| Title: | Sprachinformationsretrieval | ||
|---|---|---|---|
| Abstract: | Konventionelle Informationsretrieval Systeme basieren ausschließlich auf Textsuche. Es besteht nun der Wunsch, auch gesprochenen Text, der zum Beispiel in Videos und Audiodateien gespeichert ist, für Informationsretrievalsysteme zugänglich zu machen. Diese Lerneinheit gibt einen Überblick über die verschiedenen Ansätze, Sprache automatisch in geschriebenen Text zu konvertieren. | ||
| Status: | final | Version: | 2004-09-23 |
| History: |
2004-09-23 (thomas Migl): Abb. explanation korrigiert |
||
| Author 1: | Thomas Migl | E-Mail: | migl@ims.tuwien.ac.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Organisation: Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Motivation Sprachinformationsretrieval foot1999, 31auto
2autoKonventionelle Informationsretrieval Systeme basieren ausschließlich auf Textsuche. Als Anfrage gibt der User ein oder mehrere Schlüsselwörter ein, Suchmaschinen wie Lycos und Altavista durchsuchen Textdokumente auf diese Wörter. Je mehr Schlüsselwörter in einem Dokument wieder gefunden werden, als desto passender zu einer Abfrage wird es gewertet. Es besteht nun der Wunsch, auch gesprochenen Text, der zum Beispiel in Videos und Audiodateien gespeichert ist, für Informationsretrievalsysteme zugänglich zu machen. Dazu muss erst Gesprochenes in geschriebenen Text umgewandelt werden. In dieser Form repräsentierte Sprachdateien können dann in einem Retrievalsystem wie konventionelle Schriftdokumente gehandhabt werden. Systeme, die Sprache in Schrift konvertieren, werden als Automatic Speech Recognition (ASR), also automatische Spracherkennung, bezeichnet. Probleme bei ASR gouj20011Spracheinheiten
Probleme bei der Segmentierung und Interpretation
2SpracheinheitenUm Sprache überhaupt verstehen zu können, muss sie erst in Spracheinheiten aufgeteilt werden. SpracheinheitenSpracheinheiten sind Grundbausteine jeder Sprache. So sind zum Beispiel Wörter und Sätze Spracheinheiten. Kleinere Einheiten sind die Laute (Selbstlaute, Mitlaute). Ein Phonem wiederum ist die kleinste bedeutungsunterscheidende Einheit einer Sprache. Probleme bei der Segmentierung und InterpretationDie Probleme der ASR ergeben sich bei der Segmentierung und Interpretation dieser Spracheinheiten
Prinzipielle Funktionsweise gouj2001,2801Die zwei Phasen eines ASR
Hidden Markov Model
Arten von ASR Systeme
2Die zwei Phasen eines ASRTrainingsphaseIn der Trainingsphase müssen mehrere Sprecher einem vom ASR System vorgegebenen Text lesen. Die Aufnahme der Sprachprobe wird in mehr oder weniger kleinere Einheiten zerlegt. Die kleinstmöglichen sprachlichen Einheiten sind dabei die Phoneme und Laute, aber es können auch größere Segmentierungseinheiten wie Wörter oder Sätze verwendet werden. Für jede sprachliche Einheit werden aus dessen Spektogramm verschiedene Features extrahiert und zu einem Featurevektor zusammengefasst. Da, wie vorher besprochen, gleicher Text niemals gleich ausgesprochen wird, müssen für ein und dieselbe Spracheinheit mehrer Merkmalsvektoren abgespeichert werden. Ziel der Trainingsphase ist es, den Spracheinheiten möglichst viele mögliche Ausspracheformen zuzuordnen. Nur so ist es möglich, dass dann in der Spracherkennungsphase auch die Sprache von unbekannten Personen verstanden werden kann. SpracherkennungsphaseWährend der Spracherkennung wird eine beliebige Rede in entsprechende Einheiten zerlegt und daraus Featurevektoren extrahiert. Jeder diese Featurevektoren wird mit den während der Trainingsphase generierten Vektoren verglichen. Jene Einheit, dessen Vektor dem Merkmalsvektor aus der Rede am ähnlichsten ist, wird als die gesuchte sprachliche Einheit erachtet. Hidden Markov Model foot1999,3Betrachtet man die grundlegenden Schwierigkeiten, mit denen jede ASR konfrontiert ist, lässt sich leicht ableiten, dass eine effektive Spracherkennung auf einem statistischen Prozess basieren muss. Klangsequenzen, die durch Segmentierung einer vorerst unbekannten Rede entstanden sind, können nur an Hand von Wahrscheinlichkeiten speziellen Phonemfolgen oder Wörtern zugeordnet werden. Die meisten ASR verwenden dazu das Hidden Markov Model. Ein HMM ist dabei eine statistische Repräsentation einer Spracheinheit. Es werden sowohl die in der Trainingsphase entstandenen wie die zuerkennenden Spracheinheiten jeweils in einem eigenem HMM kodiert. Mit Hilfe der HMM Darstellung können heutige Algorithmen zusammengehörige Klangsequenzen mit einer brauchbaren Genauigkeit erkennen. Arten von ASR SystemeJe nach Anforderung gibt es verschiedene Funktionsweisen von ASR.
Erkennung von Schlüsselwörter1auto
Switchboard
2autoNicht eine vollständige Transkription des sprachlichen Inhaltes einer Audiodatei ist hier das Ziel, sondern die Suche auf bestimmte Schlüsselwörter. Das Ergebnis soll zur effektiven Indizierung von Audiodateien dienen. SwitchboardUm die verschiedenen Systeme zur Schlüsselworterkennung zu evaluieren, wird sehr gerne der Datencorpus von Switchboard verwendet. Der Corpus von Switchboard beinhaltet Aufnahmen alltäglicher Telefongespräche. Jedes Telefonat hat ein bestimmtes Hauptthema: Haustiere, Wetter, etc.Die verschiedenen Forschergruppen versuchen nun, mit ihrem Schlüsselwortsystem das jeweilige Hauptthema eines dieser Telefonate zu erkennen. Sie erhalten somit ein Maß für die Qualität ihrer Algorithmen. Es wurden Algorithmen entwickelt, die von 10 Telefonaten 8 das richtige Hauptthema zuordneten. Large-Vocabulary Spracherkennung1auto
Phonetisches Wörterbuch
Statistisches Sprachmodell
Nachteile der Large Vocabulary ASR
2autoBei dieser Spracherkennungstechnik geht es darum, dass der vollständige Inhalt einer Rede in grammatikalisch richtige Schrift übertragen wird. Diese Systeme müssen ein alle Wörter einer Sprache umfassendes Wörterbuch enthalten inklusive deren verschiedenen Aussprachemöglichkeiten (in Form von HMMs). Ein solches Wörterbuch kann bis an die hunderttausend Wörter umfassen. Phonetisches WörterbuchFür jedes Wort aus dem Wörterbuch müsste man in der Trainingsphase ein eigenes HMM generieren. Um diesen immensen Aufwand zu umgehen, bedient man sich oft der Erstellung von HMMs, die jeweils kleinere sprachliche Einheiten als Wörter repräsentieren. Dadurch reduziert sich die Anzahl der erforderlichen HMMs von Hunderttausend auf einige Hunderte. Diese Wortteile können zum Beispiel Phoneme oder Laute sein. Phonetisches WörterbuchDas Wörterbuch eines ASR-Systems beinhaltet neben der richtigen Schreibweise auch die Lautschrift jedes Wortes (wie in den meisten Dictionaries üblich). Ein ASR für englische Sprache liefert dann zum Beispiel die Laut-Sequenz „R AY T“. Diese Lautfolge wird mit den Wörterbucheinträgen verglichen: Ergebnis ist das Wort „right“. Statistisches SprachmodellEin large-vocabulary ASR benötigt zusätzlich ein statistisches Sprachmodell. Darin wird beschrieben, wie hoch die Wahrscheinlichkeit bestimmter Wortfolgen in einer Sprache ist.Um ein brauchbares statistisches Sprachmodell aufbauen zu können, muss erst eine hohe Anzahl an Textbeispielen aus einem speziellen Gebiet, wie zum Beispiel Texte aus Sportnachrichten, analysiert werden. Dieses Sprachmodell ist dann allerdings nur für dieses spezielle Themengebiet relevant. So muss für jeden möglichen Themenbereich ein eigenes statistisches Sprachmodell ermittelt werden. Statistisches SprachmodellIm Englischen ist die Wortfolge „of the“ bedeutend wahrscheinlicher als „oaf the“ (oaf = Flegel). Nachteile der Large Vocabulary ASR
Für Anwendungen wie das Diktieren von Text, der sich eindeutig in ein Themengebiet einordnen lässt, sind diese Nachteile heute bereits ohne besondere Belange. Heutige Systeme können in diesen Fällen Sprache in guter Qualität in Echtzeit transkribieren. Sub-Word Indizierung1Sub-Word Indizierung
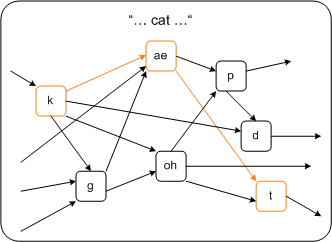
Phonetisches Gitter PC foot1999 Phonetisches Gitter PDA_Phone foot1999 2Sub-Word IndizierungBei Retrieval Anwendungen muss für eine große Anzahl an Audiodateien schnell eine für diverse Abfragen geeignete Repräsentation errechnet werden. In diesem Fall ist die benötigte Rechenzeit eines Large- Vocabulary ASR unakzeptabel. Zurzeit gibt es viele Forschungsprojekte, die eine Alternative zur Large Vocavulary ASR suchen. Eine Erfolg versprechende Alternative ist die Subword Indizierung. Zur Repräsentation einer Audiodatei wird sie nicht auf ganze Wörter, sondern auf kleinere sprachliche Einheiten (=Subwords) untersucht. So wird kein Wörterbuch und kein Sprachmodell benötigt. Die Repräsentation enthält keine Wörter, sondern Subword- Sequenzen. Welche Subwords die dafür am meist geeigneten sind, ist Gegenstand heutiger Forschung. Es wird die Effektivität von Phonemen, Lauten und phonetischen Cluster für die Indizierung untersucht. Phonetischer ClusterEin phonetischer Cluster ist eine spezielle Folge von Lauten. Gegenstand einer aktuellen Untersuchung einer Forschergruppe an der Schweizer ETH ist zum Beispiel der phonetische Cluster Selbstlaut-Mitlaut-Selbstlaut. Heutiger Stand der ForschungEine eindeutige Präferenz für einen der Subword Typen gibt es heute noch nicht. Große Schwierigkeiten haben diese Systeme bei der Genauigkeit. Durch das Fehlen eines Wörterbuches und einem sprachlichen Modells können die erkannten Subwords schwer zugeordnet werden. Weiters hat man bei den Forschungen herausgefunden, dass je kleiner die sprachliche Einheiten sind, umso ungenauer wird das System. Phonetische GitterIndizierung durch Subwords ist auf Grund des Fehlens eines Sprachmodells dementsprechend fehleranfällig. So muss eine Repräsentationsform der Subwords gefunden werden, die die durch das ASR verursachte Fehler kompensiert. Ein Bespiel dafür ist die Repräsentation der Subwords in einem Gitter. Das Prinzip baut darauf auf, dass, da kleinere Einheiten als Wörter gewählt werden, es nur wenige Möglichkeiten gibt fortzuschreiten, da nur bestimmte Laute und Silben zusammenpassen. Zur Repräsentation einer Audiodatei werden die Subwords in einer Gitterstruktur repräsentiert. Ein Gitter ist eine kompakte Repräsentation von “multiple best hypothesis“, Hypothesen, die von einem Laut- oder Wörtererkennungssystem generiert wurden. Mit Hilfe so eines Gitters kann in einem einstündigen Tondokument eine zu einer Abfrage gehörige spezielle Lautsequenz innerhalb von 3 Sekunden gefunden werden. Phonetisches Gitter PC foot1999 Die Abbildung zeit ein phonetisches Gitter .Das gesuchte Wort ist dabei das englische Wort "CAT". Phonetisches Gitter PDA_Phone foot1999 Die Abbildung zeit ein phonetisches Gitter .Das gesuchte Wort ist dabei das englische Wort "CAT". Beispiel für ein Sprachretrieval System eines Nachrichtensenders1Architektur eines Sprachinformationsretrievalsystem einer Nachrichtensendung PC makh2000
Architektur eines Sprachinformationsretrievalsystem einer Nachrichtensendung PDA_Phone makh2000
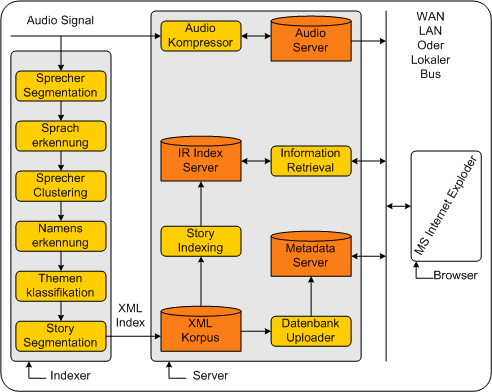
2Architektur eines Sprachinformationsretrievalsystem einer Nachrichtensendung PC makh2000
Erklärung der Abbildung Architektur eines Sprachinformationsretrievalsystem einer NachrichtensendungDie Grafik zeigt den Prinzipiellen Aufbaus eines Retrievalsystems für einen Nachrichtensender. Der User soll über seinen Internetbrowser zugriff auf die einzelnen Berichte als Tondokument, auf Stories in Textform, Informationen über den Sprecher etc haben
Architektur eines Sprachinformationsretrievalsystem einer Nachrichtensendung PDA_Phone makh2000
Erklärung der Abbildung Architektur eines Sprachinformationsretrievalsystem einer NachrichtensendungDie Grafik zeigt den Prinzipiellen Aufbaus eines Retrievalsystems für einen Nachrichtensender. Der User soll über seinen Internetbrowser zugriff auf die einzelnen Berichte als Tondokument, auf Stories in Textform, Informationen über den Sprecher etc haben
|
| (empty) |