| Title: | MPEG-4 Audio | ||
|---|---|---|---|
| Abstract: | MPEG-4 beschreibt neben Kodierung von natürlichen Audio auch die von synthetischen Klängen. Weiters führt MPEG-4 den Begriff „Strukturelles Audio“ ein, welches ein Audiosignal als eine Komposition verschiedener Audioobjekte (Sprache, Musik etc.) betrachtet. Die Lerneinheit bietet einen Überblick über die von MPEG-4 eingeführten Tools, als Beispiel der von MPEG-4 neu eingeführten Sprachkodierung wird ein CELP Kodierer näher betrachtet. | ||
| Status: | Final for Review #2 -1 PDA Abb. fehl1 (Grafik MPEG-4 audio) | Version: | 2004-11-04 |
| History: |
2004-02-22 (Martin Hon): 2 Sources in einem xSource bei CorPU CELP 2004-02-22 (Martin Hon): pere2000 existiert nicht korrektur zu pere2002 2004-11-04 (Thomas Migl): acro added 2004-10-14 (thomas migl): pda Abb. hinzugefügt 2004-09-17 (Thomas Migl): pda abb. hinzugefügt 2004-09-09 (Thomas Migl): Abb. Blockschaltbild hinzugefügt 2004-08-16 (Robert Fuchs): Checked, fixed and exported for Review #2. 2004-07-30 (Thomas Migl): Abb-finalPC importiert +++ ABGESCHLOSSEN:TextLOD1 +LOD2, , Abstract; 1xLOD3 (CELP), Summary 2004-07-22 (Thomas Migl): TextLOD1 +LOD2, Abstract; 1xLOD3 (CELP) |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einleitung watk2001-1,2151
2So wie MPEG-4 Video neben der Kodierung natürlicher Videosequenzen zusätzlich die Kodierung von Graphischen Elementen und Animationen definiert, definiert MPEG-4 Audio neben der Kodierung natürlicher Audiosignale auch die von synthetischen Klängen. MPEG-4 führt weiters das Prinzip des strukturellen Audios ein. Strukturiertes Audio1auto
Tonstudio
2Ein Audiosignal kann aus mehreren Objekten bestehen. Objekte können dabei verschiedene Musikinstrumente, verschiedene Sprecher, synthetische Klänge, Geräusche etc sein. Jedes Objekt wird in einem eigenen Datenstrom kodiert. Zur Übertragung werden diese Datenströme in einem einzigen MPEG-4 Datenstrom verpackt. Die Aufgabe des Decoders ist nun nicht mehr auf die reine Wiedergabe beschränkt, sondern er übernimmt zusätzlich das Rendering der verschiedenen Datenströme. Durch Setzen verschiedener Parameter am Encoder kann der Enduser so auf das Audiomaterial interaktiv zugreifen, einzelne Objekte herausfiltern oder klanglich verändern. Strukturiertes AudioIn einem Tonstudio werden mit Hilfe eines Mischpultes verschiedene Tonkanäle (mit Mikrofon aufgenommene natürliche Klänge, Singstimmen, Musikinstrumente, synthetisch erzeugte Klänge, natürliche Geräusche etc) zu einer einzigen Audiodatei zusammengemischt. Diese kann dann als ein Datenstrom kodiert und weiterverwendet werden (zum Beispiel zur Produktion eine Audio CD). Bei strukureller Kodierung wird kein Mischpult benutzt, sondern es wird jeder Kanal als Objekt aufgefasst und unabhängig von den anderen kodiert. Anschließend werden die so entstandenen Objekt-Datenströme. in einen einzigen MPEG-4 Datenstrom verpackt. Dieser Datenstrom bietet zwei entscheidende Vorteile:
MPEG-4 Audio Tools pere2002,501Allgemeine AudiokodierungErweiterung des AAC Encoders durch neue Tools
Sprachkodierung
Kodierung von synthetisch erzeugten Klängen
Synthetische Sprachkodierung
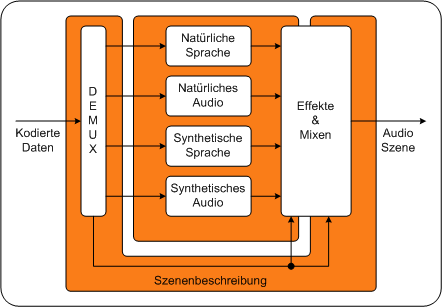
Grafische Darstellung MPEG-4 Audio: Tools und strukturiertes Audio PC
Grafische Darstellung MPEG-4 Audio: Tools und strukturiertes Audio PDA_Phone
2Dieser Abschnitt bietet einen Überblick der vom MPEG-4 Standard definierten Tools. Allgemeine AudiokodierungDie Kodierung natürlicher Audiosignale basiert streng auf dem AAC Encoder der im MPEG-2 Standard definiert ist. MPEG-4 bietet für den AAC neue Tools, die einerseits die Kompressionseigenschaften weiter verbessern, andererseits neue Anwendungsmöglichkeiten eröffnen.
SprachkodierungSpeziell zur Kodierung von Sprache werden im MPEG-4 Standard geeignete Algorithmen definiert. Mit diesen kann Sprache mit einer Datenrate von nur 2kbit/s bis 24 kbit/s übertragen werden.Für die Sprachkodierung werden zwei Standards verwendet: HVXC (Harmoniv Vector eXcitation Code) und CELP (Code Excitat Linear Prediction). Beide basieren auf dem Prinzip der Vektorquantisierung. In dieser Lerneinheit wird der CELP Kodierer genauer beschrieben. Kodierung von synthetisch erzeugten KlängenSynthetische Klänge können durch für sie spezifische Parameter dargestellt werden. Als Beispiel für die Kodierung von synthetischen Klängen sei hier das alt hergebrachte MIDI 30Format angeführt, das auch in den MPEG-4 Standard aufgenommen wurde. Musik wird dabei durch die darin vorkommenden Töne beschrieben. Jeder Ton wird für die Kodierung durch seine Tonlänge, Tonhöhe, Lautstärke und seinem Klang gekennzeichnet. Zu beachten ist, dass bei synthetischen Objekten der Klang erst im Decoder erzeugt wird und daher die Klangqualität nur von der Qualität des Decoders abhängig ist. Derart kodierte Datenströme benötigen eine äußerst geringe Datenrate. Synthetische SprachkodierungHierbei handelt es sich um die so genannten TTS(Text- to - Speech) Tools. Es wird dabei ein synthetischer Vorleser kreiert. Diese Sprachsynthesizer werden durch verschiedenste Parameter gesteuert: Phonemlänge, Sprachmelodie etc. Durch die Vielfalt der Parameter kann der Eindruck einer natürlichen Sprache erzeugt werden. Die Datenraten liegen zwischen 200bit/s und 1,2kbit/s. Grafische Darstellung MPEG-4 Audio: Tools und strukturiertes Audio
Grafische Darstellung MPEG-4 Audio: Tools und strukturiertes Audio PDA_Phone
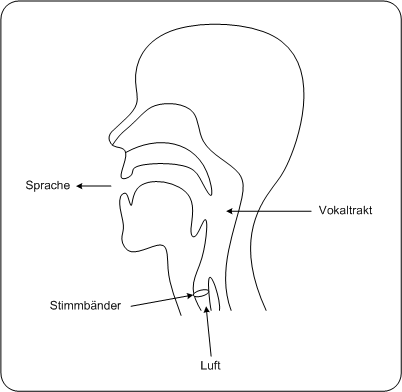
Sprachkodierung pere2002,50 data20001Entstehung menschlicher Sprache PC data2000
Entstehung menschlicher Sprache PDA_Phone data2000
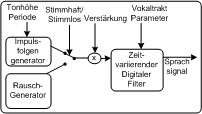
LPC Vocoder PC pere2002
LPC Vocoder PDA_Phone pere2002
2Entstehung menschlicher SpracheWenn wir sprechen, passiert Folgendes:
Abbildung: Entstehung menschlicher Sprache PC data2000
Abbildung: Entstehung menschlicher Sprache PDA_Phone data2000
LPC VocoderLPC steht für Linear Predictive Coding. Der LPC Vocoder simuliert unsere Stimmbänder, Stimmtrakt etc. Durch Steuerung mit entsprechenden Parametern kann der LPC 506 Vocoder menschliche Sprache erzeugen. Er benötigt dazu nur eine sehr niedrige Datenrate (typisch 800 bis 1200bit/s) LPC Vocoder PC pere2002
LPC Vocoder PDA_Phone pere2002
CELP watk2001-1pere20021Sprachaufnahme
Sprachwiedergabe
Kodierung des Prädiktionsfehlers
Weitere Features von CELP
2CELP steht für Code-Exited Linear Prediction. CELP ist die heute am meist gebräuchliche Sprachkodierung. Sie stellt eine Erweiterung der LP Kodierung dar. Mit CELP kann mit Datenraten von 4 bis 16 kbit/s eine Sprachqualität erzeugt werden, die in etwa einer analogen Telefonübertragung entspricht. SprachaufnahmeBei einer Analyse des Signals werden die Parameter gesucht, mit dessen Hilfe ein Sprachvocoder ( ähnlich aufgebaut wie der oben beschriebene LPC Vocoder) das Gesprochene möglichst genau simulieren kann. Anschließend wird die Differenz zwischen dem Originalsignal und dem durch den Sprachvocoder erzeugte Signal gebildet. Dieses Differenzsignal stellt den Prädiktionsfehler (Restsignal) dar. Die Parameter und der Prädiktionsfehler werden kodiert. SprachwiedergabeBei der Wiedergabe erzeugt der Sprachvocoder mit Hilfe der übertragenen Parameter ein synthetisches Sprachsignal. Die Rekonstruktion des Originalsignals entsteht durch Summation dieses Signals und dem Prädiktionsfehler. Kodierung des PrädiktionsfehlersZur effektiven Kodierung des Prädikitionsfehler verwendet CELP ein Codebuch. Dieses beinhaltet einige hundert typische zeitliche Verläufe von Restsignalen. Jedes Restsignal hat dabei eine Länge von 5 bis 10ms. Ein spezieller Suchalgorithmus entscheidet, welches Restsignal aus dem Kodebuch dem tatsächlichen am besten entspricht. Kodiert wird dann der Index des gefundenen Restsignals. Weitere Features von CELPSkalierbarkeitMPEG-4 CELP erlaubt nicht nur eine Vielzahl an unterschiedlich hohen Datenraten, sondern bietet auch die Möglichkeit, die unterschiedlichen Datenraten in einen einzigen MPEG-4 Datenstrom zu verpacken. Diese Eigenschaft wird als Skalierbarkeit bezeichnet. Solch ein MPEG-4 Datenstrom ist in mehreren Schichten aufgebaut. In der Basisschicht ist das Signal für die geringste Bitrate kodiert. In den weiteren Schichten sind Detailinformationen enthalten, mit deren Hilfe der Decoder aus dem Basissignal die Signale höherer Datenbitrate regenerieren kann. So kann einerseits bei Breitbandübertragung die volle Sprachqualität eines Signals ausgenutzt werden, andererseits kann dasselbe Signal auch über einen Nachrichtenkanal mit beschränkter Bandbreite übertragen werden (natürlich mit verminderter Qualität). StillekompressionIn diesem Modus ist die erzeugte Bitrate des CELP Encoders nicht mehr konstant, sondern variabel. Für Signalabschnitte, in welcher Stille herrscht, wird die Bitrate auf ein Minimum reduziert. Da in der menschlichen Sprache kurzzeitige Stille sehr häufig vorkommt, wird durch die Variabilität der momentanen Bitrate auch die durchschnittliche Bitrate wesentlich reduziert. 3weiterführende LinksWeiterführende Beschreibung zur Sprachkodierung Hörbeispiele für CELP Zusammenfassung12Zusammenfassung MPEG-4 AudioMPEG-4 Audio bietet einerseits Erweiterungen des MPEG-2 AAC Standards, andererseits führt es den Begriff des strukturierten Audios ein. Es werden dabei verschiedene Quelltypen von einander getrennt und auf unterschiedliche Weise kodiert. Als Quelltypen sind im MPEG-4 Standard natürliches Audio, menschliche Sprache, synthetisch erzeugte Sprache und synthetisch erzeugte Klänge definiert. Für die Kodierung natürlichen Audios gibt es verbesserte Tools, die im Vergleich zu MPEG-2 AAC geringere Datenraten bei gleichbleibender Qualität bieten. Auch gibt es die Möglichkeit, den Audiodatenstrom zin unterschiedlichen Skalierungsgrade in einen Datenstrom zu verpacken. Bei der Sprachkodierung spielt der CELP Encoder eine wichtige Rolle. Mit seiner Hilfe kann man natürliche Sprache mit äußerst geringer Datenrate übertragen. |


| (empty) |