu arbeiten. Die Art der Bitzuweisung entscheidet maßgeblich über die klangliche Qualität des Kodierers. Datenstromformat und MPEG Audio Decoder1autoMPEG-1/Layer1: Datenstrom PC
MPEG-1/Layer1: Datenstrom PDA_Phone
autoMPEG-1/Layer1: Decoder PC
MPEG-1/Layer1: Decoder PDA_Phone
2autom Gegensatz zum Encoder sind Datenstromformat und Funktionsweise des Decoders im Standard zwingend vorgeschrieben. Hier gibt es keinerlei Freiräume für Entwickler. Nur so kann allgemeine Kompatibilität gewährleistet werden. autoMPEG-1/Layer1: Datenstrom PC
MPEG-1/Layer1: Datenstrom PDA_Phone
autoAbbildung: MPEG-1/Layer1: Decoder PC
Abbildung: MPEG-1/Layer1: Decoder PDA_Phone
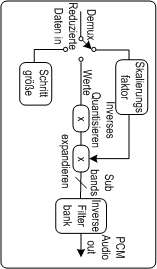
Abbildung: MPEG-1/Layer1: DecoderMan sieht, dass ein Decoder sehr einfach aufgebaut ist. Er übernimmt
einfach aus dem Datenstrom die Einstellungen für die Skalierung und
der Wortlänge der folgenden Subbandwerte und liest diese dann ein.
Eine inverse Filterbank mischt die Subbänder wieder zu einem PCM
38 Audiosignal.Bei der Decodierung sind
im Gegensatz zur Kodierung keinerlei Berechnungen notwendig. So ist
auch mit einfachen Decodern ein Echtzeitbetrieb ohne Qualitätseinbußen
möglich. |




| (empty) |