| Title: | Datenplatzierung | ||
|---|---|---|---|
| Abstract: | Magnetische Laufwerks sind die wichtigsten Speichergeräte in Computersystemen. Wie und wo die Daten physisch auf den Laufwerken gespeichert werden, hat einen großen Einfluss auf die Gesamtperformance eines Systems. Man unterscheidet zwischen Block- und Dateienplatzierung. Blockplatzierungsstrategien haben zum Ziel, den zeitlichen Overhead, der während eines Abrufvorgangs von Daten einer magnetischen Disk entsteht, möglichst gering zu halten. Dateienplatzierungsstrategien arbeiten in einem System mit mehreren Laufwerken und haben die Aufgabe, für jede Datei das passende Speichergerät zu finden. Weiters obliegt ihnen die Entscheidung, wie viele Kopien einer Datei vorhanden sein müssen, um eine optimale Performance zu erzielen. | ||
| Status: | under construction | Version: | 2005-10-17 |
| History: |
2005-10-17 (Thomas Migl): Def. "strand-based Allocation"
korrigiert |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einleitung1Motivation
Grundlegende Unterscheidung für Datenplatzierung
2MotivationDie Magnetische Disk ist heute unangefochten der wichtigste Massenspeicher für Computersysteme. Und wie es aussieht, wird sie diese Vormachtsstellung nicht so schnell verlieren: Ihre Kapazität/Kostenentwicklung macht sie zum sicheren Kandidaten auch für zukünftige Multimedia Anwendungen. Die Magnetische Disk hat nur einen entscheidenden Nachteil: Die möglichen Datentransaktionsraten sind nur mäßig und hinken den in anderen Teilen des Computersystems üblichen stark nach. Dieser Nachteil wird besonders bei Multimedia Anwendungen schlagend, da ein Multimedia Server die Möglichkeit haben muss, verschiedene Daten direkt von der Disk zeitgleich an unterschiedliche Clients zu übertragen, und zwar unter Einhaltung das Quality of Service Parameter (QoS). Wie und wo welche Daten physisch auf der Magnetplatte gespeichert werden, hat nun einen großen Einfluss darauf, wie weit einem geforderten QoS trotz beschränkter Datentransferrate nachgekommen werden kann. Eine zweite wichtige Aufgabe der Datenplatzierungsstrategien ist es, die Daten in einem Verbund von Speichergeräten möglichst ressourcenoptimiert zu platzieren. Grundlegende Unterscheidung für DatenplatzierungGrundsätzlich sind für die Platzierung von Daten zwei Kategorien zu unterscheiden:
Überblick LerneinheitEinleitend wird ein Überblick über die Terminologie der magnetischen Disk gegeben und Begriffe erläutert, die zum Verständnis des Inhaltes dieser Lerneinheit wichtig sind. Anschließend werden verschiedene Blockplatzierungsstrategien beschrieben, wobei zu beachten ist, dass alle in dieser Lerneinheit beschriebenen Blockplatzierungsstrategien sich auf die Speicherung von Blöcken auf einer einzigen magnetischen Disk beziehen. Wie Blöcke einer Datei strategisch sinnvoll auf mehrere Laufwerke aufgeteilt werden können, wird in der Lerneinheit RAID Speichersysteme (Stichwort Striping) beschrieben. Bezüglich Dateienplatzierungsstrategien wird ein Überblick über Anforderungen und Arbeitsweisen, die für alle Dateienplatzierungsstrategien gültig sind, geboten. Abschließend werden die popularitätsbasierte und die BSR Strategie genauer beschrieben. Disk Terminologie Chen1994,1471Diskaufbau Magnetische Disk [chen1994] Performance Maße einer Disk zaia1998
Definition Block
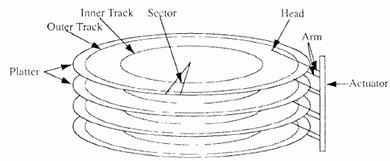
2DiskaufbauDie Abbildung zeigt die Komponenten einer einfachen Magnetischen Disk. Sie besteht aus einer Gruppe von Platten (Platter), die mit einem magnetischen Material beschichtet sind. Die Platten sind auf einer gemeinsamen, sich mit konstanter Winkelgeschwindigkeit drehenden Spindel befestigt. Für jede Plattenoberfläche gibt es einen eigenen Schreibe/Lesekopf, wobei alle Köpfe über einen gemeinsamen Zustellarm (Actuator) fest miteinander verbunden sind. Die binären Informationen werden in konzentrischen Kreisen auf den Plattenoberflächen gespeichert. Einen Kreis bezeichnet man als Track. Durch radiale Bewegung kann nun der Zustellarm die Köpfe auf jeden beliebigen Track positionieren. Tracks, die direkt untereinander liegen, und daher bei selber Zustellarmposition gelesen/beschrieben werden können, werden unter der Bezeichnung Zylinder (cylinder) zusammengefasst. Ein Sektor schließlich ist die kleinste adressierbare Dateneinheit einer Disk und umfasst eine diskspezifische Anzahl an Bytes. Ein Track besteht aus mehreren Sektoren. Magnetische Disk [chen1994] Performance Maße einer Disk zaia1998Access Time – Zeit, die zwischen Request und Datenbereitstellung vergeht Seek Time – Zeit, die benötigt wird, um Schreibe/Lesekopf auf gewünschten Track (bzw. Zylinder) zu positionieren. Typische Werte: sind 2 bis 30 Millisekunden Average Seek Time – Durchschnittliche Seek Time Wert, ermittelt durch eine zufällige Sequenz von Requests Definition BlockFür den Austausch von Daten zwischen magnetischer Disk und Hauptspeicher werden die Daten in Blöcke unterteilt. Ein Block kann dabei 512 bis einige Tausend Bytes umfassen und ist die Basiseinheit für Datentransaktionen. Auf einer Magnetplatte wird ein Block als eine Sequenz von physisch nebeneinander liegenden Bytes innerhalb eines Tracks gespeichert. Blockplatzierung - Überblick1auto
2Unterscheidung der BlockplatzierungsstrategienFür Multimedia Daten unterscheidet man Strategien, die sich von traditionellen Blockplatzierungen ableiten und Strategien, die die besonderen Eigenschaften von Multimedia Daten zur Overheadreduktion nützen können (Eingeschränkte Platzierung). Traditionelle BlockplatzierungTraditionelle Blockplatzierungs Strategien leiten sich von traditionellen Datenplatzierungsstrategien ab. Diese können unabhängig vom Datentyp angewendet werden.
Eingeschränkte Platzierung (Constrained-placement policies)Diese Strategien berücksichtigen die speziellen Eigenschaften von Multimedia Daten.
Everest Platzierung1Traditionelle Contiguous Allocation
Everest Contiguous Allocation
Funktionsweise
Beispiel für mögliche Gruppengrößen
Beispiel Aufteilung einer Datei mittels Everest Allocation
Beispiel Löschen einer Datei
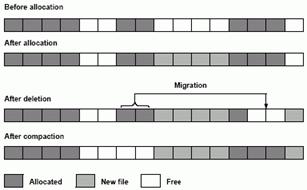
Everest Allocation: Löschen, Blockmigration und Verdichtung 2Traditionelle Contiguous AllocationEs werden alle Blöcke einer Datei in gleich bleibender Reihenfolge in aneinander grenzenden Sektoren auf der Disk gespeichert. Lesen einer DateiFür das kontinuierliche Auslesen aufeinander folgender Blöcke einer Datei ist die „Contiguous Allocation“ Blockanordnung optimal, da die Seek Time minimal ist. Diese Methode ist daher für Read-only Speichermedien, wie zum Beispiel der CD-ROM und der Video-DVD, besonders geeignet. Lesen mehrerer DateienSollen Blöcke unterschiedlicher Dateien gleichzeitig ausgelesen werden, bietet die Contiguous Allocation keine Strategie, um die durch die fortwährend neu zu positionierenden Lese/Schreibköpfe eingeführte Seek Time zu minimieren. Diese Eigenschaft macht sich besonders auch dann negativ bemerkbar, wenn der Benutzer eine Multimedia Datei mittels VCR Befehle durchsuchen will. Lesen/SchreibenFür ein Speichermedium wie der magnetischen Disk, auf der sowohl geschrieben wie auch gelesen wird, ist zu beachten, dass die Anzahl der Dateien und deren Größe ständig variiert. So entstehen an manchen Stellen der Disk Lücken, anderswo wieder wird es für die Dateien zu eng. Geeignete Strategien müssen daher dafür sorgen, dass die Dateien so positioniert werden, dass sie immer möglichst nahtlos nebeneinander zu liegen kommen. Das notwendige Umpositionieren der Dateien wird allerdings mit zunehmender Dateiengröße zu einem ernsten Problem: Je größer die Datei, desto länger dauert der Kopiervorgang. In dieser Zeit kann auf entsprechende Datei nicht zu gegriffen werden. Weiters erzeugt der Kopiervorgang selbst einen großen Overhead und damit eine Beschneidung der effektiven Bandbreite. Everest Contiguous AllocationZielUm die Vorteile der traditionellen Contiguous Allocation auch für die gewöhnlich sehr großen Multimedia Dateien nutzen zu können, wurde die Everest Platzierung entwickelt. FunktionsweiseFür die Everest Strategie werden nicht alle Blöcke einer Datei durchgehend physisch aneinander liegend auf der Disk gespeichert, sondern es werden Blöcke zu Gruppen zusammengefasst, wobei die Blöcke einer Gruppe aneinander liegend in einem Segment gespeichert werden, die Gruppen aber nicht aneinander grenzen. Durch diese Strategie ergibt sich auf der Disk ein Muster aus Daten- und freie Blöcke. DatenblöckeDie möglichen Größen einer Gruppe werden durch bestimmt. Beispiel GruppengrößeWenn Freie BlöckeFreie Blöcke werden in freien Segmenten organisiert und in einer
eigenen Freie- Segmente-Liste geführt. Diese Liste besteht aus mehreren
Unterlisten, und zwar je eine Liste für jede sich aus Beispiel Aufteilung einer Datei mittels Everest AllocationIm Folgenden wird gezeigt, wie eine 50 Block Datei von der Everest
Allocation in Blockgruppen aufgeteilt wird.
1 Segment mit 32 Blöcken ( Für
1 Segment mit 27 Blöcke ( Beispiel Löschen einer DateiDie Abbildung zeigt die verschiedenen Phasen der Everest Allocation
Strategie bei Löschen einer Datei: Löschen, Blockmigration und Verdichtung.
Für dieses Beispiel wurde Everest Allocation: Löschen, Blockmigration und Verdichtung Orgelpfeifenplatzierung1Ziel
Funktionsweise
Orgelpfeifenplatzierung: Häufig aufgerufene Blöcke w
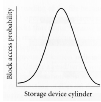
2ZielZiel der Orgelpfeifenplatzierung ist es, die Average Seek Time zu minimieren. Als Grundlage der Platzierung dienen die Aufrufwahrscheinlichkeiten der einzelnen Dateienblöcke. FunktionsweiseBei der Orgelpfeifenstrategie werden aufeinander folgende Blöcke einer Datei nicht notwendiger Weise nebeneinander liegend auf der Disk gespeichert. Vielmehr werden Blöcke danach bewertet, wie groß die Wahrscheinlichkeit ist, dass sie aufgerufen werden. Untersuchungen haben ergeben, dass die Average Seek Time minimiert werden kann, wenn Blöcke mit hoher Aufrufwahrscheinlichkeit in den mittleren Zylindern, jene mit geringerer Wahrscheinlichkeit am inneren bzw. äußeren Rand der Platten gespeichert werden. In der Mitte der Disk befinden sich also alle Blöcke mit hoher Aufrufwahrscheinlichkeit, unabhängig davon, zu welcher Datei sie gehören. Durch diese Blockanordnung sind die durchschnittlichen Weglängen, die die Schreib/Leserköpfe bei der parallelen Bearbeitung von unterschiedlichen Requests zurücklegen müssen, minimal.
Orgelpfeifenplatzierung: Häufig aufgerufene Blöcke werden in den mittleren Zylindern, selten angeforderte in den Randlagen der Disk gespeichert. REBECA1auto
Funktionsweise
Beispiel REBECA Einfluss der Regionsgröße
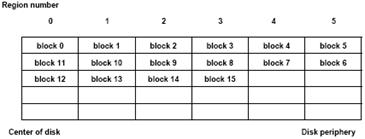
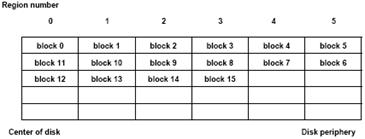
2ZielBei REBECA werden die Daten so platziert, dass möglichst viele Multimedia Dateien zeitgleich geschrieben/ausgelesen werden können. Es wird dabei der sequentielle Charakter von Multimedia Datenströmen genutzt. Man erhält bei dieser Methode die Möglichkeit, zwischen Bandbreite des Speichergerätes und Startverzögerung der Datenströme abzuwägen. FunktionsweiseFür die Region-based block allocation method (REBECA) wird die magnetische Disk in eine fixe Anzahl von konzentrischen Regionen unterteilt. Die Größe der einzelnen Regionen hängt von der gewählten Anzahl der Regionen ab: Wird in vielen Regionen unterteilt, werden die Regionen kleiner und umgekehrt. Beim Schreibvorgang verteilt REBECA aufeinander folgende Blöcke eines Multimedia Objektes auf aufeinander folgende Regionen. In einer Region befinden sich also Blöcke von verschiedenen Multimedia Objekten. Befindet sich die Schreibe/Leseköpfe in einer bestimmten Region, können Blöcke der unterschiedlichen Multimedia Objekte beinahe zeitgleich ausgelesen werden. Schreibe/Lesestrategie bei REBECADie Schreib/ Leseköpfe befinden sich ursprünglich in der dem Diskzentrum am nächst gelegenen Region. In dieser Position bearbeiten sie alle Requests, die sich auf Blöcke beziehen, die sich hier befinden. Nun wandern die Köpfe sukzessive von innen nach außen, von Region zu Region, und bearbeiten dort jeweils alle regionsrelevanten Requests. Nachdem sie in der äußersten Region angelangt sind, bewegen sie sich wieder schrittweise nach Innen, bis sie schließlich wieder die ursprüngliche Position erreicht haben. Wie oft dieser Disk-Abtastzyklus wiederholt wird, hängt von der Länge der Multimedia Objekte ab. Durch diese Strategie können viele unterschiedliche Streaming Dateien wie Videos oder Audios praktisch zeitgleich ein/ausgelesen werden. Beispiel REBECAAls Beispiel betrachten wir eine Disk, die in 6 Regionen unterteilt wird. Die Region 0 umfasst die dem Diskzentrum nahen Zylinder, Region 5 die Zylinder am Diskrand. Auf dieser Disk soll nun eine Datei, die aus 16 Blöcken besteht, gespeichert werden. Von Innen beginnend wird nun Block 0 in Region 0 gespeichert, Block 1 in Region 1 usw. Block 5 und 6 werden in der Region 5 gespeichert. Die Schreibe/Leseköpfe bewegt sich nun wieder Richtung Zentrum, Block 7 wird in Region 4 gespeichert usw. REBECA : Eine Datei bestehend aus 16 Blöcken wird auf 6 Regionen aufgeteilt Einfluss der RegionsgrößeDie richtige Wahl der Größe der Regionen spielt die entscheidende Rolle für die Performance von REBECA. Es muss zwischen gewünschter Bandbreite und vertretbarer Startverzögerung der Datenströme abgewogen werden. BandbreiteDie Seek Time innerhalb einer Region hängt von deren Größe ab: Ist die Region groß, ist der mögliche Weg, den der Kopf zurücklegen muss, groß. Dementsprechend hoch ist die maximale Seek Time. Ist die Region hingegen klein, reduziert sich die Seek Time, es können in kürzerer Zeit mehr Blöcke ausgelesen werden. Kleine Regionen erhöhen die erzielbare Bandbreite des Speichergerätes. StartverzögerungViele kleine Regionen ergeben zwar eine geringe Seek Time, aber erhöhen auch die Zeit, die die Lese/Schreibköpfe benötigen, um einen vollständigen Abtastzyklus zu durchlaufen. Ein Video- oder Audiodokument kann aber erst gestartet werden, wenn sich der Kopf in der Region befindet, in der der entsprechende Startblock steht. Für eine minimale Startverzögerung sind daher große Regionen wünschenswert. Retrieval - Strategien zum Abrufen von Multimedia-Daten1Überblick
Zwei Kategorien von Ablaufplanungsstrategien
2ÜberblickDie größte Herausforderung, die sich beim Abruf von Multimedia Datenstöme ergibt, ist deren unterbrechungsfreie Lieferung. Dazu bedarf es eigener Ablaufplanungsstrategien (Scheduling policies). Sie haben die Aufgabe, einen geeigneten Zeitplan zu erstellen, der festlegt, wann welcher Block ausgelesen werden muss, um für alle aktuellen Requests eine unterbrechungsfreie Wiedergabe garantieren zu können. Alle Strategien arbeiten mit dem Prinzip, dass sie Blöcke schon im Vorhinein von der Disk abrufen. Ablaufplanungsstrategien können in zwei Kategorien eingeteilt werden:
Round-based Strategien1Round-Robin Strategien
Abtast-Strategien (Scan policies)
Vergleich Round-Robin Strategien und Abtast Strategien Vergleich Round-Robin und Abtast-Strategie bei drei Dateien Group Sweeping Scheduling (GSS)
Beispiel GSS
Auslesestrategie GSS für 6 Dateien, die in 2 Gruppen aufgeteilt werden Aufteilung in Gruppen
Auslesereihenfolge
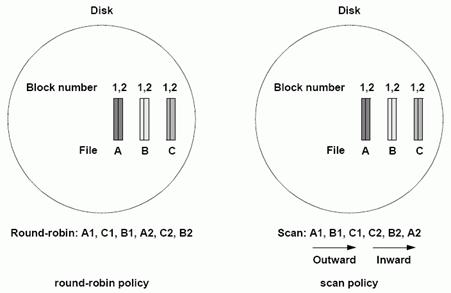
2Round-Robin StrategienRound Robin = Zyklischer Warteschlangenbetrieb ling2005. Der Round-Robin Planer spielt die einzelnen Datenstromblöcke nach einer fix vorgegebenen Ordnung aus. Die Requests werden in dieser fixen Reihenfolge bedient. Die Round-Robin Strategie wird zwar auf Grund ihrer Einfachheit gerne eingesetzt, sie hat allerdings den großen Nachteil, dass bei der Ausgabe die Reihenfolge der Datenströme nicht verändert werden kann, so dass es keine Möglichkeit gibt, den Leseköpfen redundante Wegzeiten zu ersparen und somit den Seek-Overhead zu minimieren. Durch diesen systemimmanenten Overhead dauert auch eine Runde bei der Round-Robin Strategie länger als bei anderen Auslesestrategien. Dementsprechend groß müssen die Puffer dimensioniert werden. Ein Puffer muss dabei Datenmengen, die für die Dauer einer Runde ausreichen, fassen können. Abtast-Strategien (Scan policies)Bei dieser Strategie tasten die Lese/Schreibköpfe periodisch die gesamte Diskoberfläche ab. Beginnend im Inneren der Disk bewegen sie sich schrittweise Richtung Äußersten Zylinder der Disk, von dort bewegen sie sich wieder, ebenfalls schrittweise, Richtung Zentrum. Es werden jeweils die Requests bedient, die sich auf die Daten der momentanen Köpfeposition beziehen. Obwohl die Puffer der Abtast-Strategie Datenmengen fassen müssen, die die Dauer von zwei Runden überbrücken, sind diese trotzdem kleiner als bei der. Round-Robin Strategie (Puffer für eine Runde). Der Grund dafür ist, dass es bei der Abtast-Strategie nur einen geringen Seek Overhead gibt, und eine Runde daher dementsprechend kürzer dauert. Vergleich Round-Robin Strategien und Abtast StrategienDie Abbildung zeigt schematisch die Arbeitsweise der beiden Strategien. Vergleich Round-Robin und Abtast-Strategie bei drei Dateien Round-RobinBei der Round-Robin Strategie ist die Reihenfolge der Datenströme fix: In diesem Beispiel werden zuerst die Blöcke der Datei A, dann die der Datei C und dann die der Datei B ausgelesen. Wie man leicht erkennen kann, wäre bei der in der Abbildung dargestellten Dateienplatzierung die Auslesereihenfolge A, B, C in Hinblick auf einen minimalen Seek Overhead zweckmäßiger, aber unter Round-Robin eben nicht realisierbar. Ein Vorteil der starren Auslesereihenfolge ist, dass der zeitliche Abstand zwischen zwei aufeinanderfolgenden Blöcken einer Datei (A1-A2, C1-C2, B1-B2) immer eine Runde beträgt. Abtast Strategien (Scan policies)Es werden die Blöcke in derselben Reihenfolge ausgelesen, wie die Dateien auf der Disk physisch angeordnet sind. Dadurch wird ein Minimum an Seek Overhead erreicht. In welchen zeitlichen Abständen aufeinander folgender Blöcke einer Datei ausgelesen werden, hängt von der Dateiposition ab. In der Abbildung sieht man, dass Block 1 und 2 der Datei C unmittelbar hintereinander ausgelesen werden, während Block 1 und 2 der Datei A in einem 2 Runden entsprechendem Zeitabstand geliefert werden. Die Puffer müssen daher Daten für zwei Runden puffern können. Group Sweeping Scheduling (GSS)Diese Strategie ist eine Kombination der Round-Robin- und der Abtast-Strategie. Durch Group Sweeping Scheduling lässt sich ein minimaler Seek Overhead bei gleichzeitig kleinen Puffergrößen realisieren. Die Round-Robin Komponente bewirkt, dass Daten nur für eine Runde gepuffert werden müssen, die Abtaststrategie Komponente sorgt dafür, dass diese Runde möglichst schnell abgearbeitet wird. Funktionsweise von GSS
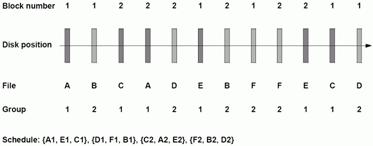
Entscheidend für die Qualität von GSS ist die richtige Wahl des Wertes M. M ist dann optimal, wenn sich eine minimale erforderliche Puffergröße ergibt. Da die Gruppen in der Round-Robin Reihenfolge ausgelesen werden, müssen die Puffer nur Daten für eine Runde zwischenspeichern können. Im Gegensatz zur Round-Robin Strategie benötigt GSS allerdings wesentlich weniger Zeit für eine Runde, da die Datenströme selbst mit der Seektime-schonenden Abtaststrategie ausgelesen werden. Beispiel GSSAuf einer Disk sind die 6 Dateien A, B, C, D, E, F, wie in der Abbildung dargestellt, positioniert. GSS teilt sie nun in 2 Gruppen auf: Gruppe 1: G1 {A, C, E} Gruppe 2: G2 {B, D, F} Es werden nun die Gruppen mit Round-Robin, die Dateien einer Gruppe mittels Abtaststrategie ausgelesen. Es ergibt sich für die Dateienblöcke folgende Auslesereihenfolge:
Auslesestrategie GSS für 6 Dateien, die in 2 Gruppen aufgeteilt werden Dateienplatzierung - Allgemein1Aufgabe
Arbeitsweise
2AufgabeDateienplatzierungs Strategien haben die Aufgabe, für jede Datei den geeigneten Speicherort zu wählen: Es müssen dabei sowohl Eigenschaften der Speichergeräte wie die der Dateien betrachtet werden: Jedes Speichergerät hat bezüglich Bandbreite und Speicherplatz individuelle Grenzen, Dateien sind unterschiedlich groß und werden unterschiedlich oft angefordert, womit auch deren erforderlichen Bandbreiten ebenfalls unterschiedlich sind. ArbeitsweiseMischung unterschiedlicher DateienSpeichergeräte kann man bezüglich Bandbreite und Speicherkapazität als schnelle oder langsame Geräte klassifizieren. Dateien kann man auf Grund ihrer Popularität in als populäre und weniger populäre und auf Grund ihrer Größe als große und kleine Dateien klassifizieren. Für eine optimale Dateienplatzierung muss nun für jedes Speichergerät eine ideale Mischung von populär und wenig populär, groß und klein, gefunden werden. Beispiel: Schlechte DateienplatzierungAls ein Beispiel, wie durch falsche Platzierung vorhandene Ressourcen verschließen werden können, betrachten wir hier ein schnelles Speichergerät, auf welchem vorwiegend lange, aber wenig populäre Dateien positioniert werden. Die Speicherkapazität wird zwar ausgenutzt, da aber die zu erwartende Requesthäufigkeit gering ist, wird potentielle Bandbreite nicht genutzt. Ähnliches gilt, wenn man viele kleine Dateien hoher Popularität auf ein langsames Speichergerät stellt: Die geringe Bandbreite des Gerätes erlaubt nur wenige Zugriffe, nur wenige Dateien können zur Verfügung gestellt werden, Speicherkapazitäten werden unnötig vergeudet. Beispiel: Gute DateienplatzierungEine gute Dateienplatzierung ergibt sich im Allgemeinen aus einer Mixtur von populären und weniger populären, großen und kleinen Dateien. Erstellen von KopienUm dem Wunsch nachkommen zu können, dass eine hohe Anzahl von Clients zeitgleich auf dieselbe Multimedia Datei zugreifen können, ist es oft notwendig, von einer Datei mehrere Kopien zu speichern. Die Platzierungsstrategie muss nun entscheiden, wie viele Kopien zu erstellen sind und wo diese zu speichern sind. Dateienplatzierung und BelastungsschwankungenIn realen Systemen werden zirka 5% der Gesamtbandbreite benötigt, um Belastungsschwankungen, die während des Betriebes entstehen, ausgleichen zu können. Um einen zufrieden stellenden Belastungsausgleich zwischen den verschiedenen Speichergeräten zu erzielen, ist eine dynamische Strategie sehr hilfreich. Die DSR (Dynamic Segment Replication) zum Beispiel arbeitet nur mit Kopien von Teilen der Multimedia Objekte, mittels deren dynamischen Verschiebung sie Belastungsschwankungen entgegen wirkt. Die Effektivität einer solchen Strategie hängt stark davon ab, wo ursprünglich die Dateien platziert waren. Unter dem Gesichtpunkt des Belastungsausgleiches wird eine Dateienplatzierungsstrategie dann als gut angesehen, wenn eine dynamische Strategie effektiv darauf aufbauen kann. Dateienplatzierung für interaktive AnwendungenBei vielen interaktiven Anwendungen ist es erforderlich, dass kundenseitig mehrerer Multimedia Objekte gleichzeitig angezeigt werden. Um ein hohes Maß an Synchronität gewährleisten zu können, sollten hier die unterschiedlichen Objekte so platziert werden, dass nur wenig zwischen unterschiedlichen Servern hin- und hergeschaltet werden muss. Praktische Anforderungen an Dateienplatzierung1auto
2autoUm eine Strategie mit hoher Effektivität zu erzielen, muss folgendes berücksichtigt werden:
Popularitätsbasierte Strategie1Ziel
Funktionsweise
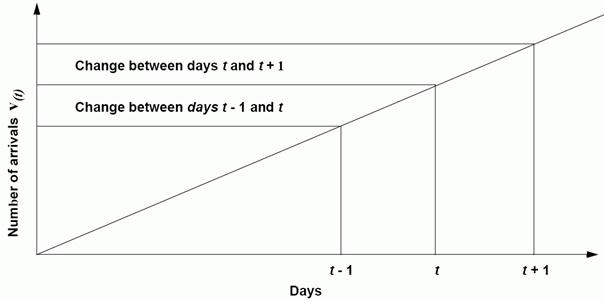
Schätzung der Popularitätswerte für morgigen TagZugriffswahrscheinlichkeit für den morgigen Tag ergibt sich aus:
Popularitätsbasierte Strategie: Aus den Werten der Tage t und t -1 wird Tag t+1 approximiert Dateienplatzierung auf identische Disks
2ZielDie popularitätsbasierte Strategie (engl: popularity-based placement policy) kann dazu benutzt werden, um Multimedia Objekte auf ein Set identischer Disks optimal zu platzieren. Es wird das Ziel verfolgt, die Zahl der Clients, die im Falle einer Überlastung nicht bedient werden können, möglichst niedrig zu halten. FunktionsweiseDie popularitätsbasierte Strategie baut auf der Kenntnis der Aufrufwahrscheinlichkeitswerten der gespeicherten Dateien auf. Für solch eine Strategie ist es wichtig zu wissen, welche Datei in Zukunft eine höhere bzw. geringere Popularität haben wird. Das heißt, man muss schon im Vorhinein für jede Datei mittels geeigneten Algorithmen genau abschätzen können, wie oft sie in nächster Zukunft aufgerufen wird. Zu diesem Behufe wird für jede Datei protokolliert, wie oft sie im Verlauf eines Tages angefordert wird. Die hier betrachtete popularitätsbasierte Strategie rekonfiguriert die Dateienplatzierung alle 24 Stunden, und zwar off-line. Die für den morgigen Tag zu erwartenden Zugriffswerte werden mittels der Werte vom heutigen und gestrigen Tag approximiert. Schätzung der Popularitätswerte für morgigen Tag
Die Zugriffswahrscheinlichkeit für den morgigen Tag ergibt sich aus: Popularitätsbasierte Strategie: Aus den Werten der Tage t und t -1 wird Tag t+1 approximiert Dateienplatzierung auf identische DisksFür eine optimale Dateienplatzierung ist die popularitätsbasierte Strategie bestrebt, die Dateien so auf die Disks aufzuteilen, dass auf jede Disk mit gleicher Häufigkeit zugegriffen wird. BSR Strategie (Bandwidth to Space Ratio)1Ziel
Funktionsweise
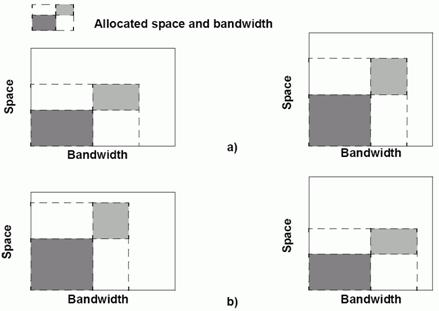
Beispiel Übereinstimmung BSR. BSR: Zwei Geräte mit unterschiedlichem Bandbreiten-Kapazitäts-Verhältnis a) Übereinstimmung der BSR der Speichergeräte und Dateien. b) Keine Übereinstimmung der BSR der Speichergeräte und Dateien Details zum BSR Algorithmus
Performancemaße
Evaluierung BSR für Video-on-DemandStudie siehe shah1995 Aufbau der Simulation
Kapazität/Bandbreiten Werte der 4 Striping Groups
Anfangsplatzierung durch BSR
BSR: Anfangsplatzierung a) Kapazität b) Bandbreite. Die schwarzen Balken zeigen die zur Verfügung stehenden Werte. Die beiden grauen Balken (hell- und dunkelgrau) zeigen die durch die BSR Platzierungsstrategie erzielten Werte. BSR bei Belastungsänderung
Links: Zipfverteilung und unterschiedliche Belastungsänderungen – Rechts: Bandbreite Kapazität (schwarz), Anfangsplatzierung (dunkelgrau), Verschiebung 1 (mittelgrau), Verschiebung 10 (hellgrau) 2ZielDie BSR Strategie ( Bandwidth to Space Ratio) ermöglicht es, große und kleine Multimedia Objekte, Objekte mit hohen und geringen Popularitätswerten auf Speichergeräte unterschiedlicher Charakteristika ressourcenoptimiert zu verteilen. FunktionsweiseDie BSR Strategie charakterisiert jedes Speichergerät durch dessen maximale Bandbreite und Speicherkapazität, jedes Multimedia Objekt durch Größe und dessen zum Zeitpunkt der Speicherung geforderte Bandbreite. Die BSR Strategie ist bestrebt, für jedes Speichergerät die richtige Melange an Dateien zu finden, sodass die geforderten Bandbreite- und Kapazitätswerte der Dateien mit den Werten des Speichergerätes harmonieren: Das Bandbreiten-Kapazitäts-Verhältnis (Bandwidth to Space Ratio) des Speichergerätes soll gleich dem Bandbreiten-Kapazitäts-Verhältnis der darauf gespeicherten Dateien sein. Die BSR Strategie arbeitet online: Ergeben sich während des Betriebes Änderungen der Werte, so reagiert die BSR Strategie, indem sie Kopien verschiebt, löscht (wenn eine sinkende Nachfrage nach betreffendem Objekt erkennbar ist) oder neue erstellt (für Objekte mit steigender Popularität), um so möglichst schnell die Übereinstimmung von Speichergeräten und den darauf gespeicherten Dateien wieder herzustellen. Beispiel Übereinstimmung BSRDie Abbildung zeigt zwei Speichergeräte mit unterschiedlichen Bandbreiten-Kapazitäts-Verhältnisse. Das Gerät 1 (in der Abbildung links) bietet hohe Bandbreite bei verhältnismäßig wenig Speicherplatz. Gerät 2 (in der Abbildung rechts) hat ein ausgewogenes Bandbreiten-Kapazitäts-Verhältnis. In a) ist der zum jeweiligen Gerät passende, in b) der nicht passende Dateiensatz eingezeichnet. . BSR: Zwei Geräte mit unterschiedlichem Bandbreiten-Kapazitäts-Verhältnis a) Übereinstimmung der BSR der Speichergeräte und Dateien. b) Keine Übereinstimmung der BSR der Speichergeräte und Dateien Details zum BSR AlgorithmusEingangsparameter BandbreiteDie BSR Strategie hat bezüglich Bandbreite eines Multimedia Objektes zwei Eingangsparameter: Die sich durch die Anzahl der zu erwartenden Requests ergebende Bandbreite eines Multimedia Objektes und die zusätzlich benötigte Bandbreite, um eine Kopie zu erstellen. Die letztgenannte ist neben der Dateiengröße davon abhängig, wie schnell die Kopie erstellt werden kann: Wird ein Objekt von einer Disk auf eine andere kopiert, dauert der Kopiervorgang nur kurz, wird von einem Magnetband kopiert dauert er lang, bei einer Echtzeitanwendung läuft er während der gesamten Übertragung. Die vier Phasen des BSR AlgorithmusDie BSR legt mit Hilfe der Eingangsparameter die Anzahl der erforderlichen Kopien fest. Der Algorithmus besteht aus 4 Phasen:
PerformancemaßeDie Performance der BSR Strategie kann unter unterschiedlichen Gesichtspunkten bewertet werden. Eine Möglichkeit wäre, nach jedem Aufruf der BSR Strategie die Abweichungen der Bandbreiten-Kapazitäts-Verhältnisse zu messen und danach die Performance der Strategie zu evaluieren. Allerdings gibt dieses Maß nur wenig Auskunft darüber, wie effektiv die Strategie im Falle hoher Belastung arbeitet. Dazu eignet sich das Performancemaß der „ Ungenutzten Bandbreite “. Dieses gibt an, wie viel Bandbreite nicht genutzt werden kann, da der Speicherplatz, nicht aber die Bandbreite der Geräte voll ausgeschöpft werden. Evaluierung BSR für Video-on-DemandIm Folgenden wird die Performance der BSR mittels einer Simulation in einer Video-on-Demand Umgebung untersucht. Siehe dazu shah1995 Aufbau der SimulationIn der Simulation werden 64 Videos in vier Striping groups auf 8, 16, 32 und 64 identischen Disks gespeichert. Jede Disk bietet eine Speicherkapazität von 2GB und eine Bandbreite, die die gleichzeitige Ausgabe von 6,25 Datenströmen erlaubt. Für die Striping Groups ergeben sich die jeweiligen Kapazität/Bandbreite Werte in Abhängigkeit der Diskanzahl. Rechenbeispiel für Striping Group 1Striping Group 1 wird auf 8 Disks aufgeteilt. Daraus ergeben sich folgende Kapazitäts/Bandbreiten Werte: Kapazität: Bandbreite: Kapazität/Bandbreiten Werte der 4 Striping GroupsAnalog dem oberen Rechbeispiel können für jede Striping Group deren Kapazitäts/Bandbreiten Werte berechnet werden.
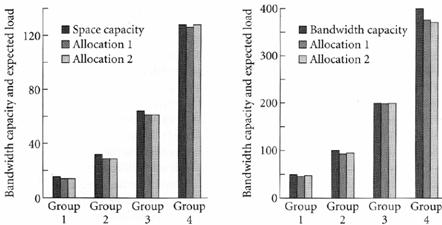
Bandbreite und Größe der VideosJedes Video hat eine Größe von 3,6GB. Die erforderlichen Bandbreiten der Videos werden durch das Zipfsche Gesetz ermittelt. Anfangsplatzierung durch BSRIm ursprünglichen Zustand sind alle Disks leer. Die BSR Strategie hat zunächst die Aufgabe, die 64 Videos optimal auf die Disks aufzuteilen. Die Abbildung zeigt das Ergebnis. Allocation 1 und 2 ergeben sich durch den unterschiedlichen Wert eines Eingangsparameters der BSR. Dieser Eingangsparameter legt die maximale Belastung pro Kopie fest (Allocation1: 30 Allocation2: 50).
BSR: Anfangsplatzierung a) Kapazität b) Bandbreite. Die schwarzen Balken zeigen die zur Verfügung stehenden Werte. Die beiden grauen Balken (hell- und dunkelgrau) zeigen die durch die BSR Platzierungsstrategie erzielten Werte.
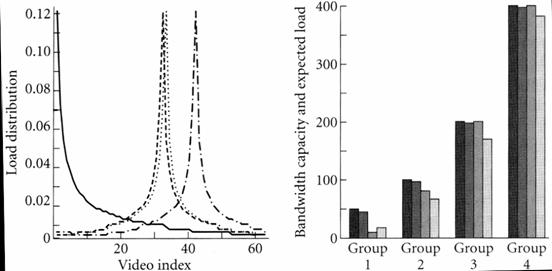
ErgebnisWie man sieht, arbeitet die BSR Strategie hervorragend. Sie nutzt Bandbreite und Speicherplatz gleichermaßen. Weitere ErkenntnisseDie BSR liefert nur dann ein optimales Ergebnis, wenn genug Speicherplatz vorhanden ist, um mindestens eine zusätzliche Kopie pro Video speichern zu können. Bei kleinerer Speicherkapazität werden die Ressourcen nicht mehr optimal genutzt, wobei die BSR Strategie so arbeitet, dass nur sehr kleine Teile der möglichen Bandbreite und Kapazität vergeudet werden. BSR bei BelastungsänderungBei Veränderungen der Verteilung der Dateienzugriffe kann die BSR Strategie die Dateienplatzierung dynamisch aktualisieren. Um dieser Fähigkeit zu evaluieren, wird die Belastungsänderung durch eine Änderung der Zipfschen Verteilung simuliert. Diese Änderung wird durch die gefaltete Zipfverteilung beschrieben. Durch Verschieben des Indexwertes kann die gefaltete Zipfverteilung unterschiedlich starke Belastungsänderungen, d.h. eine Änderung der Aufrufhäufigkeiten, simulieren (Je größer die Verschiebung, desto größer die Belastungsänderung). In der Abbildung links sind neben Zipfscher Verteilung (durchgehende Linie) und gefalteter Zipfscher Verteilung (gestrichelte Linie) die Kurven für Verschiebung 1 (punktierte Linie) und Verschiebung 10 (Strich-Punkt Linie) eingezeichnet. Rechts sind die Bandbreiten-Kapazitäts Werte der Striping Groups eingezeichnet (schwarze Balken), die Anfangsplatzierungswerte (dunkelgraue Balken), Platzierung bei Belastungsänderung mit Verschiebung 1 (mittelgrauer Balken) und mit Verschiebung 10 (hellgrauer Balken).
Links: Zipfverteilung und unterschiedliche Belastungsänderungen (siehe Text) – Rechts: Bandbreite Kapazität (schwarz), Anfangsplatzierung (dunkelgrau), Verschiebung 1 (mittelgrau), Verschiebung 10 (hellgrau) ErgebnisWie man aus Abbildung erkennen kann, erzielt die BSR Strategie auch nach einer starken Belastungsänderung eine exzellente Dateienplatzierung.
|
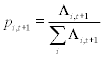
|
Akronyme BSR – Bandwith to Space Ratio, Bandbreite - Speicherplatz Verhältnis DSR – Dynamic Segment Replication DVD – Digital Versatile Disc (früher Digital Video Disc) e.g. – Exempli Gratia (Latein: Zum Beispiel ) Gb – Gigabit (1024 Megabits) GSS – Group Sweeping Scheduling QoS – Quality of Service REBECA - Region-based block allocation method VCR – Video Cassette Recorder Glossar Access Time – Zeit, die zwischen Request und Datenbereitstellung vergeht Average Seek Time – Durchschnittliche Seek Time Wert, ermittelt durch eine zufällige Sequenz von Requests Seek Time – Zeit, die benötigt wird, um Schreibe/Leseköpfe einer magnetischen Disk auf gewünschten Track (bzw. Zylinder) zu positionieren. Round Robin – Zyklischer Warteschlangenbetrieb Terminologie – die Gesamtheit aller Begriffe und Benennungen (Termini) einer Fachsprache Zylinder (Cylinder) – Zusammenfassung von übereinander liegender Tracks einer magnetischen Disk. |