| Title: | Forschungsprodukte | ||
|---|---|---|---|
| Abstract: |
Im Folgenden wird ein Überblick über einige Multimedia-Datenbankmanagementsysteme gegeben. Die MMDBMS haben verschiedene Systemanwendungen und Schwerpunkte.
|
||
| Status: | Review II: done | Version: | 8.0 |
| History: |
auf MPEG-7 verlinkt Rendering Taggingfehler korrigiert. Acronyme, Absätze, Wordanführungszeichen done. @Prof Kosch: small figure von Folie 10 fehlt done. Review von Prof. Kosch eingearbeitet. Unbekannte Character entfernt. Zu große Graphiken bearbeitet. |
||
| Author 1: | Harald Kosch | E-Mail: | harald.kosch@itec.uni-klu.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Universität Klagenfurt - Institut für Informatik-Systeme | ||
Forschungsprodukte1Überblick über Forschungsprodukte
MIRROR Database
Auto PC
Auto PDA_Phone
AutoNeuheit: COBRA, ein Videodaten-Modell mit einer Grammatik zur besseren Annotierung von Multimedia-Daten. DISIMA Database
Auto PC
Auto PDA_Phone
MARS Database
Auto PC
Auto PDA_Phone
AutoNeuheiten: Anfragebearbeitung mit Feedbackmechanismus, Indizierung mit hybriden Bäumen. SMOOTH databaseDer SMOOTH Prototyp, entwickelt an der Universität Klagenfurt, ist ein verteiltes Multimediadatenbanksystem. Integriert ist ein Abfrage-, Navigations- und Annotierungsframework für Video-Material, welches vom Inhalt einer Meta-Datenbank gesteuert wird. Auto PC
Auto PDA_Phone
AutoSMOOTH führte zur Entwicklung des Multimedia Data Cartridge, welches das Oracle-Basissystem erweitert. 2Überblick über ForschungsprodukteIm Folgenden wird ein Überblick über einige Multimedia-Datenbankmanagementsysteme gegeben. Die MMDBMS haben verschiedene Systemanwendungen und Schwerpunkte.
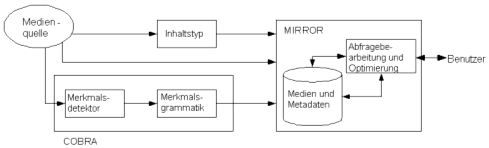
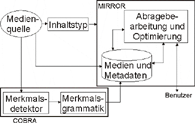
MIRROR DatabaseMIRROR ist eine Abkürzung für Multimedia Information Retrieval Reducing information OverRload. Das System wurde an der Universität von Twente entwickelt und ist ein Forschungs-Datenbanksystem für multimediale Inhalte. Sie wurde entwickelt, um beim Datenmanagement digitaler Multimedia-Bibliotheken für besseres Verständnis zu sorgen. MIRROR stellt während der Interaktion mit dem Benutzer wahrscheinlichkeitstheoretische Inferenzmechanismen zur Verfügung. Auto PC
Auto PDA_Phone
AutoObige Abbildung zeigt die Systemarchitektur von MIRROR. An der Spitze des MMDBMS läuft das Acoi-System (eine Plattform für Indizierung und Retrieval von Video- und Bilddaten). Das System stellt eine plug-in-Architektur zur Indizierung von Multimedia-Objekten zur Verfügung, indem mehrere Algorithmen zur Extrahierung von Merkmalen verwendet werden. Acoi stützt sich auf das COBRA (content-based retrieval) Videodaten-Modell. COBRA setzt eine Grammatik zur besseren Annotierung von Multimedia-Daten ein. Die Grammatik beschreibt low-level Merkmale (z.B. Farbe, Textur) und die Abhängigkeiten zwischen den Extrahierungsmechanismen und den Daten. Zusätzlich unterscheidet das System vier unterschiedliche Schichten des Video-Inhalts: die Rohdaten-, die low-level-Merkmals-, die Objekt- und die Ereignisschicht. Die Einteilung steht im Einklang mit den MPEG31-7-Standards (siehe auch LU MPEG-7 und MMDBS). Trotzdem werden keine standardisierten Instanzen verwendet, deshalb ist auch ein kompatibler Austausch von Metadaten nicht möglich. DISIMA DatabaseDISIMA (ein Kurzwort für Distributed Multimedia DBMS) ist ein Bilddatenbanksystem, das inhaltsbasierte Abfragen ermöglicht, und wurde an der Universität von Alberta entwickelt. Auto PC
Auto PDA_Phone
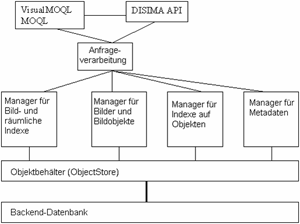
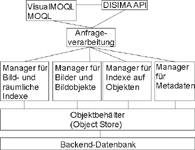
AutoIn Abbildung DISIMA Datenbankensystem wird die Architektur von DISIMA dargestellt. Der Prototyp wurde auf dem OODBMS ObjectStore aufbauend implementiert. ObjectStore wird hauptsächlich als Objektbehälter verwendet, da es OQL421 (Object Query Language) nicht unterstützt. Queries werden in der Abfragesprache MOQL (Multimedia Object Query Language) oder Visual MOQL405 (als Einschränkung für Bilder) spezifiziert. MOQL405 erweitert die Abfragesprache OQL421 und basiert auf Multimedia-Konstrukten, welche räumliche und zeitliche Abfragen erlauben. Die DISIMA API43 ist eine Bibliothek von low-level-Funktionen, die es den Anwendungen erlaubt, auf die Services des Systems zuzugreifen. Der Manager für Bilder und Bildobjekte implementiert das Typensystem und der Manager für Metadaten erlaubt die Erzeugung von Metainformationen über Bilder und Bildobjekte. Die Index-Manager erlaubt die Integration von benutzerdefinierten Indexen. MARS DatabaseMARS (Multimedia Analysis and Retrieval System) realisiert ein integriertes Multimedia-Retrieval- und Datenbankmanagementsystem, das die Speicherung und den Retrieval multimedialer Daten ermöglicht. Auto PC
Auto PDA_Phone
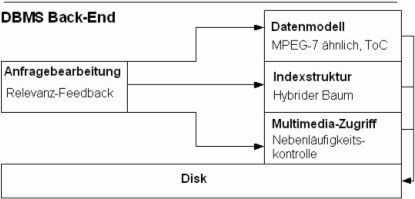
AutoMARS stellt eine Menge von Tools für ein MMDBMS-backend zur Verfügung, wie Abbildung MARS Database zeigt. Die Errungenschaften des MARS-Projekts wird in vier Sub-Kategorien unterteilt:
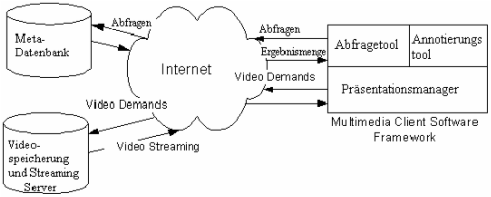
SMOOTH databaseSMOOTH, ein verteiltes Multimediadatenbanksystem, wurde an der Universität Klagenfurt entwickelt und integriert ein Framework für Abfragen, Navigation und Annotierung für Video-Material. Gesteuert wird das DBMS401 vom Inhalt einer Meta-Datenbank. Auto PC
Auto PDA_Phone
AutoAbbildung SMOOTH database zeigt die allgemeine Systemarchitektur
von SMOOTH. Der Videoserver stellt gezielten Zugriff zu physikalischen
Videoströmen zur Verfügung (verwendet wurde der Oracle Video Server
mit den unterstützten Protokolltypen UDP141
und RTP106.
SMOOTH führte zur Entwicklung des Multimedia Data Cartridge, welches das Oracle-Basissystem erweitert. Multimedia Data Cartridge1AutoAuto PC
Auto PDA_Phone
Auto
ArchitekturAuto PC
Auto PDA_Phone
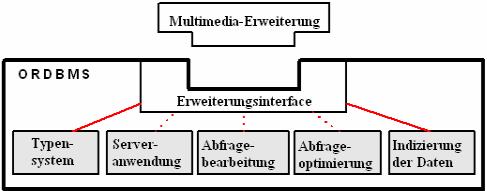
2AutoDas Multimedia Data Cartridge (MDC430) ist eine multimediale Erweiterung des Oracle 9i Datenbankmanagementsystems. MDC430 stellt folgende Konzepte zur Verfügung: ein Typsystem für Multimedia, Indizierung für Multimedia, außerdem eine Multimedia-Abfragesprache, Zugriff zu Medien und Bearbeitung und Optimierung von Abfragen, um den neuen multimedialen Typen und Methoden gerecht zu werden. Weiters werden die Serveranwendungen erweitert, damit z.B. die eingeführten Multimedia-Methoden ausgeführt werden können. MDC430 beruht auf die Oracle Data Cartridge Technologie. Auto PC
Auto PDA_Phone
AutoAbbildung Multimedia Data Cartridge zeigt die Data Cartridge Technology. Diese Technologie wurde mit Oracle 8 eingeführt, um eine Oracle-Datenbank mit spezialisierten Datentypen erweitern zu können, die ein bestimmtes Datenformat und Abfragealgorithmen benötigen. Ausgebaut wird das ORDBMS425 mit einem neuen Typsystem, Serveranwendungen, Abfragebearbeitung, Abfrageoptimierung und Indizierung von Daten durch ein so genanntes Erweiterungsinterface. ArchitekturAuto PC
Auto PDA_Phone
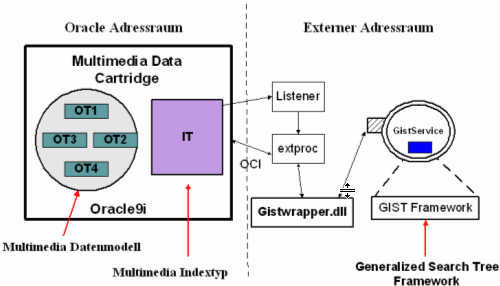
AutoMDC baut auf zwei Hauptkonzepte auf: Erstens das Multimedia-Datenmodell: Das Multimedia Datenmodell ist ein Datenbankschema, das von MPEG31-7-Beschreibungen abgeleitet wurde. Es wurde mit der Hilfe des erweiterbaren Typsystems der Cartridge-Umgebung realisiert, das heißt, Deskriptoren des MPEG31-7-Schemas wurden auf Objekttypen und Tabellen abgebildet. Zweitens das Multimedia-Index-Framework: Das Multimedia-Index-Framework stellt eine erweiterbare Indizierungsumgebung für Multimediaretrieval zur Verfügung. Das Index-Framework ist in die Abfragesprache integriert und ermöglicht effizientes Multimedia-Retrieval. Für die Abfragen und den Retrieval wird ein Framework von Suchbäumen verwendet: Generalized Search Trees (GiST431). Das GistService wird im externen Adressraum realisiert und läuft als eigener Prozess (Service) in der Betriebssystemumgebung. Das Service managt alle verfügbaren Zugriffmethoden. Weitere Informationen über GiST431 Framework folgen noch in dieser Lerneinheit. Multimedia Schema basierend auf MPEG-71Auto
Auto PC
Multimedia Schema basierend auf MPEG-7 PDA_Phone
2AutoBei Multimedia Schemata, die auf MPEG31-7
basieren, werden aus ausgewählten Typen des MPEG31-7-Standards
Datenbanktypen und -tabellen gebastelt. Oft wird als Datenbanktyp
der XML20-Typ
verwendet, dadurch kann die Anzahl der verschiedenen Datentypen in
der Datenbank erheblich reduziert werden. Ein Beispiel folgt später. In einem Multimedia Schema, das auf MPEG31-7
basiert, werden relationale Schlüssel (wie DOC_ID oder PART_ID) eingesetzt.
Sie dienen einerseits der Unterscheidung von Daten verschiedener MPEG31-7-Dateien,
und andererseits auch dazu, um mehrere Vorkommnisse desselben Elements
im MPEG31-7-Dokument
zu speichern. Auto PC
Multimedia Schema basierend auf MPEG-7 PDA_Phone
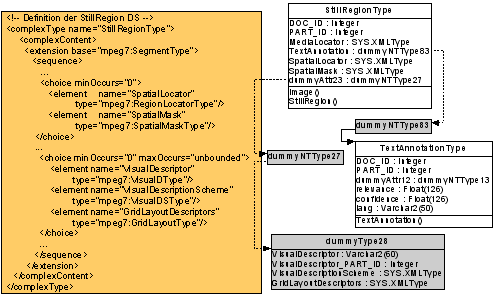
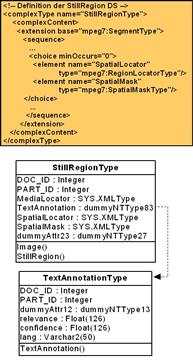
AutoDie Abbildung Multimedia Schema basierend auf MPEG31-7 zeigt einen Auszug eines Multimedia-Schemas, das von MPEG31-7 abgeleitet wurde. Es zeigt die Abbildung eines MPEG31-7 StillRegionType (ein Vertreter für Bilder im MPEG31-7, der zum Beispiel ganze Bilder und Teile von ihnen darstellt) in objekt-relationale Datenbanktypen. Im Datenbankschema (in der Abbildung rechts) wird ein Objekttyp mit dem selben Namen (StillRegionType) angelegt. Einige der Attribute wurden als eigene Objekttypen deklariert, andere wurden mit dem speziellen SYS.XMLType definiert. Die Entscheidung, welcher Typ verwendet werden soll, beruht auf der Wichtigkeit möglicher Abfragen. Das Attribut mit dem Typ TextAnnotationType wird detaillierter dargestellt, da das Attribut wichtig für eine free-text-search in der Datenbank ist. Für andere Attribute hingegen wird der XML20-Typ verwendet, zum Beispiel wenn eher wenig Informationen für ein spezielles Bild darin enthalten sind. Dadurch soll vermieden werden, dass zu viele Datenbankobjekte und -tabellen eingerichtet werden, die aber alle nur wenig Inhalt haben. Die Informationen, die nicht in Objekttypen gespeichert sind, sind für Abfragen nicht verloren. Der Grund dafür ist, dass der XML20-Typ eine XPATH-Funktionalität zur Verfügung stellt, der es ermöglicht, Elemente und Attribute des Dokuments mit XPATH zu erreichen. Mit einer kombinierten SELECT und XPATH-Abfrage ist es also möglich, jede Information zu erreichen. Multimedia Indexing Framework1Auto
Auto PC
Auto PDA_Phone
2AutoDas Multimedia-Indexing Framework stellt effizente Indizierungsservices für das MMDBMS zur Verfügung. Neue Indextypen können sogar ohne Veränderung der Interfacedefinitionen hinzugefügt werden. Ein wichtiger Teil des Indizierungsframeworks ist das GistService. Auto PC
Auto PDA_Phone
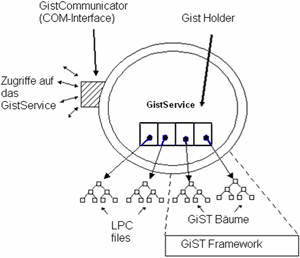
AutoDas GistService (Abbildung Multimedia Indexing Framework) wird im
externen Adressraum realisiert und ist in C++ implementiert. Es läuft
als eigener Prozess (Service) in der Betriebssystemumgebung und verwaltet
alle verfügbaren Zugriffsmethoden. Die aktuelle Version bietet Unterstützung
für das GiST431
Framework (Generalized Search Trees - zum Beispiel X-tree und SR-tree)
und weitere Zugriffsmethoden, die nicht auf balancierten Bäumen beruhen
(z.B. LPC-files). Das Service ist in zwei Komponenten aufgeteilt:
GistCommunicator und GistHolder. Der GistCommunicator ist ein COM-Objekt
(component object model), das für die Interprozesskommunikation zwischen
der Datenbank und den implementierten Zugriffsmethoden verwendet wird.
Der GistCommunicator stellt die notwendige Funktionalität (z.B. Erstellen,
Einfügen, Löschen) zur Verfügung, um auf die Indexstrukturen zuzugreifen.
Der GistHolder managt alle zur Zeit laufenden Indexbäume und die Zugriffe
auf diese. Jeder Indexbaum wird durch eine globale und eindeutige
Kennung identifiziert, die zum Zugriffsprozess weitergeleitet wird. Bibliographie2AutoMIR99 DIS03 MAR02 SMO02 DK03 Kos04 |
| (empty) |