| Title: | Video und Videoobjects Planes | ||
|---|---|---|---|
| Abstract: | Die Kodierung von Videos in MPEG-4 basiert auf Objekten. Die aufeinanderfolgenden Frames einer Bildsequenz werden zu Video Object Planes, also quasi Flächen, in denen die Videoobjekte eine begrenzte Zeit lang existieren. In dieser Lerneinheit wird die Kodierung der verschiedenen Arten von Videoobjekten genau erläutert und auch auf die dabei verwendeten Kompressionsverfahren eingegangen. | ||
| Status: | Final for Review #2 - 3 PDA Abb fehlen, captions and LOD3 missing; better tagging required | Version: | 2004-10-14 |
| History: | 2004-10-14
(Thomas migl): pda abbildungen hinzugefügt 2004-09-23 (thomas migl): abb. explanation korrigiert 2004-09-16 (Thomas Migl): pda Abb. hinzugefügt 2004-09-15 (Thomas Migl): Pda Abb. hinzugefügt; videoapplet mit quelle versehen 2004-09-10 (Thomas Migl): PC-Abb. komplementiert 2004-08-16 (Robert Fuchs): Checked, fixed and exported for Review #2. 2004-07-29 (Thomas Migl): ABGESCHLOSSEN: LOD1+2 ausgezeichnet links auf Videobeispiel (applet54402 +++ NOCH ZU MACHEN: Abb tw. Draft, eventuell genauere Blockauszeichnung, LOD3 Literatur +++ applet54402 |
||
| Author 1: | Eva Wohlfart | E-Mail: | evawohlfart@gmx.at |
|---|---|---|---|
| Author 2: | (empty) | E-Mail: | (empty) |
| Author 3: | (empty) | E-Mail: | (empty) |
| Author 4: | (empty) | E-Mail: | (empty) |
| Author 5: | (empty) | E-Mail: | (empty) |
| Organization: | Technische Universität Wien; Institut für Softwaretechnik und Interaktive Systeme; Arbeitsgruppe für Interaktive Multimediale Systeme; http://www.ims.tuwien.ac.at/ | ||
Einführung1auto
2autoDer größte Unterschied zwischen MPEG-2 und MPEG-4 ist der objektorientierte Ansatz, welcher im MPEG-4 Standard verfolgt wird. Wurden in MPEG-2 einfach Bildsequenzen kodiert, so basiert in MPEG-4 die Kodierung auf Objekten. Diese Videoobjekte können verschiedenster Art sein, neben der Kodierung von Texturen und Umrissen bietet MPEG-4 auch Möglichkeiten zur Animation von Gesichtern und Körpern und die Kodierung von Gitternetzmodellen, sogenannten Meshes, auf die dann Texturen aufgebracht werden können. Der Hintergrund einer Szene kann unabhängig von den Objekten im Vordergrund kodiert werden, ebenso ist es möglich, bewegte Objekte in beliebigen Formen zu kodieren. Diese Objekte können 2- oder 3-dimensional und durchsichtig oder undurchsichtig sein. Die Bewegung von Objekten wird mittels Vektoren beschrieben, zusätzlich dazu kann MPEG-4 das Ändern der Perspektive auf ein bewegtes Objekt mittels dem schon erwähnten Mesh coding darstellen. Auch stehende Bilder werden in MPEG-4 kodiert und dabei werden Methoden wie die Diskrete Cosinus-Transformation (DCT) oder Waveletkodierung verwendet. Visuelle Objekte1auto
Visuelle Objekte in MPEG-4 PC
Visuelle Objekte in MPEG-4 PDA_Phone
2autoDer MPEG-4 Standard bietet 4 Arten von visuellen Objektent. Videoobjekte sind beliebig geformte planare Pixelarrays, die das Aussehen oder die Textur eines Teils einer Szene beschreiben. Ein stehendes Videoobjekt ist ein planares Objekt das sich mit der Zeit nicht ändert. Ein Mesh-Objekt beschreibt eine zwei- oder dreidimensionale Form als ein Set von Punkten, dessen Form und Position sich ändern kann. Die Gesichts- und Körperanimation ist ein spezieller Teil von Mesh-Objekten, die menschliche Gesichter und Körper repräsentieren. Die Beschreibung von Mesh-Objekten und der Animation von Gesichtern und Körpern erfolgte bereits in der LU MPEG-4 Visual, im nächsten Kapitel werden nun Videoobjekte genauer beschrieben. Visuelle Objekte in MPEG-4 PC
Es gibt vier verschiedene Arten von visuellen Objekten in MPEG-4. Videoobjekte sind ein Bereich im Bild, der sich mit der Zeit ändern kann, im Gegensatz zu Texturobjekten, die sich mit der Zeit nicht ändern. Außerdem werden auch Mesh-Objekte, die aus Gitternetzen bestehen und auf die Texturen gemapt werden können, und Objekte zur Gesichts- und Körperanimation definiert. Visuelle Objekte in MPEG-4 PDA_Phone
Es gibt vier verschiedene Arten von visuellen Objekten in MPEG-4. Videoobjekte sind ein Bereich im Bild, der sich mit der Zeit ändern kann, im Gegensatz zu Texturobjekten, die sich mit der Zeit nicht ändern. Außerdem werden auch Mesh-Objekte, die aus Gitternetzen bestehen und auf die Texturen gemapt werden können, und Objekte zur Gesichts- und Körperanimation definiert. Video Objects und Video Object Planes1auto
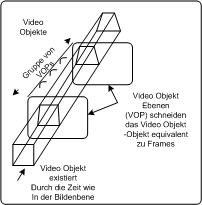
VOs, VOPs und GOVs PC watk2001-1
VOs, VOPs und GOVs PDA_Phone watk2001-1
Applet: Videoobjects applet54402
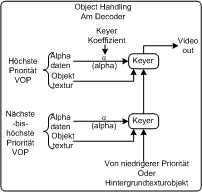
Abbildung: Keying von Objekten PC watk2001-1 Abbildung: Keying von Objekten PDA_Phone watk2001-1 Videoobjekte: Textur und Shape PC
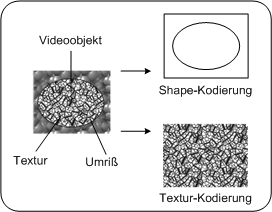
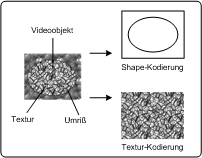
Videoobjekte: Textur und Shape PC
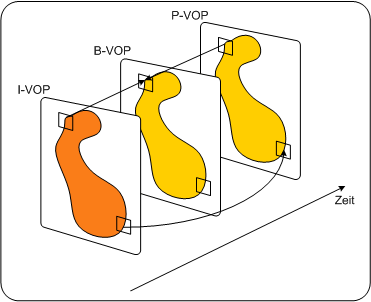
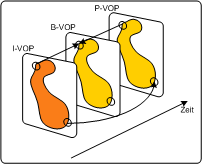
2autoVideoobjekteVideoobjekte sind Einheiten von Bild- oder Videoinhalten, die durch einen bestimmten Umriss (Shape) und eine Textur beschrieben werden. Diese beiden Eigenschaften werden getrennt kodiert. Ein Beispiel eines Videoobjekts ist etwa eine sprechende Person (ohne Hintergrund), die dann mit anderen Videoobjekten wie etwa einer Textur als Hintergrund kombiniert werden kann, um eine Szene zu kreieren. Konventionelle Videobilder, wie sie in MPEG-2 kodiert wurden, werden als Sonderfall solcher Objekte behandelt. Der Umriss von Objekten wird mittels Alphadaten übermittelt. Diese sind nichts anderes als eine Matrix, die beschreibt, ob ein bestimmtes Pixel zum Objekt gehört oder nicht. Hat ein Pixel den Wert 0, gehört es nicht zum Objekt, im gegenteiligen Fall schon. Video Object PlanesVideo Object Planes (VOPs) beschreiben das Aussehen eines Objekts zu einem bestimmten Zeitpunkt und korrespondieren zu Videoframes in MPEG-2. In jeder Plane kann sich Textur und Umriss eines Objekts ändern, dies wird durch eine Kombination von Intra- und Interkodierung beschrieben. Dadurch entstehen intra coded, predictive coded und bidirectional coded VOPs. Eine Gruppe von VOPs wird GOV genannt. VOs, VOPs und GOVs PC watk2001-1
Videoobjekte (VOs) sind Einheiten im Video, die Textur und Umriss haben. Video Object Planes (VOPs) sind zeitliche Abbilder eines VOs, da dieses das Aussehen ändern kann. Mehrere aufeinanderfolgende VOPs werden Group of VOPs (GOV) genannt. VOs, VOPs und GOVs PDA_Phone watk2001-1
Videoobjekte (VOs) sind Einheiten im Video, die Textur und Umriss haben. Video Object Planes (VOPs) sind zeitliche Abbilder eines VOs, da dieses das Aussehen ändern kann. Mehrere aufeinanderfolgende VOPs werden Group of VOPs (GOV) genannt. Applet: Videoobjects applet54402
Abbildung 3: Keying von Objekten PC watk2001-1 Mittels der Alphadaten der einzelnen Objekte wird ein key-Signal erzeugt. Die VOPs der Objekte werden dann in ein Bild zusammengefügt, wobei die VOP mit der höchsten Priorität am weitesten im Vordergrund ist. Abbildung: Keying von Objekten PDA_Phone watk2001-1 Mittels der Alphadaten der einzelnen Objekte wird ein key-Signal erzeugt. Die VOPs der Objekte werden dann in ein Bild zusammengefügt, wobei die VOP mit der höchsten Priorität am weitesten im Vordergrund ist. Videoobjekte: Textur und Shape PC
Videoobjekte sind eine Einheit im Video, die aus einer Textur und einer Shape besteht. Diese beiden Eigenschaften werden getrennt kodiert. Videoobjekte können ihre Eigenschaften mit der Zeit ändern, die zeitlichen „Schnappschüsse“ der Videoobjekte sind dann die VOPs Videoobjekte: Textur und Shape PDA_Phone
Videoobjekte sind eine Einheit im Video, die aus einer Textur und einer Shape besteht. Diese beiden Eigenschaften werden getrennt kodiert. Videoobjekte können ihre Eigenschaften mit der Zeit ändern, die zeitlichen „Schnappschüsse“ der Videoobjekte sind dann die VOPs Kodierung von Texturen1auto
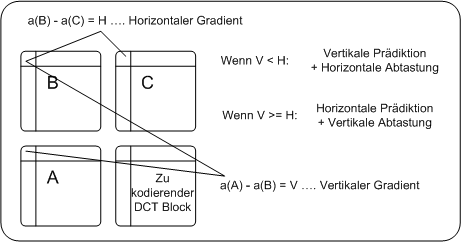
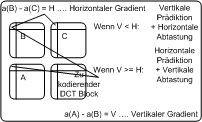
Gradientenbasierte Prädiktion von Koeffizienten PC watk2001-1 Gradientenbasierte Prädiktion von Koeffizienten PDA_Phone watk2001-1 2In MPEG-2 wird ein Bild durch Pixel beschrieben und dafür ist kein Name nötig. Da es in MPEG-4 aber verschiedene Objekttypen gibt, wird dieser Pixelrepräsentation ein Name gegeben:Texture Coding. Die Komprimierung von Texuren erfolgt mit bekannten Algorithmen, allerdings wurden einige Erweiterungen der Komlexität vorgenommen, um höhere Performance zu ermöglichen. Diese Erweiterungen bringen die Möglichkeit, die Bitrate zu vermindern, ohne dabei an Qualität zu verlieren. Bei der DCT-Kodierung von Texturen sucht MPEG-4 nach Redundanzen unter den Koeffizienten mittels Prädiktion (coefficient prediction). Dabei werden benachbarte Blöcke zur Prädiktion verwendet, der dafür geeignetste Block wird durch Bestimmung der horizontalen und vertikalen Änderung des DC-Koeffizienten bestimmt. Ist der vertikale Gradient kleiner, so wird vom oberen Block vorhergesagt und horizontal gescannt, im umgekehrten Fall wird vom linken Block vohergesagt und vertikal gescannt. Bei dieser Prädiktion müssen dann nur die Differenzen zwischen den Blöcken kodiert werden. Um auch die oberste und linke Reihe der Blöcke behandeln zu können, müssen einige Vereinbarungen getroffen werden, da hier das übliche Prädiktionsverfahren nicht verwendet werden kann. In diesen Fällen weisen sowohl Dekoder als auch Enkoder den fehlenden Prädiktionskoeffizienten standardisierte Konstanten zu. Gradientenbasierte Prädiktion von Koeffizienten PC watk2001-1 Bei der DCT-Kodierung werden Koeffizienten vorhergesagt. Für diese Prädiktion wird der geeignetste Block der drei benachbarten Blöcke herangezogen. Dieser wird durch Berechnung der horizontalen und vertikalen Gradienten bestimmt, was nichts anderes als die Differenzen der DC-Koeffizienten in horizontaler und vertikaler Richtung sind. Ist z.B. der Unterschied zwischen B und C geringer ist, wird A zur Prädiktion verwendet, da die Änderung in horizontaler Richtung kleiner ist. Gradientenbasierte Prädiktion von Koeffizienten PDA_Phone watk2001-1 Bei der DCT-Kodierung werden Koeffizienten vorhergesagt. Für diese Prädiktion wird der geeignetste Block der drei benachbarten Blöcke herangezogen. Dieser wird durch Berechnung der horizontalen und vertikalen Gradienten bestimmt, was nichts anderes als die Differenzen der DC-Koeffizienten in horizontaler und vertikaler Richtung sind. Ist z.B. der Unterschied zwischen B und C geringer ist, wird A zur Prädiktion verwendet, da die Änderung in horizontaler Richtung kleiner ist. Bewegungsschätzung- und kompensation1Idee
Darstellung der unterschiedlichen Videoobjekte PC repp2000
Darstellung der unterschiedlichen Videoobjekte PDA_Phone repp2000
Bild von http://graphics.cs.uni-sb.de/Courses/ws9900/cg-seminar/Ausarbeitung/Michael.Repplinger/ Techniken zur Bewegungsprädiktion (motion prediction)
2IdeeDie Idee auf der dieses Komprimierungsverfahren beruht ist die Tatsache, dass sich der Inhalt von direkt aufeinanderfolgenden Bildern nur wenig ändert. Dadurch wird es unnötig, aufeinanderfolgende Bilder separat und vollständig zu speichern. Bereits in MPEG-2 wurden Videobilder in Blöcke unterteilt und diese dann in Abhängigkeit von dem nachfolgenden oder vorhergehenden Block komprimiert (siehe auch Lerneinheit Bewegungskompensation). Dieses Verfahren wurde in MPEG-4 übernommen, mit dem Unterschied, dass nun nicht mehr Blöcke von ganzen Frames, sondern Blöcke von Videoobjekten komprimiert werden. Hierbei gibt es 3 Arten ein Objekt zu komprimieren:
DDarstellung der unterschiedlichen Videoobjekte PC repp2000
Es gibt drei Arten, ein Videoobjekt zu komprimieren: Intrakodierung, Prädiktionskodierung und bidirektional interpolierte Kodierung. Intra-VOs werden unabhängig von den anderen VOPs komprimiert. P-VOs werden in Abhängigkeit von der vorigen VOP komprimiert, und B-VOs verwenden zur Prädiktion die vorige und die nachfolgende VOP. Darstellung der unterschiedlichen Videoobjekte PDA_Phone repp2000
Es gibt drei Arten, ein Videoobjekt zu komprimieren: Intrakodierung, Prädiktionskodierung und bidirektional interpolierte Kodierung. Intra-VOs werden unabhängig von den anderen VOPs komprimiert. P-VOs werden in Abhängigkeit von der vorigen VOP komprimiert, und B-VOs verwenden zur Prädiktion die vorige und die nachfolgende VOP. Bild von http://graphics.cs.uni-sb.de/Courses/ws9900/cg-seminar/Ausarbeitung/Michael.Repplinger/ Techniken zur Bewegungsprädiktion (motion prediction)Ein wichtiger Vorteil der content-basierten Kodierung in MPEG-4 ist die Effizienz der Kompression. Diese kann für viele Videosequenzen erheblich erhöht werden, indem man objekt-basierte Prediction-Tools verwendet. Diese sind:
Kodierung von Shapes1auto
Kodierungsprinzip
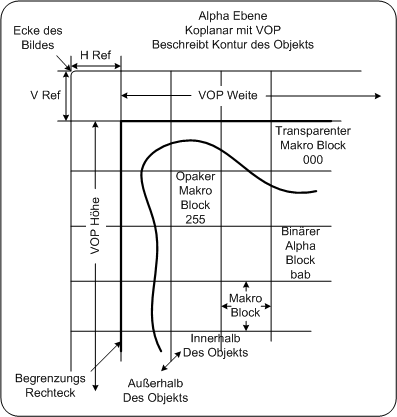
Makroblöcke im umgebenden Rechteck PC watk2001-1
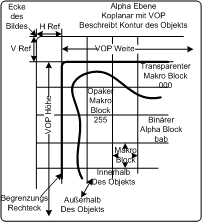
Makroblöcke im umgebenden Rechteck PDA_Phone watk2001-1
Binäre Alphamaps
Interkodierung von Shapes
Alpha Texture Maps
Alpha map PC yung2001
Bild von http://grail.cs.washington.edu/projects/digital-matting/image-matting/ Alpha map PDA_Phone yung2001
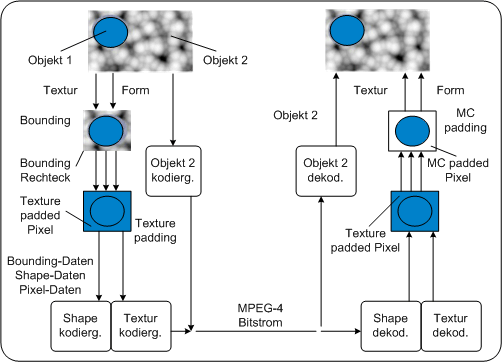
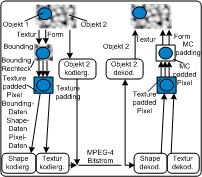
Bild von http://grail.cs.washington.edu/projects/digital-matting/image-matting/ 2autoMPEG-4 ist der erste Videostandard, der die Kodierung von Umrissen in einem Standard einbindet. Die Kodierung von Umrissen ist sowohl bei „konventionellem“ Video und Bildern wichtig, als auch bei den in MPEG-4 verwendeten Videoobjekten. Hierbei gibt es zwei Arten, dies zu tun: mit binären Alphamaps oder Alpha Texture Maps. Bei beiden Arten wird die Information über einen Umriss in einer Matrix dargestellt, die der Größe des Videoobjekts entspricht. Durch Senden eines konstanten Alphawertes für jede VOP kann ein Objekt auch gefadet werden. KodierungsprinzipVideoobjekte werden folgendermaßen dekodiert: Die Daten über den Umriss des Objekts (Alphadaten) werden übertragen. Diese werden dekodiert und erzeugen ein sogenanntes keying-Signal. Dabei können mehrere Objekte in ein Bild eingefügt werden. Jedes beliebig geformte Videoobjekt wird durch ein umgebendes Rechteck eingeschlossen, welches die Grenzen an Makroblöcken hat, der Umriss und die Textur werden am Decoder erzeugt. Innerhalb dieses Rechtecks befinden sich 3 Arten von Makroblöcken: Transparente Makroblöcke befinden sich außerhalb des Objekts, undurchsichtige Makroblöcke sind komplett innerhalb des Objekts und Grenzmakroblöcke sind Blöcke durch die Objektgrenzen hindurchgehen, sie enthalten alle Informationen über den Umriss und etwas weniger Texturinformationen als die undurchsichtigen Makroblöcke. Makroblöcke im umgebenden Rechteck PC watk2001-1
Videoobjekte werden durch umgebende Rechtecke eingeschlossen. Bei den Makroblöcken innerhalb dieser Rechtecke unterscheidet man 3 Arten: Undurchsichtige Makroblöcke, die außerhalb des Objekts liegen, transparente Makroblöcke, die innerhalb liegen, und Blöcke, die am Rand des Objekts liegen. Diese brauchen bei der Kodierung spezielle Behandlung Makroblöcke im umgebenden Rechteck PDA_Phone watk2001-1
Videoobjekte werden durch umgebende Rechtecke eingeschlossen. Bei den Makroblöcken innerhalb dieser Rechtecke unterscheidet man 3 Arten: Undurchsichtige Makroblöcke, die außerhalb des Objekts liegen, transparente Makroblöcke, die innerhalb liegen, und Blöcke, die am Rand des Objekts liegen. Diese brauchen bei der Kodierung spezielle Behandlung Binäre AlphamapsBinäre Maps definieren, ob ein Pixel zu dem jeweiligen Objekt dazugehört oder nicht. Dementsprechend kann ein Pixel einer solchen Map auch nur zwei Werte haben. Im Decoder werden diese Werte dann auf 0 oder 255 umgewandelt. Hat ein Pixel den Wert 255, so gehört es zum Objekt, andernfalls nicht. Die dabei entstehende Matrix wird auch als bitmap bezeichnet. Der Vorteil dieser einfachen Darstellung liegt darin, dass sie gut komprimiert werden kann und einen geringen Rechenaufwand benötigt. Zur Komprimierung wird die Map in Blöcke unterteilt (diese werden binary alpha blocks – bab- genannt) und dann mit dem sogenannten Context Coding Algorithmus komprimiert. Kodierung von binären AlphamapsBeim Context Coding wird im Prinzip die Grenze zwischen den Alpha-0 und den Alpha-1-Bereichen kodiert. Wenn diese erst einmal gefunden wurde, ist der Wert aller anderen Bits klar. Die babs werden in einen seriellen Bitstrom eingelesen. Die eigentliche Kodierung funktioniert so, dass von einem bereits eingelesenen Kontext aus 10 bits versucht wird, den Wert des aktuellen Bits vorauszusagen. Durch die 10 Kontextbits existieren insgesamt 210, also 1024 verschiedene Kontexte, für jeden von diesen ist in einem standardisierten Lookup-table die Wahrscheinlichkeit eingetragen, dass das jetzige Bit 0 ist. Der Encoder sagt mit Hilfe dieses Tables und einem Parameter, dem sogenannten arithmetic code value, das Bit voraus. Ist die Prädiktion nach einem Vergleich mit dem tatsächlichen Bit richtig, muss der arithmetic code value nicht geändert werden, und nichts wird übermittelt. Andernfalls wird der arithmetic code value so geändert, dass die Prädiktion stimmt und die Fehler bei der Prädiktion, welche die Grenze an denen Alpha-Änderungen auftreten repräsentieren, werden übermittelt. Interkodierung von ShapesDaten über Umrisse können auch interkodiert werden. Dabei wird der Kontext über zwei VOPs ausgedehnt, der Kodierungsprozess läuft aber gleich wie beim context coding ab. Falls der Umriss sich über den VOPs ändert, wird motion compensation verwendet. Dabei wird ein Shape Vektor übermittelt, mit dem der Kontext an eine andere Stelle verschoben wird. Dadurch werden die Chancen erhöht, das momentane Bit richtig vorherzusagen. Alpha Texture MapsAlpha Texture Maps definieren Objekte nicht in „schwarz-weiß“, sondern verwenden Graustufen. Die Werte in der Matrix können also zwischen 0 und 255 liegen. Diese Werte geben die Transparenz eines Objektes an, wobei 0 für absolute Transparenz steht und 255 für undurchsichtig. Die Transparenz kann über das ganze Objekt variieren, dies wird zum Beispiel dazu benutzt, den Rand eines Objekts transparenter zu machen oder auch um verschiedene Layers von Bildsequenzen aus- oder einzublenden. Bei der Komprimierung wird eine blockbasierte diskrete Kosinustransformation (DCT) verwendet, die der Komprimierung von Texturen sehr ähnlich ist. Alpha map PC yung2001
Alpha maps werden dazu verwendet, um anzugeben, ob ein Pixel einer Region zu einem bestimmten Objekt dazugehört oder nicht. Ist das Pixel schwarz, gehört es nicht dazu, andernfalls schon. Alpha maps können auch dazu verwendet werden, um Bilder langsam auszublenden (Fading). Dabei wird dann zu jedem Zeitpunkt ein bestimmter Wert für die Transparenz des Bildes übermittelt, der sich dann mit der Zeit verringert. Bild von http://grail.cs.washington.edu/projects/digital-matting/image-matting/ Alpha map PDA_Phone yung2001
Alpha maps werden dazu verwendet, um anzugeben, ob ein Pixel einer Region zu einem bestimmten Objekt dazugehört oder nicht. Ist das Pixel schwarz, gehört es nicht dazu, andernfalls schon. Alpha maps können auch dazu verwendet werden, um Bilder langsam auszublenden (Fading). Dabei wird dann zu jedem Zeitpunkt ein bestimmter Wert für die Transparenz des Bildes übermittelt, der sich dann mit der Zeit verringert. Bild von http://grail.cs.washington.edu/projects/digital-matting/image-matting/ Padding1auto
Texture padding
Texture padding PC
Texture padding PDA_Phone
Motion compensation padding
2autoDie Makroblöcke einer Form, die teilweise innerhalb und teilweise außerhalb liegen, brauchen spezifische Behandlung. Dafür wird Padding verwendet. Es gibt zwei Arten von Padding, welche unterschiedliche Funktionen erfüllen:
Texture paddingTexture padding erhöht die Effizienz der Kodierung der Makroblöcke am Rand. Da die Frequenzkoeffizienten der DCT sich auf den gesamten Block beziehen, können Pixel außerhalb des Objekts zu Koeffizienten führen, die nicht durch das Objekt entstehen. Daher werden bei diesem Verfahren die Pixel außerhalb des Objekts durch ausgewählte Pixel ersetzt, die die Menge an Koeffizientendaten minimieren. Dies ist im Endeffekt für das Aussehen des Objekts ohne Bedeutung, da die Pixel außerhalb des Objekts später durch die Informationen über den Umriss wegfallen. Texture padding PC
Beim Texture padding werden die Pixel innerhalb des umgebenden Rechtecks, die außerhalb des Objekts liegen, dermaßen interpoliert, dass Kompression besser möglich ist. Dabei werden die Pixel im Prinzip so ersetzt, als ob die Textur innerhalb des Objekts auch außerhalb weitergehen würde. Durch die Informationen, die man über die Form des Objekts hat, werden die Pixel später wieder rückersetzt. Texture padding PDA_Phone
Beim Texture padding werden die Pixel innerhalb des umgebenden Rechtecks, die außerhalb des Objekts liegen, dermaßen interpoliert, dass Kompression besser möglich ist. Dabei werden die Pixel im Prinzip so ersetzt, als ob die Textur innerhalb des Objekts auch außerhalb weitergehen würde. Durch die Informationen, die man über die Form des Objekts hat, werden die Pixel später wieder rückersetzt. Motion compensation paddingObjekte die sich bewegen ändern meist auch ihren Umriss. Zur Prädiktion von Textur und Umriss wird motion compensation verwendet. Treten in den Grenzpixeln eines Umrisses Fehler auf, kann es passieren, dass Hintergrundpixel in das Objekt „einfließen“ und es zu einem großen Prädiktionsfehler kommt. Dies verhindert MC padding, indem Pixel am Rand eines Objekts zu Pixeln außerhalb des Objekts kopiert werden sodass kleine Fehler in einem Umriss korrigiert werden. Kodierung von Videoobjekten1Kodierung von Videoobjekten PC watk2001-1
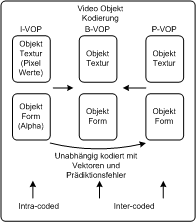
Kodierung von Videoobjekten PDA_Phone watk2001-1
KodierungsprozedereSegmentierung
Kodierung
Decoder
Kodieren von Videoobjekte koen2002 PC
Kodieren von Videoobjekte koen2002 PC
Bild nach http://www.chiariglione.org/mpeg/standards/mpeg-4/mpeg-4.htm
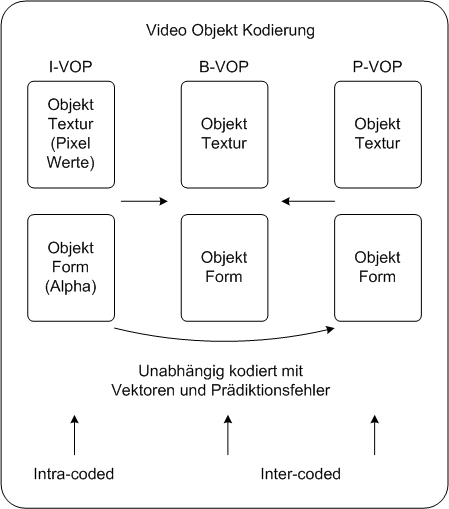
2Kodierung von Videoobjekten PC watk2001-1
Die Form und Textur von Videoobjekten wird grundsätzlich getrennt kodiert. VOPs, die vollständig kodiert werden, nennt man I-VOPs. P-VOPs werden in Abhängigkeit von der vorigen VOP kodiert, und B-VOPs (bidirectional interpolated VOPs) werden abhängig zur vorigen und zur nächsten VOP kodiert. Die Kodierung erfolgt dabei über die Differenzen von Bewegungsvektoren. Kodierung von Videoobjekten PDA_Phone watk2001-1
Die Form und Textur von Videoobjekten wird grundsätzlich getrennt kodiert. VOPs, die vollständig kodiert werden, nennt man I-VOPs. P-VOPs werden in Abhängigkeit von der vorigen VOP kodiert, und B-VOPs (bidirectional interpolated VOPs) werden abhängig zur vorigen und zur nächsten VOP kodiert. Die Kodierung erfolgt dabei über die Differenzen von Bewegungsvektoren. KodierungsprozedereSegmentierungZu Beginn des Kodierungsprozesses wird das Bild analysiert und in Objekte „aufgespalten“. Für jedes Objekt wird ein einzelnes Signal erzeugt. Die Daten über die Textur und den Umriss der Objekte werden dazu verwendet, um ein Rechteck um diese aufzuspannen. Außerdem werden Informationen über die Bewegung der Texturen und Umrisse gewonnen. Die Pixelwerte außerhalb der Objektgrenzen von Objekten im Vordergrund werden mittels texture padding ersetzt. Die Makroblöcke der Textur werden dann wie die Bilder in MPEG-2 mittels der DCT kodiert und die binary alpha blocks (babs), die die Informationen über den Umriss des Objekts beinhalten, werden kontextkodiert. Informationen über den Hintergrund werden ebenfalls kodiert und als ein weiteres Objekt in den Bitstrom durch Multiplexing eingefügt. KodierungIntra-VOPs werden örtlich kodiert (also ihre Position wird direkt erfasst), während bei P- und B-VOPs motion-compensated prediction eingesetzt wird, wobei dann eine Positionsänderung des Objekts übermittelt wird. Die Daten über den Umriss werden in I-VOPs kontextkodiert und bei B- und P-VOPs wird Bewegungskompensation angewendet. Die Bewegungsvektoren des Umrisses können von anderen Bewegungsvektoren des Umrisses oder von Bewegungsvektoren der Textur vorhergesagt werden. Dazu werden benachbarte Vektoren abgescannt und der erste Vektor der definiert ist, wird verwendet. DecoderAuf der Seite des Dekoders werden die Daten über den Umriss und die Textur der Objekte dekodiert und in sogenannten anchor VOPs werden die Daten über den Umriss dazu verwendet, um die „falschen“ Bits des texture padding zu ersetzen und MC padding zu verwenden. Schlussendlich werden die Objekte in den Hintergrund gesetzt, die Position ergibt sich aus den Umrissdaten. Kodieren von Videoobjekte koen2002 PC
Im Kodierungsvorgang von Videoobjekten wird zunächst ein umgebendes Rechteck um die Videoobjekte im Bild gezogen. Dann werden die Pixel, die außerhalb des Objektrands liegen, durch passende Pixel ersetzt, um bessere Kompression zu ermöglichen. Danach werden Form und Textur kodiert und schlussendlich alle Datenströme zusammengeführt. Auf der Seite des Decoders werden diese wieder aufgespalten und Form und Textur dekodiert. Die Pixel außerhalb der Objekte werden mit MC padding wieder zurückersetzt und das Bild wird zusammengesetzt. Kodieren von Videoobjekte koen2002 PC
Im Kodierungsvorgang von Videoobjekten wird zunächst ein umgebendes Rechteck um die Videoobjekte im Bild gezogen. Dann werden die Pixel, die außerhalb des Objektrands liegen, durch passende Pixel ersetzt, um bessere Kompression zu ermöglichen. Danach werden Form und Textur kodiert und schlussendlich alle Datenströme zusammengeführt. Auf der Seite des Decoders werden diese wieder aufgespalten und Form und Textur dekodiert. Die Pixel außerhalb der Objekte werden mit MC padding wieder zurückersetzt und das Bild wird zusammengesetzt. Bild nach http://www.chiariglione.org/mpeg/standards/mpeg-4/mpeg-4.htm Sprite Coding1Sprites
Vorteil
Low Latency Sprite Coding
Sprite coding PC koen2002
Sprite coding PC koen2002
Bild von http://www.chiariglione.org/mpeg/standards/mpeg-4/mpeg-4.htm
2SpritesSprites sind ein Bild oder ein Teil eines Bildes das sich nicht mit der Zeit ändert. Dadurch können solche Flächen natürlich sehr gut komprimiert werden. Dabei wird ein statischer Hintergrund als eine Panoramaaufnahme einmal übertragen und auf Decoderseite in einem Sprite Buffer gespeichert. Allerdings ist danach nur der übermittelte Sprite der Teil, der sich nicht ändert. Der Decoder kann den Sprite durchaus manipulieren, um die Illusion von Veränderung zu geben. Die Videoobjekte im Vordergrund werden wie gewöhnlich separat überragen. Auf der Seite des Decoders werden diese Teile dann zusammengesetzt. VorteilSprites müssen nur einmal übertragen und somit nur einmal kodiert werden. Das reduziert dieGesamtdatenrate. Der übermittelte Sprite kann als I-VOP übertragen werden, dessen Größe die Größe des Bildes übersteigt. Ist die Textur einmal im Decoder verfügbar, können Vektoren zur Bewegung und Manipulation des Bildes gesendet werden. Solche Anweisungen nennt man S-VOPs (static VOPs). Mit Hilfe von S-VOP Vektoren kann ein unterschiedlicher Teil des Sprites zur Anzeige gebracht werden, so wird die Illusion eines sich bewegenden Hintergrunds geschaffen. Low Latency Sprite CodingEin Problem, welches beim Übermitteln eines großen Sprites als eine I-VOP auftritt, ist die große Datenmenge, die auf einmal übertragen werden muss. Die Lösung dafür nennt man low latency Sprite coding. Dabei wird nicht der ganze Sprite auf einmal übertragen, sondern aufgeteilt. Der erste Teil der übertragen wird ist das object piece, weitere Teile, die den Sprite vergrößern nennt man update pieces. Update pieces können unerschiedliche Gestalt haben: Sie können den Sprite einfach räumlich vergrößern, aber es gibt auch update pieces die einen bestimmten Ausschnitt des momentanen Sprites mit besserer Auflösung zeigen. Damit wird dann ein Zoom in das Bild möglich. Sprite coding PC koen2002
Beim Sprite coding wird eine Panoramaaufnahme des Hintergrunds auf einmal übertragen. Die danach gesendeten Daten betreffen dann nur mehr die Informationen über Änderungen der Perspektive des Betrachters auf den Sprite. Ebenso ist es möglich, sogenannte update pieces zu senden, mit denen etwa ein Teil des Sprites in besserer Auflösung übermittelt wird, damit ein Zoom in das Bild gemacht werden kann. Sprite coding PC koen2002
Beim Sprite coding wird eine Panoramaaufnahme des Hintergrunds auf einmal übertragen. Die danach gesendeten Daten betreffen dann nur mehr die Informationen über Änderungen der Perspektive des Betrachters auf den Sprite. Ebenso ist es möglich, sogenannte update pieces zu senden, mit denen etwa ein Teil des Sprites in besserer Auflösung übermittelt wird, damit ein Zoom in das Bild gemacht werden kann. Bild von http://www.chiariglione.org/mpeg/standards/mpeg-4/mpeg-4.htm |










| (empty) |