| Title: | Fallbeispiel: SR-Bäume | ||
|---|---|---|---|
| Abstract: | In
der LU 7 wird der SR-Baum als ein Fallbeispiel einer Indexstruktur in
Multimediadatenbanken präsentiert. Der SR-Baum ist eine Indexstruktur
für hochdimensionale Nächste-Nachbar-Suchen. Zusätzliche Informationen zum SR-Baum findet man auf: http://research.nii.ac.jp/~katayama/homepage/research/srtree/ |
||
| Status: | Review II: done. | Version: | 8.0 |
| History: |
Codeformatierung siehe LU6+7.ppt - Done, please check and remove xIgnore. Done. Review II bis auf Akronyme komplett berücksichtigt. Acronyme, Absätze, Wordanführungszeichen done. Review von Prof. Kosch eingearbeitet. Unbekannte Character removed. |
||
| Author 1: | Harald Kosch | E-Mail: | harald.kosch@itec.uni-klu.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Universität Klagenfurt - Institut für Informatik-Systeme | ||
SR-Baum1Einführung
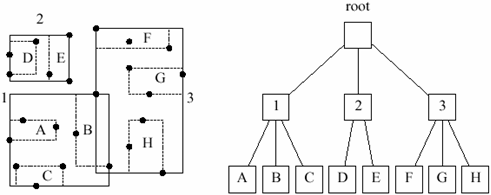
2EinführungSR-Baum420 ist eine Abkürzung für Sphere/Rectangle-Baum. Diese Indexstruktur ist eine Erweiterung des R*-Baums und des SS-Baums. Der R*-Baum verwendet Rechtecke, der SS-Baum Kreise als Seitenregionen. Das Merkmal des SR-Baum420s ist die kombinierte Verwendung von Kreisen und Rechtecken als bounding boxes. Die Seitenregionen werden durch eine Schnittmenge der bounding rectangles und bounding boxes dargestellt. R* - Baum1Die Struktur des R*-BaumsAuto PC
Auto PDA_Phone
2Die Struktur des R*-BaumsAuto PC
Auto PDA_Phone
AutoWie Abbildungen Struktur des R*-Baums (a) und (b) zeigen, werden beim R*-Baum Rechtecke als Seitenregionen verwendet. Dabei sind Überlappungen der bounding rectangles erlaubt. Die Blattknoten im resultierenden R*-Baum beinhalten Einträge von Datenobjekten, die durch die Hierarchie des Baumes in Seitenregionen eingeteilt sind. Durch Minimierung von Überlappungen und Umfang der Seitenregionen wird eine Optimierung erreicht. Der Einfügealgorithmus im R*-Baum kann beim Einfügen neuer Datenobjekte ein Löschen und Wiedereinfügen anderer Objekte verursachen. Diese Vorgangsweise führt zu einer weiteren Verkleinerung der Überlappung der MBR418s. SS-Baum1Die Struktur des SS-BaumsAuto PC
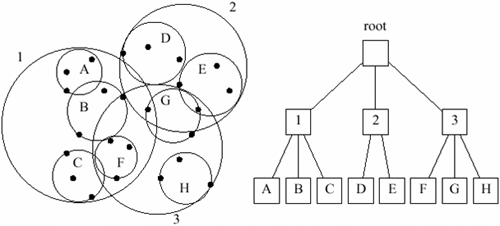
Auto PDA_Phone
2Die Struktur des SS-BaumsAuto PC
Auto PDA_Phone
AutoAbbildungen Die Struktur des SS-Baums (a) und (b) zeigen die Struktur des SS-Baums. Man sieht, dass im Gegensatz zum R*-Baum statt Rechtecken Kreise als Seitenregionen verwendet werden, die sich auch überlappen können. Im resultierenden SS-Baum beinhalten die inneren Knoten die Informationen aller abstammenden Knoten und verlinken so zu den Blattknoten, welche die Einträge der Datenobjekten umfassen. Beim Einfügen wird die Ähnlichkeit des Schwerpunktes eines Kreises ermittelt und eine Hierarchie im Baum erzeugt. Dadurch wird wieder eine Ordnung der Datenobjekte erreicht. SR-Baum1Seitenregionen im SR-Baum
Eigenschaften des SR-Baums
Vergleich R*-Baum, SS-Baum und SR-BaumVergleich R*-Baum, SS-Baum und SR-Baum
Auto* Die Werte für Durchmesser und Volumen wurden einem Test entnommen, der mit 16-dimensionalen Punktdaten durchgeführt wurde. Die Struktur des SR-BaumsAuto PC
Auto PDA_Phone
Einfügealgorithmus
Löschalgorithmus
Nächste-Nachbar-Suche im SR-Baum
Minimale Distanz (MINDIST)Euklidische Distanz zwischen dem Anfragepunkt und der Seitenregion Minimax-Distanz (MINMAXDIST)minimaler Wert aller maximalen Entfernungen zwischen den Anfragepunkten und den jeweiligen Punkten auf allen n Achsen Pruning bei der Suche in SR-Bäumen
Rekursive Prozedur Nächste-Nachbar-Suche (Blattknoten)If Node.type = LEAF then For I := 1 to Node.count /* Entfernung des Punktes zur Region berechnen */ dist := objectDist(Pt, Node.region) /* ist die berechnete Entfernung kleiner als die der vorigen Region, wird dieses Blatt als nächster Nachbar bestimmt */ if (dist < Nearest.dist) then Nearest.dist := dist Nearest.region := Node.region Rekursive Prozedur Nächste-Nachbar-Suche (innere Knoten)/* kein Blattknoten => ordne, sortiere, führe Pruning durch & besuche nächsten Knoten */ Else erzeugeSohnListe(Punkt, Knoten, sohnListe) /* Liste sortieren, damit der nächste Sohn zuerst ausgewählt werden kann */ sortiereSohnListe(sohnListe) /* downward pruning durchführen */ anzahl = pruneSohnListe(Knoten, Punkt, Nächster, sohnListe) For I := 1 to anzahl KnotenNeu := Knoten.aktuellerSohn /*mit nächstem Sohn der Verzweigung Suche weiterführen */ nearestNeighborSearch(KnotenNeu, Punkt, Nächster) /* upward pruning durchführen */ anzahl := pruneSohnListe(Knoten, Punkt, Nächster, sohnListe) Stärken des SR-Baums
Schwächen des SR-Baums
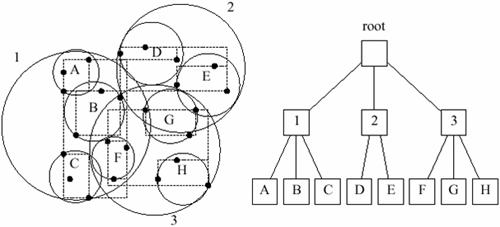
2Seitenregionen im SR-BaumDas unterscheidende Merkmal des SR-Baum420s ist die kombinierte Verwendung von Rechtecken und Kreisen als Seitenregionen. Dabei ist der Durchmesser einer solchen Seitenregion in einem SR-Baum420 gleichzusetzen mit:
Eigenschaften des SR-BaumsEntsprechend verschiedener Performancetests haben bounding rectangles und bounding spheres verschiedene Vor- und Nachteile. Bounding rectangles gliedern die Punkte in Regionen mit kleinerem Volumen. Sie haben jedoch meist einen größeren Durchmesser als bounding spheres. Das ist vor allem in hochdimensionalen Räumen der Fall. Bounding spheres hingegen gliedern die Punkte in Regionen mit geringerem Durchmesser. Sie haben jedoch meist ein höheres Volumen als bounding rectangles.Bounding rectangles haben also Vorteile in Bezug auf ihr Volumen, bounding spheres hingegen sind günstiger wenn man den Durchmesser betrachtet. SR-Bäume nutzen die Vorteile beider Strukturen, darauf wird nun in den nächsten Abschnitten näher eingegangen. Der SR-Baum420 nützt die Vorteile von bounding rectangles und spheres und kombiniert so die Verwendung von Rechtecken und Kreisen als Seitenregionen. Da die Eigenschaften der beiden Seitenregionen zueinander komplementär sind, erlaubt es die Schnittmenge von bounding rectangles und bounding spheres, die Punkte in Regionen mit sowohl geringem Volumen als auch geringem Durchmesser aufzuteilen. Es wurde gezeigt, dass durch diese Kombination der Strukturen, die Performanz deutlich erhöht werden konnte (vor allem bei den hochdimensionalen Daten in Bild- oder Videoanwendungen). Vergleich R*-Baum, SS-Baum und SR-BaumVergleich R*-Baum, SS-Baum und SR-Baum
Auto* Die Werte für Durchmesser und Volumen wurden einem Test entnommen, der mit 16-dimensionalen Punktdaten durchgeführt wurde. Abbildung Vergleich R*-Baum, SS-Baum und SR-Baum420 zeigt den Vergleich zwischen R*-Baum, SS-Baum und SR-Baum420. Man sieht die Form der Seitenregionen, die die Punktdaten umgeben (R*-Baum mit Rechteck, SS-Baum mit Kreis, SR-Baum420 mit der Schnittmenge von Rechteck und Kreis). Die Strategie bei der Konstruktion des Baumes beschäftigt sich beim R*-Baum mit der Minimierung des Volumens und möglichen Überlappungen, beim SS-Baum und SR-Baum420 hingegen mit der Minimierung des Durchmessers. Man erkennt außerdem, dass der Durchmesser beim R*-Baum weit größer ist, als beim SS-Baum und SR-Baum420. Ebenso ist das Volumen des SS-Baums sehr hoch, beim R*-Baum und SR-Baum420 hingegen niedriger. Die Daten von Durchmesser und Volumen wurden einem Test entnommen, der mit 16-dimensionalen Punktdaten durchgeführt wurde. Quelle: Kat03 Die Struktur des SR-BaumsAuto PC
Auto PDA_Phone
AutoWie sich in den obigen Abbildungen gut erkennen lässt, basiert die Struktur des SR-Baum420s auf dem Aufbau des R*-Baums und des SR-Baum420s. Die ineinander geschachtelte Hierarchie der Seitenregionen bildet die Struktur des SR-Baum420s. Eine Seitenregion besteht aus den Punkten, die in der Schnittmenge eines Rechtecks und eines Kreises liegen, wie schon zuvor beschrieben. EinfügealgorithmusDer Einfügealgorithmus in einem SR-Baum420 basiert auf dem des SS-Baums, der sich auf den Schwerpunkt in den bounding spheres stützt. Dieser Algorithmus ist besonders effektiv bei Nächste-Nachbar-Suchen. Beim Durchsuchen wird beim Herabsteigen im Baum derjenige Teilbaum ausgewählt, der den ähnlichsten Schwerpunkt zu dem neuen Eintrag hat. Der einzige Unterschied zum Algorithmus im SS-Baum besteht darin, dass im SR-Baum420 nach dem Einfügen beide Seitenregionen (bounding spheres und bounding rectangles) aktualisiert werden müssen. Das Aktualisieren der bounding rectangles erfolgt gleich wie im R*-Baum, das Aktualisieren von bounding spheres unterscheidet sich jedoch von der Strategie im SS-Baum. Wie die kreisförmigen Seitenregionen aktualisiert werden, wird im nächsten Abschnitt dargestellt. LöschalgorithmusDer Löschalgorithmus im SR-Baum420 funktioniert ähnlich wie der im R*-Baum und im SS-Baum. Das Löschen eines Eintrags kann verursachen, dass ein Knoten nicht mehr genug ausgelastet ist, da sich zu wenig oder gar keine Einträge mehr darin befinden. Ist das der Fall, werden zu wenig ausgelastete Blätter oder Knoten entfernt und alle verwaisten Einträge neu eingefügt. Wenn das Löschen eines Eintrags keine Unterauslastung von Blättern oder Knoten verursacht, kann er einfach entfernt werden. Nächste-Nachbar-Suche im SR-BaumDer Algorithmus der Nächste-Nachbar-Suche im SR-Baum420 realisiert eine geordnete Tiefensuche und besteht aus zwei Phasen. In der ersten Phase wird eine Anzahl an Punkten gefunden, die der Anfrage am nächsten sind. Aus diesen Punkten wird eine Menge an möglichen Kandidaten gebildet. Die zweite Phase beschäftigt sich mit der Überprüfung dieser Menge an möglichen Kandidaten, indem der Algorithmus jedes Blatt besucht, dessen Seitenregion sich mit dem Bereich der Kandidatenmenge überlappt. Dabei wird der Baum von oben nach unten in einem tiefenorientierten Suchverfahren durchlaufen. In jedem besuchten Knoten wird die Entfernung des Anfragepunkts zur Region jedes Sohnes berechnet, wobei der Sohn mit der geringsten Distanz vor den anderen Söhnen besucht wird. Nachdem alle Blätter besucht wurden, wird der letzte Kandidat als Ergebnis der Suche zurückgeliefert. Minimale Distanz (MINDIST), Minimax-Distanz (MINMAXDIST)Für die Durchführung der Nächste-Nachbar-Suche in SR-Bäumen werden zwei Entfernungen betrachtet: Die minimale Distanz und die Minimax-Distanz. Die Minimale Distanz (MINDIST) wird als euklidische Distanz zwischen dem Abfragepunkt und der behandelten Seitenregion berechnet. Die Minimax-Distanz (MINMAXDIST) ist der minimale Wert aller maximalen Entfernungen zwischen den Anfragepunkten und den jeweiligen Punkten auf allen n Achsen. Durch die Berechnung der MINDIST und der MINMAXDIST beim Ermitteln des nächsten Nachbarn kann die Entfernung zwischen den Anfragepunkten und den Region besser abgeschätzt werden. Abbildung Nächste-Nachbar-Suche zeigt graphisch den Ablauf der Nächste-Nachbar-Suche im dreidimensionalen Raum. Ausgehend vom Anfragepunkt P wird die minimale Distanz (MINDIST) und die Minimax-Distanz (MINMAXDIST) zur Seitenregion gemessen. Pruning bei der Suche in SR-BäumenDie Suche in SR-Bäumen kann durch Pruning erheblich beschleunigt werden. Beim Pruning werden Teilbäume, in denen sich das gesuchte Objekt nicht befinden kann, abgeschnitten und verworfen, damit sie nicht unnötig weiter durchlaufen werden. Eine bestimmte Region kann aus verschiedenen Gründen verworfen werden:
Rekursive Prozedur Nächste-Nachbar-SucheDie Prozedur Nächste-Nachbar-Suche ist rekursiv implementiert. In dem Fall, dass der besuchte Knoten ein Blatt ist, wird der Knoten untersucht. BlattknotenIf Node.type = LEAF then For I := 1 to Node.count /* Entfernung des Punktes zur Region berechnen */ dist := objectDist(Pt, Node.region) /* ist die berechnete Entfernung kleiner als die der vorigen Region, wird dieses Blatt als nächster Nachbar bestimmt */ if (dist < Nearest.dist) then Nearest.dist := dist Nearest.region := Node.region AutoEs wird für alle Einträge des Knotens die Entfernung zwischen dem Anfragepunkt und der Region des untersuchten Knotens ermittelt. Ist diese neu ermittelte Entfernung kleiner als die aktuelle Entfernung, wird diese Region als die nächeste Region verwendet, der nächste Nachbar wurde gefunden. Falls der besuchte Knoten in der Nächste-Nachbar-Suche kein Blattknoten ist, werden die besuchten Knoten geordnet, sortiert, ein downward und upward pruning durchgeführt und die Prozedur mit dem nächsten Sohn rekursiv aufgerufen, dessen Seitenregion dem Anfragepunkt am nächsten ist (siehe Kommentare im Programmcode): innere KnotenElse erzeugeSohnListe(Punkt, Knoten, sohnListe) /* Liste sortieren, damit der nächste Sohn zuerst ausgewählt werden kann */ sortiereSohnListe(sohnListe) /* downward pruning durchführen */ anzahl = pruneSohnListe(Knoten, Punkt, Nächster, sohnListe) For I := 1 to anzahl KnotenNeu := Knoten.aktuellerSohn /*mit nächstem Sohn der Verzweigung Suche weiterführen */ nearestNeighborSearch(KnotenNeu, Punkt, Nächster) /* upward pruning durchführen */ anzahl := pruneSohnListe(Knoten, Punkt, Nächster, sohnListe) Stärken des SR-BaumsDie Stärken des SR-Baum420s bauen auf die Einteilung der Seitenregionen in Kreise und Rechtecke auf. Die Seitenregionen haben ein geringeres Volumen als im R*-Baum und im SS-Baum und der Durchmesser ist in etwa gleich gering wie im SS-Baum. Durch diese Eigenschaften kann der SR-Baum420 die Punkte in Regionen mit kleinerem Volumen und geringem Durchmesser aufteilen, die dadurch disjunkter sind. Durch die Reduzierung des Volumens und des Durchmessers erhöht sich außerdem die Performanz der Nächste-Nachbar-Suche. Schwächen des SR-BaumsEin Nachteil beim SR-Baum420 ist, dass der Aufwand für die Erzeugung höher ist, als beim SS-Baum. Ein weiteres Problem hängt mit dem Verzweigungsgrad des SR-Baum420s zusammen: Die Verzweigung eines Indexbaumes nimmt ab, je höher die Dimensionalität ist, da die Größe eines Eintrags in einem Knoten mit zunehmender Dimensionalität zunimmt. Da ein Knoteneintrag eines SR-Baum420s eine bounding sphere und ein bounding rectangle enthält, ist seine Größe jedoch drei Mal so groß wie zum Beispiel ein Knoteneintrag im SS-Baum, oder eineinhalb Mal so groß wie im R*-Baum. Deshalb beträgt der Verzweigungsgrad beim SR-Baum420 nur ein Drittel vom SS-Baum und zwei Drittel vom R*-Baum. Eine Reduzierung der Verzweigungen kann erfordern, dass bei Anfragen mehr Knoten gelesen werden müssen. Möglicherweise wird dadurch die Performanz bei Anfragen beeinträchtigt. Bibliographie2AutoKat03 |

| (empty) |