| Title: | Audio Retrieval Überblick | ||
|---|---|---|---|
| Abstract: | Diese Lerneinheit liefert einen Überblick und Motivation für Audioretrieval. Es werden die wichtigsten Features für Audiodateien beschrieben und Algorithmen vorgestellt, mit deren Hilfe Sprache von Musik unterschieden werden kann. | ||
| Status: | final | Version: | 2005-01-18 |
| History: |
2005-01-18 (Tthomas Migl): math-xml hinzugefügt, Tabelle korrigiert 2004-09-23 (Thomas Migl). Abb. explanation korrigiert 2004-09-14 (Thomas Migl): alle Abbildungen hinzugefügt 2004-09-13 (Thomas Migl): Abb hinzugefügt 2004-09-07 (Thomas migl): Text finalisiert, eine Abb_pc, sonst drafts 2004-03-12 (Robert Fuchs): Closed for 50% Content Deadline import in Scholion. 2004-03-12 (Robert Fuchs): Fixed bugs in content tagging. 2004-03-10 (Thomas Migl): LOD1 und abstract added 2004-03-05 (Robert Fuchs): Imported and tagged content from "m5-LU21-Überblick.doc". |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | (empty) | ||
Einleitung zhan2001 gouj2001, 11Motivation
Audioretrieval versus Videoretrieval
2MotivationDie automatische Segmentierung, Indizierung und Abfrage von audiovisuellen Daten gewinnt angesichts der schnell wachsenden Anzahl an Material in Bereichen wie Medienproduktion, Management audiovisueller Daten, Video on Demand (VOD), Ausbildung etc. immer mehr an Bedeutung. Fernseh- und Filmarchive beherbergen eine gigantische Anzahl an audiovisuellen Material. Nur wenn diese ordentlich indiziert sind, können die verschiedenen User mit diesem Material auch wirklich etwas anfangen. So kann ein User schnell Material aus dem Archiv filtern, welches für einen Dokumentationsfilm geeignet ist. Ein anderer wiederum wird aus dem selben Archiv Material erhalten, das für einen Werbespot geeignet ist usw. Eine händische Segmentierung und Indizierung des Materials wird auf Grund der Fülle immer schwieriger. Einen Ausweg daraus soll eine Automation der Segmentierung und Indizierung, welche auf inhaltsbezogene (engl: content-based) Analyse des Videomaterials basiert, bieten. Audioretrieval versus VideoretrievalZur Zeit wird für die automatische Segmentierung und Indizierung von Videomaterial das Hauptaugenmerk auf den visuellen Inhalt gelegt (Farbhistogramm, Bewegungsvektoren, Key-Frames). Der akustische Inhalt wird dabei oft außer acht gelassen, und das zu unrecht: In vielen Fällen liefert der akustische Teil aufschlussreichere Informationen, die zu einer erfolgreichen Segmentierung und Indizierung notwendig sind. Audioretrieval versus VideoretrievalDialog zweier Personen in einem Spielfilm. Betrachtet man diese Szene ohne Ton, so wird man eine Aneinanderreihung von Szenen sehen, einmal Person 1, dann Person 2, dann beide, vielleicht mal Hände usw. Und das ganze noch aufgenommen von verschiedenen Kamerapositionen. Eine automatische Segmentierung rein nach visuellem Inhalt wird zwischen den verschiedenen Szenen keinen Zusammenhang erkennen, sondern jede Bildeinstellung als eigenes Segment auszeichnen. Untersucht man hingegen nur den akustischen Inhalt der Szene, wird der Dialog als Sprache erkannt werden. In diesem Fall wird dieser Dialog dann auch wirklich als eine Einheit segmentiert werden. Audioretrieval versus VideoretrievalMan sucht aus einem Archiv alle Szenen, die eine Kriegsschlacht beinhalten. Der Bildinhalt solcher Szenen kann so mannigfaltig sein, dass eine Suche nach visuellen Kriterien wenig Erfolg bringen wird. Beschränkt man sich bei seiner Suche auf rein akustische Merkmale, wie„Szenen, die Gewehrschüsse, Explosionen etc.“ beinhalten, wird man ein passables Ergebnis erhalten (das Material im Archiv muss natürlich dementsprechend indiziert sein). Einteilung Audioretrieval1auto
2autoAudioretrieval kann man in 3 Hauptgruppen einteilen:
Features von Audiodateien zhan2001,35 gouj20011Features von Audiodateien
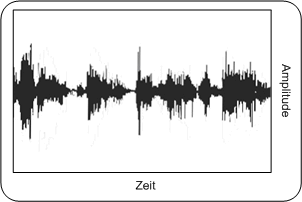
ZeitbereichAbbildung: Audiosignal im Zeitbereich PC
Abbildung: Audiosignal im Zeitbereich PDA_Phone
Features im Zeitbereich
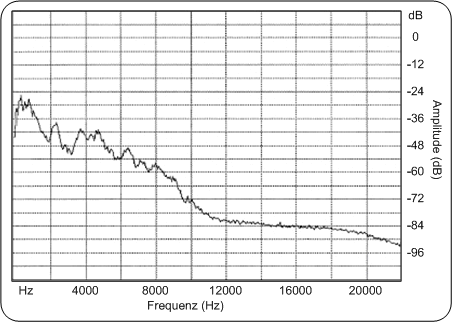
FrequenzbereichAbbildung: Audiosignal im Zeitbereich PC
Abbildung: Audiosignal im FrequenzbereichPDA_Phone
Features im Frequenzbereich
2Features von AudiodateienMan betrachte ein beliebiges Audiosignal unbekannten Inhaltes. Ziel ist es nun, einen Algorithmus zu entwickeln, der automatisch erkennen kann, welcher akustische Inhalt in diesem Audiosignal versteckt ist (Sprache, Musik, Geräusche). Zu diesem Zwecke werden aus dieser Audiodatei spezielle Features extrahiert, deren Werte eine Klassifizierung des Audiosignals ermöglichen sollen. Es sind eine Vielzahl solcher Features definiert, hier die Beschreibung einiger grundlegenden Features, die unter anderem benötigt werden, um eine grobe Unterscheidung zwischen Sprach- und Musiksignalen machen können. Das Signal wird dabei im Zeit-, wie auch im Frequenzbereich betrachtet. ZeitbereichIm Zeitbereich werden die Amplitudenwerte als Funktion der Zeit angezeigt. Die Abbildung zeigt exemplarisch die Darstellung eines speziellen Audiosignals in seinem Zeitbereich. Es gilt: Je größer der Amplitudenwert, um so höher die Lautstärke. Abbildung: Audiosignal im Zeitbereich PC
Abbildung: Audiosignal im Zeitbereich PDA_Phone
Features im ZeitbereichKurzzeitige durchschnittliche NullkreuzungsrateDie Null-Kreuzungsrate ist ein Indikator für die Häufigkeit, mit der die Amplitude des Audio-Signals ihr Vorzeichen wechselt. Im weiteren Sinne ist sie auch ein Indikator für die durchschnittliche Signal-Frequenz. Sie wird mittels nachfolgender Formel berechnet:
mit
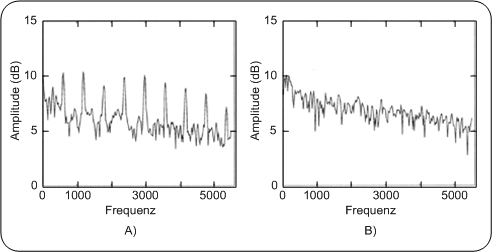
StilleverhältnisDieser Wert gibt darüber Aufschluss, wie viel Stille in einer Audiodatei enthalten ist. Schwierigkeiten bei diesem Feature macht die genaue Definition: „Was ist Stille?“ Der einfachste Ansatz ist zu sagen, überall dort, wo über einen bestimmten Zeitraum die Amplitudenwerte praktisch gleich Null sind, herrscht Stille. Aber bei vielen Audiosignalen gibt es Hintergrundgeräusche. Stille ist dann, wenn nur diese Hintergrundgeräusche hörbar sind. So muss für jede Audiodatei erst der notwendige Schwellwert festgelegt werden, um zwischen stillen und nicht stillen Audiopassagen unterscheiden zu können, was in der Praxis einen relativ hohen Rechenaufwand erfordert. Das Stilleverhältnis ist ein Indikator für den Anteil der Stille innerhalb einer Audio-Datei. Dieser Wert berechnet sich aus dem Quotienten von der Summe der stillen Perioden zu der Gesamtlänge der Audio-Datei. Beträgt dieser Wert 1, so beinhaltet diese Audiodatei nur Stille, ist der Wert 0, so gibt es keine einzige stille Passage in dieser Audiodatei. Frequenzbereich gouj2001Für diese Features wird das Audiosignal in seinem Frequenzbereich betrachtet. Die Abbildung zeigt exemplarisch den Frequenzbereich eines bestimmten Audiosignals. Man kann daraus ablesen, welche Frequenzkomponenten im Signal enthalten sind. Bei dem in der Abbildung dargestellten Audiosignal sind die Komponenten zwischen 500 Hz und 1000Hz am stärksten vertreten, ab 6000Hz werden die Werte der Komponenten immer geringer. Abbildung: Audiosignal im Frequenzbereich PC
Abbildung: Audiosignal im FrequenzbereichPDA_Phone
Features im FrequenzbereichBandbreiteViele Audiosignale haben nicht wie beí der obigen Abbildung über den gesamten Hörbereich (16-20000Hz) Frequenzkomponenten. Beim Sprechen zum Beispiel erzeugen wir höchstens Werte von 7000Hz. In diesem Fall sind alle Werte oberhalb 7000Hz im Frequenzspektrum gleich Null. Genauso haben viele Audiosignale ein nach unten begrenztes Frequenzspektrum. Unter einer gewissen Frequenz sind alle Frequenzkomponenten gleich Null. Um diesen Sachverhalt mit einem rechenbaren Feature zu charakterisieren, bedient man sich der Bandbreite. BandbreiteDie Bandbreite eines Audiosignals ist die Differenz der höchsten und der tiefsten Frequenz, die in dessen Frequenzspektrum vorkommen. BandbreiteTiefste Frequenz eines bestimmten Audiosignals ist 500Hz, höchste 6000 Hz, daraus errechnet sich eine Bandbreite von 5500Hz. Harmonität zhan2001, 39Klänge kann man ganz allgemein in zwei Kategorien einteilen:
Abbildung zur Harmonität PC
Die Abbildung zeigt ein harmonisches und ein nicht-harmonisches Frequenzspektrum.Abbildung (a): harmonisches Spektrum: Geigenklangton (b): nicht harmonisches Spektrum: Applaus zhan2001, 39 Abbildung zur Harmonität PDA_Phone
Die Abbildung zeigt ein harmonisches und ein nicht-harmonisches Frequenzspektrum.Abbildung (a): harmonisches Spektrum: Geigenklangton (b): nicht harmonisches Spektrum: Applaus zhan2001, 39 HarmonitätMusik beinhaltet gewöhnlich viele harmonische Anteile, Sprache ist eine Mixtur von harmonischen (Vokale) und nichtharmonischen (Konsonanten) Komponenten, die meisten Geräusche sind nicht harmonisch. Energieverteilung/HelligkeitAus dem Frequenzspektrum kann man leicht die Aufteilung der Gesamtenergie (ident mit der Gesamtlautstärke) auf die verschiedenen Frequenzkomponenten ablesen (Lautstärke der einzelnen Frequenzkomponenten). Ist der Hauptanteil der Energie eher auf die tieferen Frequenzen aufgeteilt, so handelt es sich um ein Audiosignal, das dumpf klingt. Liegt hingegen die Hauptenergie bei den höheren Frequenzen, handelt es sich um ein hell klingendes Audiosignal. Somit ist das Maß der Energieverteilung gleichzeitig ein Maß der Klanghelligkeit. Zur Beschreibung dieser Eigenschaft definiert man das Feature „spektraler Flächenschwerpunkt“. Energieverteilung/HelligkeitSprache hat im Allgemeinen einen niederen spektralen Flächenschwerpunkt als Musik. Segmentierung von Musik- und Sprachkomponenten zhan2001 gouj20011Unterschiedliche Merkmale bei Sprache und Musik gouj2001, 77
2autoEine beliebige Audiodatei kann aus einer Mixtur aus Musik, Sprache, Geräuschen etc bestehen. Hier werden nur Dateien betrachtet, die entweder Musik oder Sprache enthalten. Ziel der Segmentierung ist es nun, Musik-, Sprachkomponenten von einander zu trennen. Zu diesem Zweck wird die Audiodatei in kleine Zeitabschnitte unterteilt. Für jeden Abschnitt werden die relevanten Features (Siehe PUs ) berechnet. Die errechneten Features geben Auskunft, um welche Art von Audio es sich im entsprechenden Abschnitt handelt. Unterschiedliche Merkmale bei Sprache und Musik gouj2001, 77Im Folgenden eine Zusammenfassung von Merkmalen, die Musik und Sprache voneinander unterscheiden. Die richtige Bewertung dieser Merkmale bildet die Basis für eine zielführende Audio Klassifizierung.
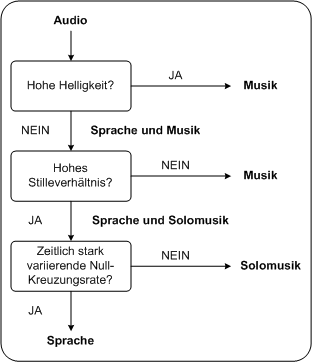
BandbreiteDie Bandbreite eines Sprachsignals ist im Vergleich zu einem Musiksignal im Allgemeinen geringer. Sie beträgt durchschnittlich 100 - 7000Hz, bei Musik 0-20kHz. HelligkeitEs dominieren in einem Sprachsignal vorwiegend tiefere Frequenzen, daher hat Sprache gegenüber Musik einen deutlich geringeren Wert für das Feature Helligkeit. StilleverhältnisIm gesprochenem Text sind zwischen den einzelnen Wörtern und Sätzen immer wieder Pausen. Im Vergleich dazu treten solche Pausen bei Musikaufnahmen weniger häufig auf. Ein hoher Wert für das Ruheverhältnis lässt somit auf eine Sprachaufnahme rückschließen. Ausnahme dabei sind Musiksignale, die eine Darbietung eines Soloinstrumentes bzw. eines Sängers ohne Musikbegleitung beinhalten. In diesen Fällen ist ihr Ruheverhältnis ähnlich dem eines Sprachsignals. Bei der Evaluierung des Merkmals „Ruheverhältnis“ werden musikalische Solodarbietungen mit einiger Wahrscheinlichkeit als Sprachsignal fehl interpretiert werden. Null-KreuzungsrateDie menschliche Sprache besteht aus einer Aneinanderreihung von Konsonanten und Vokale. Untersuchungen haben gezeigt, dass Konsonanten eine signifikant größere Null-Kreuzungsrate aufweisen als Vokale. Durch den schnellen Wechsel von Konsonanten und Vokale innerhalb des Sprachflusses entsteht ein Audiosignal, dessen Nullkreuzungsrate in zeitlich kurzen Abständen stark variiert. Diese starke Varianz ist bei Musiksignalen nicht zu beobachten. Ergo: Bei der Auswertung der Audiofeatures lässt eine starke Varianz der Null-Kreuzungsrate ein Sprachsignal vermuten. Methoden zur Klassifizierung Musik oder Sprache1Klassifizierung mit Hilfe der Step by Step Methode PC
Klassifizierung mit Hilfe der Step by Step Methode PDA_Phone
Klassifizierung mit Hilfe der Feature Vektoren
2Klassifizierung mit Hilfe der Step by Step Methode gouj2001Die Abbildung zeigt eine mögliches Verfahren, wie ein Audiosignal als Sprache/Musik klassifiziert werden kann. Was die Step by Step Methode auszeichnet, ist, dass sie sich sehr einfacher Algorithmen bedient und dementsprechend schnell arbeitet. Nachteil ist ihre mäßige Genauigkeit. Bei der Schritt-für-Schritt-Einteilungs-Methode werden die verschiedenen Audiofeatures sequentiell betrachtet. Jedes Feature ist somit eine Filterungs- bzw. Selektions-Kriterium. Wichtig dabei ist die Reihenfolge, in der die verschiedenen Features abgefragt werden. Abbildung: Klassifizierung mit Hilfe der Step by Step Methode PC
Abbildung:Klassifizierung mit Hilfe der Step by Step Methode PDA_Phone
Klassifizierung mit Hilfe der Feature VektorenGenauere Ergebnisse, aber einen dementsprechend höheren Rechenaufwand liefert die Klassifizierung mit Hilfe von Feature Vektoren. Diese Methode hat den Vorteil, dass weitaus mehr Features als bei der step-by-step Methode in die Berechnung mit einfließen können. Die verschiedenen Features einer Audiodatei werden zu einem Feature Vektor zusammengefasst. Durch Tests wird jeweils ein Referenzvektor für Audiosignale, die Sprache beinhalten, und ein Referenzvektor für Musik ermittelt. Will man nun eine Audiodatei, deren Inhalt unbekannt ist, klassifizieren, werden in einem ersten Schritt alle notwendigen Features berechnet und zu einem Featurevektor zusammengefasst. Dieser Vektor wird nun mit den beiden Referenzvektoren verglichen. Liegt er näher bei dem Referenzvektor für Sprache, wird das Audiosignal als Sprache klassifiziert, liegt er näher beim Referenzvektor für Musik, wird es als Musik klassifiziert. Zur Bestimmung der Quantität der Nähe wird gewöhnlich die euklidische Distanz der Vektoren hergenommen. |
| (empty) |