| Title: | Multimediale Datentypen | ||
|---|---|---|---|
| Abstract: | In dieser LU werden die Grundlagen der multimedialer Datentypen Text, Audio, Rasterbild, Vektorgraphik und Video erläutert. Nachdem Definition der Gemeinsamkeiten der verschiedenen Typen von Mediendaten, werden die Besonderheiten aller Datentypen in Bezug auf ihre Struktur und Abfragemöglichkeit präsentiert. | ||
| Status: |
|
Version: | 7.0 |
| History: |
MH1,",- checken done. LOD 1 done Rechtschreibung gecheckt (LOD1+2) Link auf LU Digitalisierung von Audiosignalen in Modul 1 done. Unbekannte Character gecheckt. |
||
| Author 1: | Bernhard Tatzmann | E-Mail: | bernhard@isys.uni-klu.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Universität Klagenfurt - Institut für Informatik-Systeme | ||
Gemeinsamkeiten von Mediendaten1Einleitung
Beispiel für formatierte InformationPlanetenName = "Saturn", Durchmesser = "60268", AnzahlMonde = "33" Beispiel für unformatierte InformationDer Name des Planeten lautet Saturn. Sein Durchmesser beträgt 60.268km. Er besitzt 33 Monde. Auto
Neben unformatierten Daten enthalten Mediendaten auch formatierte Daten:
2EinleitungAllen Mediendaten gemeinsam ist, dass es sich dabei um unformatierte Daten handelt. Dies unterscheidet sie von formatierten Daten, die z.B. in Feldern und Relationen gespeichert sind. Durch diese Strukturierung werden die Daten zwar leichter durchsuchbar gemacht, ihre Semantik jedoch, wie später noch erklärt wird, deutlich reduziert. Unformatierte Daten treten hingegen als Ketten von Einzelwerten auf, deren implizite Struktur dem Verarbeitungssystem nur ansatzweise bekannt ist. So kann eine Gruppierung von Textzeichen zu Wörtern und Sätzen wenig zu einer Abfrage beitragen, wie sie z.B. in relationalen Datenbanken erfolgt. Beispiel für formatierte InformationPlanetenName = "Saturn", Durchmesser = "60268", AnzahlMonde = "33" Beispiel für unformatierte InformationDer Name des Planeten lautet Saturn. Sein Durchmesser beträgt 60.268km. Er besitzt 33 Monde. AutoDie formatierten Daten sind in Feldern gespeichert, die durch Namen beschrieben werden. Trotzdem bleiben manche Informationen, wie z.B. die Einheit des Feldes Durchmesser, ohne weitere Metainformationen (wie z.B. eine Tabellenbeschreibung, in der definiert wird, dass Durchmesser in km anzugeben sind) unklar. Wie man sieht, weisen die Daten in der unformatierten Form einen größeren Informationsgehalt auf als jene in der formatierten Form. Die Abfrage der Daten (z.B. mit Hilfe von Ähnlichkeitsmaßen) gestaltet sich jedoch schwieriger. Der Vorgang einer Abfrage unformatierter Daten wird Information Retrieval genannt und wird in MMDBMS Retrieval und Abfragen näher beschrieben. Neben der großen Menge unformatierter Daten enthalten Mediendaten aber auch formatierte Daten. Meyer-Wegener nennt diese Registrierungsdaten und identifizierte Daten Mey03. Während Registrierungsdaten Informationen zur korrekten Interpretation eines Textes, wie z.B. Formatierungen, darstellen, geben identifizierte Daten zusätzliche Informationen, die zur Zuordnung der Daten zu Objekten in der realen Welt dienen. Identifizierte Daten können z.B. Röntgenbilder einer bestimmten Person zuweisen. Text1Einleitung
StrukturZwei verschiedenen Arten von Zeichen:
Abfrage
2EinleitungIm Zusammenhang mit multimedialen Datentypen erscheint es seltsam, von Text zu sprechen. Jedoch handelt es sich auch bei Text, wie schon im Abschnitt "Gemeinsamkeiten von Mediendaten" zu erkennen war, um unformatierte Daten, die sich nur anhand von Ähnlichkeitsmaßen durchsuchen lassen. Somit stellt Text die einfachste Form eines multimedialen Datentyps dar. StrukturTexte bestehen aus zwei verschiedenen Arten von Zeichen: lesbare Zeichen, die Bestandteil des Inhalts sind, und Steuerzeichen, die sich auf das Erscheinungsbild des Textes auswirken. Text weist den geringsten Speicheraufwand aller Typen von Mediendaten auf. Meist werden für die Speicherung 8 Bit je Zeichen aufgewendet, wie es auch bei den gebräuchlichen ISO389-8859 Zeichensätzen der Fall ist. Diese haben den ASCII28 Standard (7Bit) abgelöst und werden selbst bald vom neueren Unicode Standard (16Bit) bzw. vom Universal Character Set (UCS482, ISO389-10646, 32 Bit) verdrängt werden. AbfrageDie Abfrage von Textdateien erfolgt prinzipiell mit Hilfe von Volltextsuche. Des Weiteren kann zusätzlich eine Indizierung mit Schlagwörtern erfolgen, die zusätzliche, nicht im Text enthaltene Suchbegriffe beinhaltet. Eine Beschreibung dieser Methoden findet sich in MMDBMS Retrieval und Abfragen und den folgenden. 3OperationenZur Verarbeitung von Text werden folgende Operationen benötigt:
Audio1Einleitung
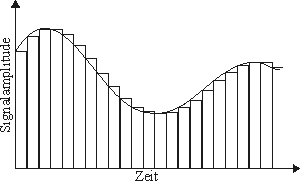
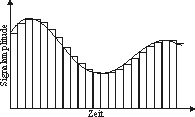
StrukturPulse Code Modulation (PCM38):
Auto PC
Auto PDA_Phone
Auto
AbfrageAbfrage von Audiodaten funktioniert prinzipiell über Mustererkennung (engl.: pattern matching) Es können folgende Merkmale zur Suche verwendet werden:
2EinleitungAudiodaten lassen sich vielseitig zur Informationsrepräsentation einsetzten. Sie können entweder alleine oder in Form von Text- oder Bildannotationen eingesetzt werden. Digitale Audiodaten treten heutzutage in den verschiedensten Bereichen wie Unterhaltungselektronik, Telefonsystemen oder Computerspielen auf. Um Audiodaten automatisiert abfragen zu können, müssen diese in einer geeigneten digitalisierten Form vorliegen. StrukturDie verbreitetste Form der Digitalisierung von Audiodaten, welche auch in LU Digitalisierung von Audiosignalen in Digitalisierung von Audiosignalen beschrieben wird, ist die Pulse Code Modulation (PCM38) (siehe folgende Abbildung). Bei dieser Methode wird ein kontinuierliches Audiosignal in festgelegten Zeitabständen abgetastet und dessen Amplitude gespeichert. Die Zeitabstände ergeben sich durch die Abtastrate (engl.: sampling rate), die doppelt so hoch wie die höchste im Signal vorkommende Frequenz sein muss. Dies ist nötig, um das abgetastete Signal wieder korrekt rekonstruieren zu können JN84. Um also eine Signalfrequenz von 22kHz korrekt abzutasten, ist eine Abtastrate von mindestens 44kHz nötig. Die zweite Kennzahl neben der Abtastrate ist die Auflösung. Sie gibt an, auf wie viele diskrete Zahlenwerte das kontinuierliche Spektrum der Signalamplitude abgebildet wird. Eine Auflösung von 8 Bit erlaubt eine Darstellung von 256 verschiedenen Amplitudenwerten. Auto PC
Auto PDA_Phone
AutoDa z.B. ein Stereosignal bei einer Abtastrate von 44kHz und einer Auflösung von 8 Bit pro Spur schon 85,93 KB pro Sekunde (5,04 MB/min) benötigt, ist leicht ersichtlich, dass hier Komprimierungsverfahren zur Anwendung kommen müssen, um die großen Datenmengen in den Griff zu bekommen. Der prominenteste Vertreter der Audio-Codierungsverfahren ist MP395 (MPEG Layer III). Das Verfahren beruht auf der FFT417 (Fast Fourier Transformation) sowie auf einem psychoakustischen Modell, das beschreibt, welche Töne vom menschlichen Gehör weniger stark wahrgenommen werden und somit "weggelassen" werden können. Ebenso können Redundanzen zwischen den beiden Stereokanälen berücksichtigt werden, was den Komprimierungsfaktor noch weiter steigern kann. Für weiterführende Information zu MP395 siehe LU MP3 sowie Ste99. Eine alternative Repräsentationsform von Audiodaten nennt sich MIDI30 (Music Instrument Digital Interface). Es beschreibt einen Standard, um Musikinstrumente untereinander und mit Computern zu verbinden. Bei MIDI30 werden keine Wellensignale übertragen, sondern Daten die die spezifischen Eigenschaften der Töne, wie z.B. das zu verwendende Instrument, die Klangdauer sowie die Tonhöhe, beschreiben. Beim Abspielen der Daten wird die Musik dann aus den gespeicherten Informationen "synthetisiert". AbfrageDie Abfrage von Audiodaten funktioniert prinzipiell über Mustererkennung (engl.: pattern matching). Um die Suchparameter besser anpassen zu können, wird eine Klassifikation in die verschiedenen Gruppen von Audiodateien wie Sprache, Musik und Geräusch durchgeführt. Prinzipiell können folgende Merkmale zur Suche verwendet werden:
Für weiterführende Informationen zur Abfrage von Audiodateien sei auf Mey03 verwiesen. Rasterbild1EinleitungRasterbilder entstehen durch:
Struktur
AbfrageTechniken zur Suche in Rasterbildern:
2EinleitungWerden Daten mittels Scanner oder CCD108 Kamera erfasst, so werden sie zumeist als Rasterbild abgespeichert. Rasterbilder können aber ebenso durch Umwandlung von Grafiken oder Text künstlich erzeugt werden. Für die Bearbeitung von derartigen Bildern steht eine Vielzahl von Verfahren in Form von Effekten, Filtern und Analysemethoden in den verschiedensten Softwareprodukten zur Verfügung. StrukturEin Rasterbild besteht aus einer beliebig großen Matrix von Bildpunkten (engl.: pixel312s). Während für Schwarzweiß-Bilder ein einziges Bit pro Bildpunkt ausreicht - solche Bilder nennt man auch Bitmaps, sind für Graustufen- oder Farbbilder mehrere Bits pro Pixel nötig. Die Anzahl der verwendeten Bits ist für jeden Bildpunkt gleich und wird auch Pixeltiefe genannt. Für Graustufenbilder werden üblicherweise 8 Bit pro Pixel verwendet, womit 256 verschiedene Grauwerte dargestellt werden können. Verwendet man für Farbbilder im RGB302 (Rot Grün Blau) - Format ebenfalls 8 Bit pro Farbkanal, so können mit einer Pixeltiefe von 24 Bit pro Pixel 16,7*10^6 Farben erzeugt werden. Für ein Farbbild mit den Abmessungen 640x480 unter einer Farbtiefe von 24 Bit werden 900 KB Speicherplatz benötigt. Neben dem oben erwähnten RGB302 Farbmodell, das für Ausgabegeräte verwendet wird, welche aktiv Licht produzieren (additive Farbmischung; z.B.: Monitore, Fernseher), existiert auch das CMY483 (Cyan Magenta Yellow) - Modell. Dieses wird zur passiven Farbmischung, welche z.B. bei Druckern zur Anwendung kommt, verwendet. Außerdem existieren noch weitere Farbmodelle wie z.B. IHS484 (Intensity Hue Saturation), YUV304 und YIQ305, die in den LUs Wahrnehmungsorientierte Farbmodelle und Hardwareorientierte Farbmodelle und in Ste00 näher beschrieben werden. Neben der oben erwähnten Methode der Speicherung von Farbwerten in Form von absoluter Farbdefinition jedes Pixels, gibt es noch die Möglichkeit der Verwendung einer eigenen Farbtabelle. Eine solche Tabelle speichert alle in einem Bild vorkommenden Farben und ermöglicht, dass pro Pixel nur noch mit Hilfe eines Indexes auf die entsprechende Farbe in der Tabelle verweisen werden muss. Pro Pixel werden somit nur mehr so viele Bits benötigt, wie zum Verweis auf die Tabelle nötig sind. Je geringer die Anzahl der verschiedenen Farben in einem Bild ist, desto größer ist die Platzersparnis. AbfrageDie Abfrage von und die Suche in Rasterbildern ist kompliziert und aufwendig. Die Techniken lassen sich in vier Klassen unterteilen Mey03:
Eine Beschreibung dieser Methoden findet sich in MMDBMS Retrieval und Abfragen und folgenden. Vektorgraphik1EinleitungExplizite Definition der einzelnen graphischen Objekte:
Struktur
Abfrage
2EinleitungVektorgraphiken enthalten im Gegensatz zu Rasterbildern graphische Objekte nicht implizit durch Pixelfärbungen, sondern durch explizite Definition der einzelnen Objekte. Für jedes Objekt werden die nötigen Daten zur Positionierung, Färbung, Schattierung und Beschriftung gespeichert. StrukturDa eingangs erwähnt wurde, dass eine Gemeinsamkeit von Mediendaten die Unformatiertheit der Daten ist, müssen Graphiken als ungeordnete Menge von Linien, Flächen und Beschriftungen gesehen werden Mey03. Als Attribute können Strichart, Strichstärke und Farbe auftreten. Außerdem ist, um die Graphiken wieder eindeutig reproduzieren zu können, die Angabe von Registrierungsdaten, wie z.B. dem verwendeten Koordinatensystem, nötig. AbfrageDurch die Tatsache das Objekte explizit mitsamt ihren Eigenschaften in Vektorgraphikdateien abgespeichert werden gestaltet sich die Suche leichter als bei den Rasterbildern. Somit gestaltet sich die Suche nach einer bestimmten geometrischen Figur in einer bestimmten Farbe leichter als bei Rasterbildern. Ebenso können aber auch zusätzliche Daten, die den Graphiken zugeordnet sind, zur Abfrage herangezogen werden. Video1Einleitung
Struktur
Abfrage2 Möglichkeiten:
Metadaten:
2EinleitungVideodaten beinhalten die beiden zuvor erwähnten Datenformate Audio und Bild. Um für den Betrachter die Illusion eines Bewegtbildes zu gewährleisten, ist eine minimale Bildrate (Anzahl der Bilder pro Sekunde) von 16 Bildern/Sekunde nötig. Verwendet werden jedoch meist 25 bzw. 30 Bilder/Sekunde. Zur gleichzeitigen Darstellung von Bild und Ton muss der Bildstrom außerdem mit dem Audiostrom synchronisiert werden. StrukturEin Videostrom im PAL167-Format (768x567) und einer Bildrate von 25 Bildern/Sekunde erreicht eine Datenrate von 1,26 MB/Bild x 25 Bilder = 31,64 MB/s. Betrachtet man diese Werte, so kann man sehen, dass eine Datenkomprimierung bei Videodaten unerlässlich ist. Zwei der prominentesten Vertreter sind hier das Motion JPEG Verfahren, welches jedes einzelne Videobild JPEG29 (siehe JPEG) komprimiert, sowie MPEG31, welches zusätzlich die Ähnlichkeiten bzw. Differenzen zwischen auf einander folgenden Bildern berücksichtigt. Weitere Normen sind H.261 (Videotelefonie), MPEG31-2 (siehe Der MPEG-2 Standard; wird für DVD311 verwendet), MPEG31-4 (siehe MPEG-4)und DivX323. Da die einzelnen Formate in Modul 4 ausführlich beschrieben werden, wird hier nicht näher auf sie eingegangen. MPEG31-7 verwendet im Gegensatz zu den oben genannten Formaten kein neues Komprimierungsverfahren, sondern bietet die Möglichkeit zusätzliche Metadaten abzulegen. Diese können dann zur Informationssuche verwendet werden. Für eine genaue Beschreibung von MPEG31-7 siehe MPEG-7 und MMDBS . AbfrageEine Möglichkeit der Abfrage ist die Extraktion von Einzelbildern und eine anschließende Behandlung der Bilder auf Basis der Rasterbildmethoden. Zur Suche in zusammenhängenden Videodaten sind die oben beschriebenen Metadaten notwendig. Sind solche vorhanden so können diese zur Informationssuche herangezogen werden. Die einfachste Form von Metadaten sind textuelle Inhaltsbeschreibungen. Man unterscheidet hier zwischen händisch erzeugten und automatisch generierten Daten. Automatisch generierte Metadaten können durch Algorithmen erzeugt werden, die bestimmte Merkmale aus den Videodaten extrahieren können. Je nach dem wie die Metadaten abgeleitet werden unterscheidet man zwischen inhaltsabhängigen (engl.: content-dependent), inhaltsbeschreibend (engl.: content-descriptive) und vom Inhalt unabhängigen (engl.: content-independent) Metadaten. Bibliographie2BibliographieJN84 KB96 Mey03 Pra97 Ste99 |
| (empty) |