| Title: |
Physikalische Indexstrukturen für Multimedia-Datenbanken - Effizientes
inhaltsbasiertes Retrieval in MMDB |
||
|---|---|---|---|
| Abstract: | Die LU gliedert sich in drei Teile. Nach einer kurzen Einführung und Wiederholung der Signaturvektoren wird das Erstellen von Indexstrukturen behandelt, wobei auf die Dimensionsreduktion von Signaturvektoren und auf mehrdimensionale Zugriffsstrukturen eingegangen wird. Den Abschluss der LU bilden einige Arten von inhaltsbasierten Anfragen, die von mehrdimensionalen Zugriffsstrukturen unterstützt werden. | ||
| Status: | Review II: done | Version: | 8.0 |
| History: |
Referenzen nächste Folie gelöscht Acronyme, Absätze, Wordanfürhungszeichen done. Review von Prof. Kosch eingearbeitet. Unbekannte Character removed. |
||
| Author 1: | Harald Kosch | E-Mail: | harald.kosch@itec.uni-klu.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Universität Klagenfurt - Institut für Informatik-Systeme | ||
Einleitung1Auto
SignaturvektorenBeispiel für einen Signaturvektor: Auto PC
Auto PDA_Phone
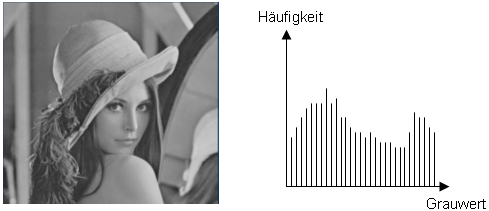
2AutoFür das inhaltsbasierte Retrieval in multimedialen Datenbanksystemen werden Signaturvektoren verwendet, die den Bildinhalt repräsentieren. Dabei werden Low-level Merkmale (wie zum Beispiel Farbverteilungen, Textur oder ähnliches) durch einen Signaturvektor beschrieben. Die Signaturvektoren werden dabei aus den Bilddaten selbst berechnet (siehe LU Ähnlichkeitsabfragen und Demosysteme). SignaturvektorenEin Beispiel für einen Signaturvektor wäre etwa ein Grauwert-Histogramm eines Schwarz-Weiß-Bildes. Hier werden die Grauwertverteilungen im Bild dargestellt. Auto PC
Auto PDA_Phone
AutoDie obige Abbildung zeigt, wie die Grauwerte eines Schwarz-Weiß-Bildes als Histogramm dargestellt werden können. Diese Werte können dann im Signaturvektor gespeichert werden. Erstellen von Indexstrukturen1AutoAuto PC
Auto PDA_Phone
Dimensionsreduktion
Dimensionsreduktion durch Transformationen
Verschiedene Transformationstechniken
Dimensionsreduktion durch raumfüllende Kurven
Auto PC
Auto PDA_Phone
2AutoAuto PC
Auto PDA_Phone
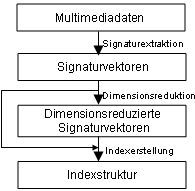
AutoObige Abbildung zeigt den Weg der Erstellung von Indexstukturen,
der von den Multimediadaten zur Indexstruktur führt. Aus den Multimediadaten
werden die low-level Merkmale extrahiert (Signaturextraktion) und
in Signaturvektoren gespeichert. Diese Signaturvektoren haben unter
Umständen eine hohe Dimension, die von der Genauigkeit der Extraktionsalgorithmen
abhängt. Wenn z. B. für ein Farbhistogramm 1024 Werte gewählt werden,
und jeder Wert durch 8 bit repräsentiert wird, nimmt ein Vektor einen
Speicherbereich von 1 KB ein, was für eine große Datenbank sehr viel
ist. Deswegen ist es angebracht, eine distanzerhaltende Dimensionsreduktion
durchzuführen (siehe nächster Abschnitt). Bei geringen Dimensionen
kann die Dimensionsreduktion sicherlich entfallen. DimensionsreduktionDie steigenden Ansprüche in Applikationen fordern, immer komplexere
Signaturvektoren speichern zu können, die hohe Dimensionen haben können.
Das Ziel der Dimensionsreduktion ist es, einige nicht signifikante
Dimensionen zu verschmelzen, um so die Höhe zu verringern. Trotzdem
soll die Distanz erhalten bleiben, das heißt alle Punkte sollten eine
ähnliche Nachbarschafts- oder Distanzbeziehung wie vor der Transformation
haben. Eine Dimensionsreduktion wird deswegen durchgeführt, weil die
Effizienz der Indexstrukturen mit der Höhe der Dimensionen abnimmt.
Dimensionsreduktion durch TransformationenUm durch Transformation eine Reduktion der Dimensionen von Signaturvektoren zu erreichen, muss die Basis der Vektoren geändert werden. Das geschieht, indem sie in orthonormale Vektoren übergeführt werden. Diese Überführung kann mit einer mathematischen Prozedur (z. B.: Gram-Schmidt) durchgeführt werden, in der eine orthonormale Basis für den Vektorraum gesucht wird. Nach dieser Transformation besteht nun die Möglichkeit, in den orthonormalen Vektoren mathematisch zu überprüfen, welche Koeffizienten für diesen Vektorraum von Bedeutung sind, und welche weniger. Je nach Art der Daten wird hier eine andere Methode verwendet (siehe nächster Abschnitt). So kann man wichtige und unwichtige Dimensionen unterscheiden, indem man ihre Wichtigkeit und ihren Einfluss (großer Einfluss, geringer Einfluss) betrachtet. Da die unwichtigen Koeffizienten mit nur geringem Einfluss auf den gesamten Vektorraum nun herausgefiltert und entfernt werden können, entsteht ein Signaturvektor mit weniger Dimensionen. Verschiedene Transformationstechniken
AutoIn obiger Tabelle werden die verschiedenen Techniken der Transformation und ihre Anwendungsgebiete dargestellt. Die Karhunen-Loeve-Transformation wird verwendet, wenn geclusterte Daten vorhanden sind. Fourier bzw. FFT wird bei periodischen Daten angewendet, Wavelet bei unstetigen Daten und die DCT419 (Diskrete Cosinus Transformation) bei lokal korrelierenden Daten. Dimensionsreduktion durch raumfüllende KurvenDas zweite Mittel, um die Dimensionen der Signaturvektoren reduzieren
zu können, geschieht durch die Anwendung raumfüllender Kurven. Bei
dieser Vorgehensweise versucht man, den mehrdimensionalen Raum durch
eine einzige Kurve darzustellen. Dadurch wird dann die Verwendung
einer eindimensionalen Indexstruktur möglich. Hilbertkurven sind rekursiv definierte raumfüllende Kurven, die sich zur Parametrisierung mehrdimensionaler Datensätze verwenden lassen. Auto PC
Auto PDA_Phone
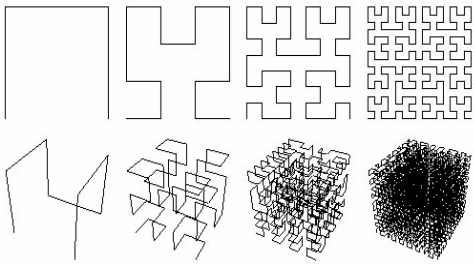
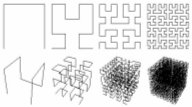
AutoIn dieser Abbildung sieht man die Hilbert-Kurven H1 bis H4 im zweidimensionalen Raum (oben) und im mehrdimensionalen Raum (unten). Für den eindimensionalen Raum gilt, dass jede Hilbertkurve links unten beginnt und rechts unten endet. H1 besteht aus drei geraden Strichen, H2 setzt sich aus vier Kurven H1 und 3 geraden Verbindungsstrichen zusammen. Für jede weitere Hilbertkurve Hn gilt, dass sie aus vier Kurven Hn-1 und 3 Verbindungsstrichen besteht, wobei von den vier Kurven Hn-1 jeweils zwei nach links orientiert sind, und die beiden anderen nach rechts. Überblick über Indexstrukturen1Mehrdimensionale Indexstrukturen
R-BaumAuto PC
Auto PDA_Phone
Auto
R+ - Baum
R* - Baum
SS-Baum
SR-Baum
TV-Baum
X-Baum
2Mehrdimensionale IndexstrukturenHerkömmliche Indexstrukturen wie B-Bäume können lediglich eindimensionale
Daten speichern und suchen. In vielen Anwendungsgebieten gewinnen
jedoch auch mehrdimensionale Daten an Bedeutung. Die Anforderungen
an Indexstrukturen, die auch mit mehrdimensionalen Daten arbeiten
können, steigen. Am effektivsten für mehrdimensionale Räume haben
sich der R-Baum und seine verschiedenen Varianten gezeigt. R-BaumAuto PC
Auto PDA_Phone
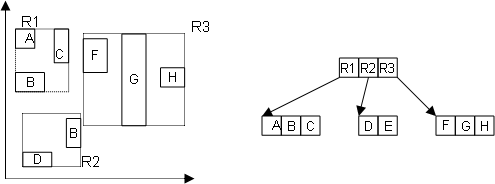
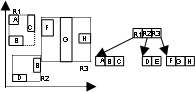
AutoMit Hilfe der Abbildungen R-Baum (a) und (b) soll der Aufbau des
R-Baumes näher betrachtet werden. Es können wie beim B-Baum verschiedene Operationen ausgeführt werden. Das Suchen, Einfügen und Löschen eines Datenobjektes geschieht analog zum B-Baum. In R-Bäumen sind Überlappungen der MBR418s erlaubt, dadurch steigen die Kosten der Seitenzugriffe und die Effizienz wird reduziert. Aus diesem Grund ist es erforderlich, Überlappungen zu vermeiden bzw. minimal zu halten. Vermeidung wäre beim R-Baum allerdings nur möglich, wenn die Überlappungen aller Datenpunkte im voraus bekannt wären. Da aber der R-Baum eine dynamische Indexstruktur ist, ist dies in der Praxis nicht der Fall. Da vor allem in hochdimensionalen Räumen das Hauptproblem des R-Baumes die vielen Überlappungen (bis zu 90%) sind und damit verbunden eine schlechte Performance, wurde eine Reihe von Varianten des R-Baums entwickelt, auf die im Folgenden näher eingegangen wird:
R+ - BaumBeim R+-Baum, einer Erweiterung zum R-Baum, sind Überlappungen der
MBR418s nicht
erlaubt. Wenn es zu einer Überlappung kommt, wird das Objekt in alle
Knoten, deren MBR418
es überlappt, eingefügt. Der Eintrag ist dann einfach in mehreren
Blättern vorhanden. R* - BaumDer R*-Baum ist eine Weiterentwicklung des R+-Baums. Er ermöglicht
durch einen ausgeklügelten Splitalgorithmus eine weitere Effizienzsteigerung.
SS-BaumDer SS-Baum ist dem R*-Baum sehr ähnlich. Er verwendet wie der R*-Baum eine Wiedereinfüge-Strategie, um die Überlappung der MBR418s zu verkleinern. Diese Strategie weist nur leichte Unterschiede auf. Beim SS-Baum werden anstatt den MBR418s Kreise als bounding boxes (Seitenregionen) benutzt. Beim Einfügen wird die Ähnlichkeit des Schwerpunktes eines Kreises ermittelt und so eine Ordnung im Baum erzeugt. Dies führt ebenfalls zu einer verbesserten Performanz im Gegensatz zum R*-Baum. SR-BaumDer SR-Baum ist eine Erweiterung des R*-Baums und des SS-Baums. Er
benutzt eine Kombination aus Rechtecken und Kreisen als Seitenregion,
wobei die Rechtecke aus dem R*-Baum übernommen wurden, und die Kreise
aus dem SS-Baum. Durch diese Kombination können die beschriebenen
Objekte in kleinere Regionen aufgeteilt werden, die dadurch disjunkter
sind. Das steigert die Effizienz beim Suchen im Baum. TV-BaumDer TV-Baum (Telescope Vector Baum) hat eine ähnliche Struktur wie der R-Baum und wurde speziell für Vektoren entwickelt. Er verwendet eine variierende Anzahl von Dimensionen zur Indizierung. In inneren Knoten werden die Vektoren durch niedrig-dimensionale Vektoren approximiert (eine Art Dimensionsreduktion). Dadurch soll es möglich werden, auch sehr hoch-dimensionale Daten zu indizieren. Die verwendeten Dimensionen sind abhängig von der Anzahl der zu indizierenden Objekte und von der aktuellen Baumhöhe. Bei einem Knoten, der sich nahe an der Wurzel befindet, betrachtet man weniger Dimensionen als bei Knoten, die weiter von der Wurzel entfernt sind. Die Berechnung, welche Dimensionen zu verwenden sind, wird mittels einer Teleskop-Funktion durchgeführt. Meist ist die Teleskop-Funktion so realisiert, dass sie irrelevante Teilbäume einfach abschneidet. Das erfordert eine gewisse Ordnung im Baum, wichtige Merkmale befinden sich somit näher bei der Wurzel als unwichtige. Um diese Hierarchie im Baum zu erreichen kann z. B. die Karhunen-Loeve-Transformation angewendet werden. Beim TV-Baum sind, wie beim R*-Baum, Überlappungen erlaubt. Das kann hier aber zu Problemen bei Knoten führen, die unterschiedliche Dimensionen zur Indizierung benutzen. Ein weiteres Problem bei den TV-Bäumen ist, dass die ersten Dimensionen sehr oft den gleichen Wert enthalten, d.h. bei niedrig-dimensionalen Einträgen kann man die Vektoren nicht mehr unterscheiden. X-BaumDer X-Baum (eXtended tree) ist eine Weiterentwicklung des R*-Baums, bei dem Splitting möglichst vermieden werden soll. Seine Bedeutung liegt vor allem in hochdimensionalen Räumen. Es wird versucht, eine Überlappung von Knoten zu vermeiden, was speziell bei einer sehr großen Anzahl von Dimensionen problematisch werden kann. Durch Einführen von sogenannten Superknoten können diese Überlappungen vermieden werden. Die Knoten können erweitert werden und haben bis zur doppelten Kapazität eines "normalen" Knotens. Falls sich ein Split nicht lohnt, weil resultierende Knoten eine zu starke Überlappung hätten, werden die einfachen Knoten einfach zu solchen Superknoten umgewandelt, und dadurch die Kapazität erhöht werden. Anhand des verbesserten Splitting-Algorithmus wird durch eine sogenannte Splithistorie der Split mit der minimalsten Überlappung gefunden. Dadurch kann die Performance im Vergleich zum TV-Baum und zum R*-Baum deutlich verbessert werden. Der X-Baum kommt in vielen Multimedia-Datenbanksystemen zur Anwendung. Inhaltsbasierte Anfragen1AutoAuto PC
Auto PDA_Phone
Anfragearten für MMDB
Nächste-Nachbar-Suche
2AutoAuto PC
Auto PDA_Phone
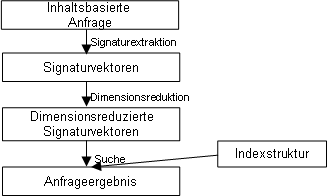
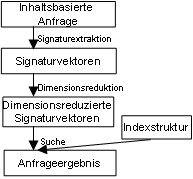
AutoAbbildung Inhaltsbasierte Anfragen zeigt den Ablauf von der Eingabe einer inhaltsbasierten Anfrage bis zum Ergebnis der Anfrage. Es wird zuerst eine Signaturextraktion durchgeführt, wodurch wieder Signaturvektoren entstehen. Durch eine Dimensionsreduktion, falls notwendig, hochdimensionaler Vektoren entstehen dimensionsreduzierte Signaturvektoren. Mit einer bestimmten Indexstruktur kann dann die Suche ausgeführt werden und es wird das Anfrageergebnis geliefert. Anfragearten für MMDBEs gibt zwei verschiedene Anfragearten für Multimediadatenbanken:
Ähnlichkeitsanfragen und Bereichsanfragen. Die zweite Anfrageart für Multimediadatenbanken ist die Bereichsanfrage. Hier ist eine bestimmte Region mit gewissen Eigenschaften als Anfragebereich gegeben, und es werden alle Objekte gesucht, die diese Region schneiden. Als Ergebnis erhält man also alle Objekte, die die Merkmale dieser angegebenen Region aufweisen. Eine Verkürzung der Rechenzeit kann dadurch erreicht werden, dass gewisse Knoten ignoriert werden - und zwar jene, deren Schnitt mit dem Anfragebereich unter einer gegebenen Schwelle liegt. Nächste-Nachbar-SucheDie Nächste-Nachbar-Suche kann als Bereichsanfrage mit variabler Radiuslänge betrachtet werden. Die Voraussetzung ist, dass die Knoten durch Hüllen eingegrenzt sind (Minimum Bounding Rectangles - MBR418s). Die Nächste-Nachbar-Suche ist somit für R-Bäume und Varianten davon geeignet. Durch die Nächste-Nachbar-Suche kann die Suche sehr schnell ausgeführt werden, es wird auch eine schnelle Reduzierung des Radius erreicht. Die Reduzierung des Radius bei der Nächste-Nachbar-Suche wird dadurch verwirklicht, indem noch nicht besuchte Knoten in eine Prioritätswarteschlange eingeordnet werden. Knoten, die an der ersten Stelle in dieser Warteschlange stehen, werden zuerst untersucht. Die Priorität wird nach verschiedenen Gesichtspunkten geordnet: Ausschlaggebend sind der minimale Abstand zwischen dem Anfragepunkt und dem Knotenschwerpunkt, der minimale Abstand zwischen dem Anfragepunkt und dem Knoten und das Minimum der maximalen Distanz. Bibliographie2AutoKos03 LL93 BKS+90 |
| (empty) |