Client Session Scheduling
1
Auto
- Logischer Kanal
- Ressourcen werden für fortlaufende Übertragung benötigt, z.B.
Platten, Buffer, CPU352,
Netzwerk, Bildschirm
- Pipelining
- Der logische Kanal bildet eine Pipeline, z.B.
Block(i) wird angezeigt; Block(i+1) ist im Bildschirm gebuffert;
Block(i+2) ist im Netzwerk; Block(i+3) in einem Netzwerk Buffer
...
- Totale Übertragungsverzögerung < Zeit der Anzeige
- Es genügt, dass keine Komponente der Pipeline aushungert
- Verzögerung(j) ≤ Verzögerung(j+1) muss garantiert werden
(Buffer können helfen)
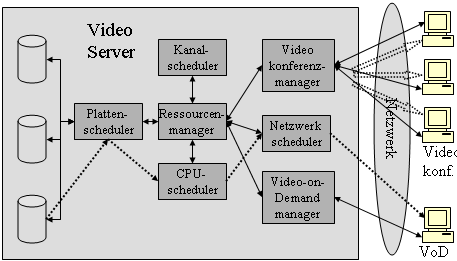
Logische Kanäle in einer Video Server Architektur
Auto PC
Auto PDA_Phone
Logischer Kanal Setup
- Auswahl der Komponenten
- Optimierung
- Charakteristia der Komponenten - z.B. vermeide langsames Switching
- Server-Topologie - z.B. berücksichtige nur verbundene Knoten
- Pfadbasierte Auswahl der Komponenten
- Reservierung von Ressourcen
- Reserviere genug Ressourcen auf dem gewählten Pfad
- Wähle die billigste Ressourcenkombination (Kostenfunktion)
- Bei VoD432
Systemen oftmals nur Reservierung aller Ressoursen auf dem Pfad
möglich
QoS Parameter im Client Session Scheduling
- Spitzenbandbreiten-Anforderung
- Notwendig für Applikationen mit variabler Bandbreite
- Maximale Dauer des Spitzenwertes
- Ausbruchsgröße (work ahead): max. Überschreitung des Durchschnitts
- Verzögerung
- Wichtig in Videokonferenzen, geringere Wichtigkeit bei VoD432
- Verlustwahrscheinlichkeit
- Streng für Kontrolle, lockerer für Multimedia Daten
QoS Spezifikation
- Explizite QoS72
Spezifikation
- Applikation trägt die Entscheidungslast
- Bietet größere Flexibilität, Applikationen können sich selbst
an die verfügbare Bandbreite anpassen
- Z.B. kleineres Fenster, nur Key Frames etc.
- Implizite QoS Spezifikation
- Vom Server spezifiziert
- Spezielle Attribute und Dateien können am Server gespeichert
sein
- QoS72
Attribute wie benötigte Bandbreite
Kapazitätsabschätzung
- Statische Tabelle mit den Bandbreite-Werten der Hersteller - grobe
Abschätzung
- Kalibrierung - am besten offline
- Input: Aktuelle Konfiguration als Komponentengraph
- Sammeln der Komponenten, deren Kapazitäten nicht unterschieden
werden kann (z.B. N Platten sind zusammengeschalten)
- Abspielen von MM Streams die Sättigung verursachen (maximaler
Durchsatz ohne QoS72
Anforderungen zu verletzen)
- Output: Tabelle mit den Kapazitätswerten der Komponenten
2
Einleitung
Beim Client Session Scheduling wird jedem Benutzer pro Session ein
logischer Kanal zugewiesen.
Ein solcher setzt sich aus einer Verbindung mehrerer Komponenten zusammen,
das sind z.B. Platten, Buffer, CPU352,
Netzwerk, etc.
Durch die Verbindung dieser einzelnen Komponenten wird eine Pipeline
gebildet, die alle ankommenden Datenpakete dieses Benutzers durchlaufen.
Der erste Block wird zum Beispiel gerade am Bildschirm angezeigt,
während Block zwei sich in einem Buffer befindet und die darauffolgenden
Blöcke noch übers Netzwerk übertragen werden.
Beim Pipelining sollte die totale Übertragungsverzögerung geringer
als die Zeit der Anzeige sein. Das ist allerdings keine notwendige
Bedingung, es ist ausreichend, dass keine Komponente der Pipeline
aushungert. Daraus kann man die Bedingung ableiten, dass die Verzögerung
des n-ten Blocks nicht größer als die des darauffolgenden Blocks sein
darf. Um diese Bedingung garantieren zu können kann die Verwendung
von Buffern sehr hilfreich sein.
Logische Kanäle in einer Video-Server Architektur
Auto PC
Auto PDA_Phone
Auto
Die folgende Abbildung zeigt eine mögliche Video-Server Architektur
mit ihren logischen Kanälen. In dieser repräsentieren die durchgehenden
Linien den Kontrollfluss und die unterbrochenen Linien den Datenfluss.
Der Videoserver in der Abbildung besteht aus einem Ressourcenmanager,
Platten-, Kanal-, CPU352-
und Netzwerkschedulern und einem Videokonferenz- sowie einem Video-on-Demand-Manager.
Der Videoserver wird vom Ressourcenmanager als durch logische Kanäle
verbundene Komponenten repräsentiert. Dieser hat die Aufgabe, alle
Komponenten zu koordinieren um die reibungslose Abarbeitung der Anfragen
zu ermöglichen. Er weist den Plattenscheduler an, welcher die I/O
Zugriffe der einzelnen Anfragen plant. Kanal-, CPU352-
und Netzwerkscheduler haben die Aufgabe, die von ihnen verwalteten
Ressourcen so zu vergeben, dass die Übertragung der angefragten Daten
möglichst problemlos verläuft. Dem Videokonferenz- und dem Video-on-Demand-Manager
fällt die Aufgabe zu, diese beiden speziellen Arten der Videoübertragung,
welche in dieser LU noch ausführlich erklärt werden, zu organisieren.
Logischer Kanal Setup
Der Medienserver wird vom Ressourcenmanager als eine verbundene Menge
von logischen Komponenten dargestellt. Um einen logischen Kanal für
eine Anforderung aufzubauen, müssen die logischen Komponenten ausgewählt
und anschließend die Ressourcen dieser Komponenten reserviert werden.
Das Auswählen der Komponenten um eine Anforderung zu bearbeiten ist
nicht trivial. Folgende Kriterien werden für die Wahl herangezogen:
- Optimierung
- z.B. Load Balancing (Lastverteilung bei Servern)
- Charakteristika der Komponenten
- z.B. vermeide langsames Switching zwischen Komponenten
- Server Topologie
- Die Auswahl der Komponenten kann auf der Verbindung der Komponenten
basieren, z.B. berücksichtige nur verbundene Knoten
- Pfadbasierte Auswahl der Komponenten
- z.B. wähle den Pfad mit den wenigsten Ressourcen-Engpässen
Selbst nach der Anwendung mehrerer Kriterien kann es verschiedene
mögliche Wege geben, die sich aus unterschiedlichen Komponenten zusammensetzen.
Für die endgültige Auswahl des Kanals gibt es wiederum verschiedene
Strategien, z.B. denjenigen mit der höchsten Zuverlässigkeit.
Nach der endgültigen Wahl des Pfades werden die Ressourcen der benötigten
Komponenten reserviert, wobei die billigste Ressourcenkombination
zu wählen ist. Diese wird mittels einer Kostenfunktion ermittelt.
Für die Kostenfunktion wird jedem Knoten ein statischer Kostenfaktor
zugewiesen, der z.B. dessen Bearbeitungszeit repräsentiert. Bei VoD-Systemen
besteht oftmals nur die Möglichkeit der totalen Reservierung der Ressourcen
auf dem Pfad.
QoS Parameter im Client-Session-Scheduling
Wichtige Quality of Service Parameter beim Client-Session-Scheduling
sind die Spitzenbandbreite, die Verzögerung
und die Verlustwahrscheinlichkeit.
Spitzenbandbreiten-Anforderungen sind notwendig für Anwendungen mit
variabler Bandbreite. Wichtig sind hierbei zum einen die maximale
Dauer des Spitzenwertes der Bandbreite und zum anderen die Ausbruchsgröße
(work ahead), das ist z.B. die maximale Menge an Daten um die der
Stream die Durchschnittsübertragung überschreiten kann.
Die erlaubte Verzögerung stellt einen
weiteren wichtigen Parameter dar, welche vor allem bei Videokonferenzen
an Bedeutung gewinnt, wohingegen sie bei Video-on-Demand an Wichtigkeit
verliert.
Die maximale tolerierbare Verlustwahrscheinlichkeit
ist auch eine wichtige Messgröße des QoS, wobei diese für Anforderungen
für Kontrollinformationen größer als für Multimedia-Daten ist. Das
liegt daran, dass es bei Verlust von bestimmten Kontrollinformationen
(z.B. Synchronisierungs-Informationen zwischen mehreren Tracks) nicht
mehr möglich ist, die Medien-Daten abzuspielen. Bei Verlust von Multimedia-Daten
hingegen kommt es höchstens zu Verzögerungen oder Ruckeln.
QoS Spezifikation
QoS Anforderungen können entweder durch die Anwendung explizit
spezifiziert werden (z.B. bei Videokonferenzen) oder implizit
vom Server spezifiziert werden (z.B. bei Video-on-Demand).
- Bei der expliziten Spezifikation
wird, wie schon erwähnt, die Entscheidungslast von der Anwendung
getragen. Sie bietet größere Flexibilität, da die Applikationen
sich selbst an die verfügbare Bandbreite anpassen können. Ein Überschreiben
der Spezifikation ist erlaubt, was sehr nützlich für die dynamische
Anpassung von QoS-Anforderungen ist.
- Bei der impliziten Spezifikation
übernimmt der Server die Aufgabe der QoS Spezifikation. Er erhält
z.B. die Ausgangsbandbreite auf Grund von Abschätzungen des Netzverkehrs.
Diese Spezifikation wird in einer assoziierten Metadatei oder in
einem spezifischen Teil der Medien-Datei gespeichert.
Kapazitätsabschätzung
Die Kapazität kann entweder mithilfe einer statischen Tabelle mit
den Bandbreitenwerte der Hersteller, die der Ressourcenmanager beinhaltet,
abgeschätzt werden oder durch Server-Kalibrierung. Klarerweise können
statische Annahmen in einem Mehrbenutzerbetrieb nur eine grobe Einschätzung
liefern und nur bei Fehlen von dynamischen Daten genutzt werden. Eine
bessere Abschätzung der Kapazität erhält man durch Kalibrierung der
statischen Werte. Hierbei werden dem Kalibrierungsprozess als Input
die Konfiguration des Videoservers als Komponentengraph und ein Vergleichspunkt
übergeben, der den Server unterstützen kann ohne die QoS-Anforderungen
zu verletzen.
Der Kalibrierungsprozess kann Probleme haben, zwischen den Kapazitäten
von gewissen individuellen Komponenten zu unterscheiden (z.B. n Platten
sind zusammengeschalten). Solche Komponenten können dann in logische
Komponenten zusammengefasst werden.
Um die Kapazität der logischen Komponenten zu messen, werden systematisch
Datenströme in ausgewählten Paaren abgespielt und die Datenrate wird
ausgehend von den statischen Kapazitäten kontrolliert. Dieses geschieht
durch die Abschätzung der Bandbreitenkapazität von jedem logischen
Knoten durch dessen Sättigung. Hierbei werden zuerst die Pfade, die
durch diesen Knoten führen, nach deren Gewichtung sortiert. Dann wird
der Pfad mit der größten Gewichtung ausgewählt und mit einem maximalen
Multimedia-Strom angesteuert. Es folgen die Pfade mit kleinerem Gewicht.
Output des Kalibrierungsprozesses ist schlussendlich eine Tabelle
mit den Kapazitätswerten der einzelnen Komponenten.
Client Request Scheduling
1
Auto
- Kanalzuweisung für jede Anfrage
- Zu teuer für viele Anfragen nach kurzen Clips
- Kanalzuweisung für Sessions
- Mögliche Ressourcenverschwendung
Benutzerabsage
- Absage ist wahrscheinlich, wenn Wartezeit zu lang
- T_ren: Zeitraum, den ein Benutzer bereit ist zu warten
- T_ren ist in den meisten Fällen unbekannt
- Minimale Absagezeit
- Es wird angenommen, dass Benutzer bereit sind wenigstens Tren,min
zu warten
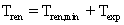 (
( :
Konstante, :
Konstante, 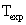 :
hat Exponentialverteilung) :
hat Exponentialverteilung)
- Überaschenderweise greift das Zipf'sche Gesetz als Verteilung
der Popularität in vielen Anwendungsszenarios
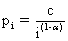 α :Parameter, c: Normalisierungskonstante
α :Parameter, c: Normalisierungskonstante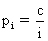 ( α =0: c,0.5c,0.3c,0.25c,0.2c,0.16c, ... 0.05c)
( α =0: c,0.5c,0.3c,0.25c,0.2c,0.16c, ... 0.05c)
Broadcasting vs. Media-on-Demand (MoD)
- Live Broadcasting
- Medien von Live-Kamera, Mikrophon zum Server
- Dauer muss im Vorhinein nicht unbedingt bekannt sein
- Benötigt große Bandbreite: Benutzer schalten ca. gleichzeitig
zu
- Media-on-Demand (MoD440)
- Agiert als Sammlung von VCR's
- Dauer ist im Vorhinein bekannt
- Vielleicht Unicast: leicht zu implementieren, große Bandbreite
- IP-Multicasting kann die Bandbreitenanforderung reduzieren
- Startup Verzögerung und VCR-Kontrolle können schwierig sein
Arten von Media on Demand
- True Media-on-Demand (TMoD441)
- Irgendein Medienstream, zu irgendeiner Zeit, mit irgendeiner
Art von VCR-Kontrolle
- Near Media-on-Demand (NMoD442)
- 1 der 3 obigen Bedingungen ist nicht gegeben (2 und 3)
- Quasi Media-on-Demand (QMoD443)
- Ein Stream wird übertragen, wenn mind. k Anfragen verfügbar
sind
- Client-pull
- Volle interaktive Kontrolle durch Benutzer (z.B. TMoD441)
- Server-push
- Nicht interaktiver periodischer Broadcast
(NMoD442
u.U. beides, push und pull)
VCR-Kontrolloperationen
- VCR Pause/Resume, interaktive Video Applikationen
- Behält die Ressourcen zwischen fortlaufenden Clips - verschwenderisch
- Kanalstrategie für unvorhergesehenen Fall
- Ein Pool (Kontingent) nur für Aktionen wie Wiederaufnahme
- Für andere Anfragen wird Platz von freiem Pool reserviert
- VCR Fast-Forward, Fast-Backward
- Spezielle Dateien (z.B. jedes 10. Frame) - verschwendet Speicherplatz,
starr
- Fast playback beim Benutzer - verschwendet Netzwerkbandbreite
Multicast Techniken
- Batching
- Anfragen für den selben Stream innerhalb einer Periode p werden
gemeinsam in einem Batch gruppiert
- Startup-Verzögerung ≤ p
- Der Kanal ist die ganze Zeit beschäftigt
- Die Anzahl der zeitgleichen Batches ist limitiert
- Frühe Anfragen in einem Batch müssen auf die Nachzügler warten
- Chaining
- Stream fließt durch eine Kette von Benutzerstationen
- Jede Benutzerstation speichert die Daten in einem lokalen
Cache
- Dynamisches Batching
- Anfragen werden bedient, wenn ein Strom verfügbar ist
- zwei Auswahlstrategien:
- First-Come-First-Served
- maximale Queuelänge
- Piggybacking
- keine Verwendung von Batching-Fenstern nötig
- Ströme mit dem selben Inhalt werden während der Übertragung
vereint
- Patching
- Entlastung für Server
- Multicastübertragung
- Bei Anforderung desselben Films innerhalb eines Zeitintervalls
nimmt der Benutzer an diesem Videostrom teil
- zusätzlich ein Patching-Strom
- Verwendung von Buffern notwendig
2
Auto
Prinzipiell kann das Client Request Scheduling auf 2 Arten durchgeführt
werden: Kanalzuweisung für jede Anfrage
oder Kanalzuweisung für Sessions. Beide
zur Verfügung stehenden Varianten bringen sowohl Vor- als auch Nachteile
mit sich.
Weist man jeder eingehenden Anfrage einen
eigenen logischen Kanal zu, so bringt das unnötig viel Aufwand
mit sich, wenn die Anfragen vor allem kurze Videos betreffen. Dieser
Ansatz wird auch datenzentriertes Scheduling genannt, da die verfügbare
Netzwerkbandbreite hier unter einzelnen Objekten (angefragte Videos)
aufgeteilt wird.
Wird hingegen dem Benutzer für jede Sitzung
ein Kanal zugewiesen, so bleiben die Ressourcen in den Zeitintervallen
zwischen den einzelnen Zugriffen ungenutzt. Beim sogenannten benutzerzentrierten
Scheduling wird die verfügbare Netzwerkbandbreite unter vielen Benutzern
verteilt.
Benutzerabsage
Wenn ein Benutzer zu lange auf die Beantwortung seiner Anfrage durch
den Server warten muss, ist es wahrscheinlich, dass er seine Anfrage
abbricht (client reneging). Der Zeitraum, den ein Benutzer bereit
ist auf die Ausführung seiner Anfrage zu warten, wird als 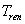 bezeichnet, wobei
nicht vorhersagbar ist, da nicht alle Benutzer bereit sind, gleich
lang zu warten. Es kann allerdings ein
bezeichnet, wobei
nicht vorhersagbar ist, da nicht alle Benutzer bereit sind, gleich
lang zu warten. Es kann allerdings ein  definiert werden, von dem angenommen wird, dass alle Benutzer bereit
sind, wenigstens so lange auf Bearbeitung ihrer Anfrage zu warten.
Die Gesamtwartezeit
setzt sich dann aus dem eben erwähnten
und
definiert werden, von dem angenommen wird, dass alle Benutzer bereit
sind, wenigstens so lange auf Bearbeitung ihrer Anfrage zu warten.
Die Gesamtwartezeit
setzt sich dann aus dem eben erwähnten
und 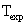 zusammen.
wird als eine exponentialverteilte Zufallsvariable dargestellt. Um
die Absagewahrscheinlichkeit der Benutzer möglichst gering zu halten
werden populäre Videos gesondert behandelt. Da ein großer Teil der
Anfragen sich genau auf diese Videos bezieht ist es sinnvoll, schon
im vorhinein Kapazität für diese zu belegen. Werden diese Videos in
Zeitintervallen von jeweils
ausgestrahlt, so kann dem Benutzer eine tolerierbare Wartezeit garantiert
werden.
zusammen.
wird als eine exponentialverteilte Zufallsvariable dargestellt. Um
die Absagewahrscheinlichkeit der Benutzer möglichst gering zu halten
werden populäre Videos gesondert behandelt. Da ein großer Teil der
Anfragen sich genau auf diese Videos bezieht ist es sinnvoll, schon
im vorhinein Kapazität für diese zu belegen. Werden diese Videos in
Zeitintervallen von jeweils
ausgestrahlt, so kann dem Benutzer eine tolerierbare Wartezeit garantiert
werden.
Grundsätzlich kann die Absagewahrscheinlichkeit von den gewählten
Kanalverwaltungs- und Kanalalloziierungsstrategien beeinflusst werden.
Es stellt sich nun die Frage, wie man die Popularität der Videos
messen und repräsentieren kann.
Überraschenderweise ist die Zipf-Verteilung eine sehr gute Annäherung
für die Popularitätsverteilung von Videos. Wenn die einzelnen Videos
nach ihrer Popularität gereiht werden, so entspricht die Wahrscheinlichkeit,
dass die nächste Anfrage den k-ten Video betrifft c/k, wobei c eine
Normalisierungskonstante darstellt. Wenn der Server n Videos speichert,
so muss c/1 + c/2 + c/3 +...+ c/n = 1 ergeben. Anhand dieser Gleichung
wird nun c berechnet. Gibt es zum Beispiel fünf Videos so ist c =
0,437. Die Wahrscheinlichkeit, dass der nächste Benutzer das drittbeliebteste
Video anfordert beträgt c/3 = 0,437/3 = 0,1456.
Broadcasting vs. Media-on-Demand (MoD)
Die Art und Weise wie ein Multimedien übertragen werden, hat einen
Einfluß auf das Client Request Scheduling. Man unterscheidet prinzipiell
zwischen Broadcast- und Media-on-Demand-Übertragungen.
- Bei Live Broadcasting werden Videos und Tonspuren direkt bei Aufnahme
an den Server übertragen, welcher sie an die Benutzer mittels Multicast
weiterleitet. Die Dauer eines so übertragenen Videos muss im Vorhinein
nicht unbedingt feststehen. Bei Live Broadcasting muss eine große
Bandbreite zur Verfügung stehen, da die einzelnen Benutzer etwa
zeitgleich zuschalten. Grundsätzlich gibt es bei Live Broadcasting
keine VCR-Kontrolle, bei einigen wird allerdings Pause und Resume
angeboten.
- Im Gegensatz dazu wird bei Media-on-Demand die Übertragung vom
Benutzer angestoßen, indem er einen Film aus einer Liste auswählt.
Oftmals wird Media-on-Demand per Unicast übertragen. Der Vorteil
dieser Übertragung stellt die einfache Implementierung dar, Probleme
können allerdings durch die hohe Bandbreitenanforderung entstehen.
Um diese zu reduzieren besteht die Möglichkeit die Medien mittels
Multicast zu übertragen. Problematisch können allerdings eine erhöhte
Start-up Verzögerung und die VCR-Kontrolle sein. Genauere Techniken
der Multicastübertragung werden später näher erläutert.
Arten von Media on Demand
Im folgenden werden verschiedene Arten von Media-on-Demand erläutert:
- True Media on Demand (TMoD441):
- Bei TMoD441
wird jede eintreffende Anfrage gesondert behandelt. Dadurch erhält
der Benutzer die komplette Kontrolle während der Übertragung und
jede Möglichkeit der VCR-Kontrolle. Eine solche Unicast-Übertragung
erfordert allerdings hohe Bandbreiten.
- Near Media on Demand (NMoD442:
- Bei NMoD442
werden Benutzer, die um das selbe Medium anfragen, in eine Gruppe
gefasst und mittels Multicast bedient. Die Startup Verzögerung kann
sich dadurch im Vergleich zu TMoD erhöhen, außerdem ist die VCR-Kontrolle
nur in einem beschränkten Maße verfügbar.
- Quasi Media on Demand (QMoD443):
- Die Übertragung eines Streams wird bei QMoD443
gestartet, sobald mindestens eine bestimmte Anzahl von Anfragen
verfügbar ist. Der Benutzer hat nur die Wahl, an einer solchen Übertragung
teilzunehmen und besitzt keinerlei interaktive Kontrolle während
der Übertragung.
Bei Medienserver-Architekturen unterscheidet man grundsätzlich zwischen
Client-Pull und Server-Push Architekturen.
In Client-Pull Architekturen kann der Benutzer die volle interaktive
Kontrolle während der Übertragung ausüben. Der Benutzer sendet für
jedes benötigte Paket eine Anfrage an den Server, wodurch eine ständige
bidirektionale Kommunikation gegeben ist (z.B. TMoD441).
Bei Server-Push Architekturen sendet der Benutzer eine Anfrage z.B.
für einen Film an den Server, welcher ohne weitere Anstöße periodisch
Daten an den Benutzer überträgt. Dadurch verliert dieser allerdings
auch jegliche Kontrolle über die Übertragung (QMoD443).
VCR-Kontrolloperationen
VCR-Kontrolloperationen wurden schon in den vorhergehenden Folien
erwähnt und werden hier nun genauer betrachtet.
Die Implementierung von Pausen- und Wiederaufnahmeanforderungen ist
ziemlich einfach. Es muss dafür gesorgt werden, dass bei Wiederaufnahme
des Films genügend Bandbreite zur Verfügung steht. Dies wird mit einer
Kanalstrategie für unvorhergesehene Fälle gelöst. Der Server stellt
eine kleine Anzahl (Kontingent) von statistisch geteilten Zufallskanälen
ausschließlich für unvorhergesehene Aktionen wie Wiederaufnahme zur
Verfügung. Für andere Anfragen wird Platz aus dem restlichen Kontingent
reserviert.
Für die VCR-Kontrolloperationen Fast-Forward und Fast-Backward werden
spezielle Dateien, welche z.B. jedes 10. Frame enthalten, an den Benutzer
übertragen. Diese Methode verschwendet allerdings Speicherplatz.
Fast Playback bringt gesteigerte Implementierungskomplexität beim
Benutzer mit sich, außerdem verschwendet es Netzwerkbandbreite.
Multicast Techniken
Die Effizienz von Multicast wird durch eine Reihe von speziellen
Techniken garantiert, im folgenden erläutern wir
Batching, Chaining, Piggybacking und Patching.
- Batching ist ein Ansatz um Plattenbandbreite
in Medien-Servern zu sparen, indem temporale Zyklen, sog. Batching-Fenster
der Größe p, definiert werden. Die Grösse p muss so definiert werden,
dass die daraus resultierende Verzögerung kleiner als die maximal
tolerierbare Startup Verzögerung der Benutzer ist. In einem solchen
Zyklus werden alle eintreffenden Anfragen für den selben Strom zunächst
gesammelt. Am Ende des Zyklus werden diese Anfragen von derselben
Datei und demselben Buffer bedient. Die Anzahl der zeitlichen Batching-Fenster
ist allerdings limitiert. Ein weiteres Problem stellt die Verzögerung
dar, da frühe Anfragen ebenso wie später einlangende gleichzeitig
erst am Ende eines Batching-Fensters bedient werden können.
- Chaining bietet hier einen etwas
anderen Ansatz. Der vom Server gesendete Stream wird von den Benutzern
an nachgeschaltete Benutzer mittels Multicast übertragen. Dadurch
bilden die Benutzer eine Pipeline. Jeder von ihnen speichert die
Daten lokal in einem Cache. Spätere Anfragen können danach auf die
gespeicherten Daten zugreifen, wodurch die Verzögerung im Vergleich
zum Batching minimiert wird. Zusätzlich wirkt sich dieses Konzept
positiv auf die benötigte Server-Bandbreite aus, diese wird durch
Einsatz der Benutzerstationen wesentlich reduziert.
- Beim dynamischen Batching werden
die Anfragen so bald bedient, wie ein Strom verfügbar wird. Hier
gibt es zwei Auswahlstrategien, First-Come-First-Served und die
max Queuelänge. First-Come-First-Served ist fair, es bearbeitet
die Anfragen nach dem Zeitpunkt ihres Eintreffens. Bei MQL besitzt
jedes Video eine eigene Schlange, jenes mit der größten Schlangenlänge
wird bearbeitet. Das kann allerdings dazu führen, dass weniger gefragte
Videos lange warten müssen, wodurch sich die Absagewahrscheinlichkeit
der Benutzer für diese Videos steigert.
- Bei Piggybacking werden Ströme,
die den selben Inhalt liefern, zusammengeführt. Es ist keine Verwendung
von Batching-Fenstern notwendig. Ein Strom, der kurz nach einem
anderen Strom desselben Inhalts aufgerufen wird, wird mit ersterem
während der Übertragung vereint. Es erfolgt die Zunahme der Geschwindigkeit
des späteren Stroms und oder eine Abnahme der Geschwindigkeit des
früheren Stroms, bis sie vereinigt werden.
- Mit Hilfe von Patching kann der
Server entlastet werden. Beim Patching wird die Videoübertragung
über Multicast gestartet, wenn der erste Benutzer das Video anfordert.
Es wird Multicast statt Unicast verwendet, in der Hoffnung, dass
weitere Benutzer dieses Video anfordern. Das Video wird von Anfang
bis Ende übertragen. Fordert ein anderer Benutzer dasselbe Video
innerhalb eines gewissen Zeitintervalls an, so wird keine neue Videoübertragung
gestartet, sondern der Benutzer erhält die notwendigen Informationen
um an dem existierenden Videostream teilzunehmen. Zusätzlich bekommt
er einen so genannten Patchstream, in dem die Daten, die er am Anfang
verpasst hat, enthalten sind. Durch einen Buffer beim Client werden
die Daten in der korrekten Reihenfolge abgespielt. Es gibt eine
optimale Zeit für dieses Zeitintervall, dass größtenteils von der
Häufigkeit der Anforderungen abhängt. Eine Anforderung, die eintrifft
nachdem das Zeitintervall abgelaufen ist, startet einen neuen Videostrom.
Prozess Scheduling
1
Auto
- Periodische Prozesse spielen Filme ab
- Frame-Raten und CPU352-Zeit
ist unterschiedlich für jeden Prozess
- Zwei Arten von Scheduling
- preemtives Scheduling
- erhöhter Aufwand für Prozessverwaltung
- viele Prozesswechsel
- nicht-preemtives Scheduling
Ratenmonotones Scheduling
- Wird für Prozesse verwendet die folgenden Bedingungen genügen:
- Jeder periodische Prozess muss innerhalb seiner Periode beendet
werden
- Kein Prozess ist abhängig von einem anderen
- Jeder Prozess benötigt die selbe CPU352-Zeit
bei jedem Durchlauf
- Nicht periodische Prozesse haben keine Deadline
- Prozesszuteilung tritt sofort auf
- Planbarkeit:
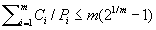
- CPU352
Auslastung: m = 3: 0,780; m->∞:->ln2(0,693)
- m Anzahl der zu verarbeitenden Prozesse,
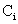 Bearbeitungszeit für Prozess i,
Bearbeitungszeit für Prozess i, 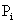 Periodendauer für Prozess i
Periodendauer für Prozess i
Earliest Deadline First Scheduling
- Dynamischer Algorithmus
- Der Prozess mit der jeweils kürzesten Deadline erhält Zugang
zur CPU352
- Bei Eintreffen eines neuen Prozesses wird sofort ein neuer
Plan erstellt
- Weder Periodozität, noch konstante Laufzeit
- EDF439
kann eine Prozessorauslastung von 100% erreichen
2
Auto
Prozess Scheduling bedeutet, die CPU352
unter den verschiedenen Prozessen möglichst effizient aufzuteilen.
Es existieren verschiedene Scheduling-Strategien, wie z.B. Round Robin,
Prioritäts-Scheduling oder Shortest-Job-First. Grundsätzlich hat jeder
Prozess unterschiedliche Frame-Raten und CPU352-Zeiten.
Grundsätzlich unterscheidet man zwei Arten von Scheduling, preemtives
und nicht-preemtives Scheduling.
Beim preemtiven Scheduling wird dem gerade aktiven Prozess die CPU352
entzogen, wenn ein Prozess mit höherer Priorität eine Anforderung
stellt. Dadurch entsteht ein erhöhter Aufwand für die Prozessverwaltung
und es gibt mehr Prozesswechsel.
Beim nicht preemtiven Scheduling werden aktive Prozesse nicht unterbrochen,
wodurch ein geringerer Aufwand für Prozesswechsel entsteht. Nicht
preemtives Scheduling ist in der Regel vorzuziehen, wenn die Ausführungszeiten
kurz sind, wie das grundsätzlich bei Multimedia der Fall ist.
Die Entscheidung, wann welchem Prozess die CPU352
zugeteilt wird, fällt der Scheduler, wie schon oben erwähnt, nach
verschiedenen Strategien. Auf den folgenden Folien werden zwei Verfahren:
ratenmonotones Scheduling und Earliest
Deadline First (EDF439)-Scheduling
vorgestellt, welche in Medien-Servern oft eingesetzt werden.
Ratenmonotones Scheduling
Beim ratenmonotonen Scheduling handelt
es sich um einen optimalen, mit statischen Prioritäten arbeitenden,
Algorithmus für unterbrechbare und periodische Prozesse. Statische
Algorithmen planen Datenströme einmal nach ihrer Rate ein. Während
der Laufzeit müssen keine weiteren Planungsentscheidungen mehr getroffen
werden.
Die folgenden fünf Annahmen beschreiben die notwendigen Voraussetzungen,
um den Algorithmus anwenden zu können:
- Alle zeitkritischen Prozesse treten periodisch auf, d.h. zwischen
zwei aufeinanderfolgenden Prozessen liegt immer ein konstantes Zeitintervall.
- Die Bearbeitung eines Prozesses muss abgeschlossen sein, bevor
der nächste Prozess zur Bearbeitung bereit wird. Dies bezieht sich
immer auf die Verarbeitung von Daten eines Datenstroms. Die Frist
liegt somit jeweils am Ende der Periodendauer.
- Unterschiedliche Prozesse sind voneinander unabhängig, d.h., die
Bearbeitung eines Prozesses hängt nicht vom Zustand eines anderen
zeitkritischen Prozesses ab.
- Die Bearbeitungszeit durch die CPU352
ist in jeder Periode gleich und variiert während der Laufzeit nicht.
- Alle nicht-periodischen Prozesse im System sind nicht zeitkritisch.
Der ratenmonotone Algorithmus weist aufgrund seiner Rate jedem Prozess
eine statische Priorität zu. Diese Priorität behält er für den Rest
seiner Laufzeit. Die Priorität gibt die relative Wichtigkeit eines
Prozesses im Vergleich zu den anderen an. Dabei erhält der Prozess
mit der kürzesten Periode (d.h. mit der größten Rate) die höchste
Priorität.
Die CPU352-Auslastung
ist beim ratenmonotonen Algorithmus beschränkt und hängt von den einzelnen
Prozessen mit ihren jeweiligen Bearbeitungszeiten und Perioden ab.
Die CPU352-Auslastung
muss folgender Bedingung genügen, damit Planbarkeit (Schedulability)
garantiert werden kann (m Anzahl der zu verarbeitenden Prozesse,
Bearbeitungszeit für Prozess i,
Periodendauer für Prozess i):
Ist m = 3 so liegt die maximale CPU352-Auslastung
bei 0,780.
Zur Bestimmung der Einplanbarkeit eines Prozesses genügt es, zu überprüfen,
ob die CPU352-Auslastung
kleiner oder gleich der vorgegebenen Obergrenze für die vorhandenen
und Periodendauern ist. In den meisten Systemen wird dies auf einen
Vergleich mit dem Wert ln2 zurückgeführt.
Earliest Deadline First (EDF)-Scheduling
Beim EDF439-Scheduling
gehen wir davon aus, dass jeder Prozess fest vorgegebene Zeitpunkte
("Deadlines") besitzt, zu denen die Bearbeitungen seiner
einzelnen Ausführungsblöcke jeweils abgeschlossen sein müssen.Vor
allem bei Multimediaanwendungen ist das Ergebnis eines Prozesses möglicherweise
nicht mehr zu gebrauchen, wenn es zu spät eintrifft.
Earliest Deadline First sucht zu jedem Planungszeitpunkt aus der
Menge der Prozesse, die zur Bearbeitung anstehen und noch nicht vollständig
bearbeitet wurden, den Prozess mit der kürzesten Deadline aus. Der
ausgewählte Prozess erhält Zugang zur CPU352.
Bei der Ankunft eines neuen Prozesses ist durch den Algorithmus sofort
ein neuer Plan zu erstellen, d.h., der zu diesem Zeitpunkt bearbeitete
Prozess wird unterbrochen und der neue Prozess nach seiner Frist eingeplant.
Dieser neue Prozess erhält Zugang zum Betriebsmittel, wenn seine Frist
vor der des unterbrochenen Prozesses abläuft. Der unterbrochene Prozess
nimmt seine Bearbeitung auf, sobald er unter allen anstehenden Prozessen
derjenige ist, dessen Frist am nächsten liegt. EDF439
ist nicht nur ein optimaler Planungsalgorithmus für periodische Prozesse,
sondern auch für Prozesse mit unregelmäßigen oder unbekannten Ankunftszeiten,
Fristen und Bearbeitungszeiten. Dieser Algorithmus kann eine Prozessorauslastung
von 100% erreichen, weil alle Prozesse dynamisch nach ihren Fristen
eingeplant werden.
Bibliographie
2
Auto
Ste00
DA99
|